



 本文介绍了PyTorch中require_grad的功能,如何控制张量的梯度需求,以及如何使用计算图、buffer、retain_graph、grad_fn和hook进行高效的梯度计算和管理。
本文介绍了PyTorch中require_grad的功能,如何控制张量的梯度需求,以及如何使用计算图、buffer、retain_graph、grad_fn和hook进行高效的梯度计算和管理。
3.2.1 require_grad
1. 创建tensor时,默认是不require_grad的,需要加上类似True的语句;
2. y.backward(t.ones(y.size())) # gradient形状与y一致
3. 依赖于需要求导变量的变量,默认也是需要求导的
4. 对于不需要求导的地方,可以关闭,由此可提升运算速度:
with t.no_grad():
x = t.ones(1)
w = t.rand(1, requires_grad = True)
y = x * w # y依赖于w和x,虽然w.requires_grad = True,但是y的requires_grad依旧为False
x.requires_grad, w.requires_grad, y.requires_grad
t.set_grad_enabled(False)
x = t.ones(1)
w = t.rand(1, requires_grad = True)
y = x * w # y依赖于w和x,虽然w.requires_grad = True,但是y的requires_grad依旧为False
x.requires_grad, w.requires_grad, y.requires_grad
t.set_grad_enabled(True) # 恢复默认配置
5. 若希望修改tensor的数值,但是又不希望被Autograd记录,那么可以对tensor.data进行操作。
a = t.ones(3,4,requires_grad=True)
b = t.ones(3,4,requires_grad=True)
c = a * b
a.data # 还是一个tensor
a.data.requires_grad # 但是已经是独立于计算图之外,即复制了相同的数据,但是不会自动求导
d = a.data.sigmoid_() # sigmoid_ 是个inplace操作,会修改a自身的值
d.requires_grad # False
3.2.2 计算图
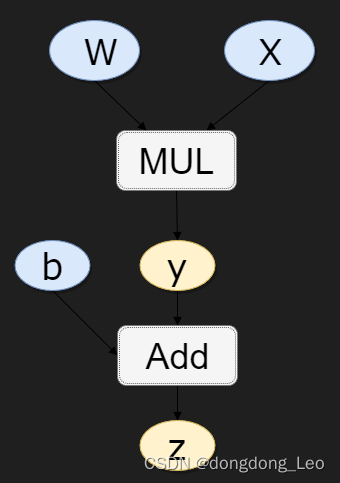
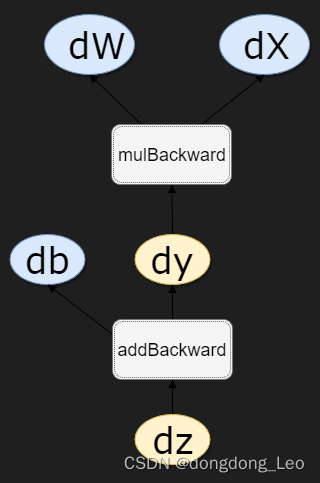
1. grad_fn可用来查看Variable的反向传播函数,如z=y+b,y=wx:
(next_functions保存grad_fn的输入,是一个tuple,tuple的元素也是Function)
z.grad_fn #<MulBackward0 at 0x245c0e27bb0>
z.grad_fn.next_functions #((<MulBackward0 at 0x245c0e27bb0>, 0), (<AccumulateGrad at 0x245c0e27dc0>, 0))
2. 计算w的梯度的时候,需要用到x的数值,这些数值在前向过程中会保存成buffer,在计算完梯度之后会自动清空。为了能够多次反向传播需要指定`retain_graph`来保留这些buffer;如此一来,多次反向传播的时候,梯度会累加。
z.backward(retain_graph=True)
w.grad
z.backward()
w.grad
3. 在反向传播过程中非叶子节点的导数计算完之后即被清空。若想查看这些变量的梯度,有两种方法:使用autograd.grad函数;使用hook
x = t.ones(3, requires_grad=True)
w = t.rand(3, requires_grad=True)
y = x * w
z = y.sum()
z.backward()
(x.grad, w.grad, y.grad) #(tensor([0.1703, 0.0842, 0.3761]), tensor([1., 1., 1.]), None)
# 第一种方法:使用grad获取中间变量的梯度
x = t.ones(3, requires_grad=True)
w = t.rand(3, requires_grad=True)
y = x * w
z = y.sum()
t.autograd.grad(z, y) # z对y的梯度,隐式调用backward()
# 第二种方法:使用hook
# hook是一个函数,输入是梯度,不应该有返回值
def variable_hook(grad):
print('y的梯度:',grad)
x = t.ones(3, requires_grad=True)
w = t.rand(3, requires_grad=True)
y = x * w
# 注册hook
hook_handle = y.register_hook(variable_hook)
z = y.sum()
z.backward()
# 除非你每次都要用hook,否则用完之后记得移除hook
hook_handle.remove()
4. Variable中的grad属性、backward函数的grad_variable参数:
(1)Variable x的梯度是目标函数f(x)对x的梯度,形状与x一致
(2)y.backward(grad_variables)中的grad_variables相当于链式法则中的中间微分(如z对x求导,y是中间的,那么grad_variables是z对y的导数)。z.backward() = y.backward(grad_y) 。
x = t.arange(0,3, requires_grad=True,dtype=t.float)
y = x**2 + x*2
z = y.sum()
z.backward() # 从z开始反向传播
x.grad
y_gradient = t.Tensor([1,1,1]) # dz/dy
y.backward(y_gradient) #从y开始反向传播
x.grad


















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









