







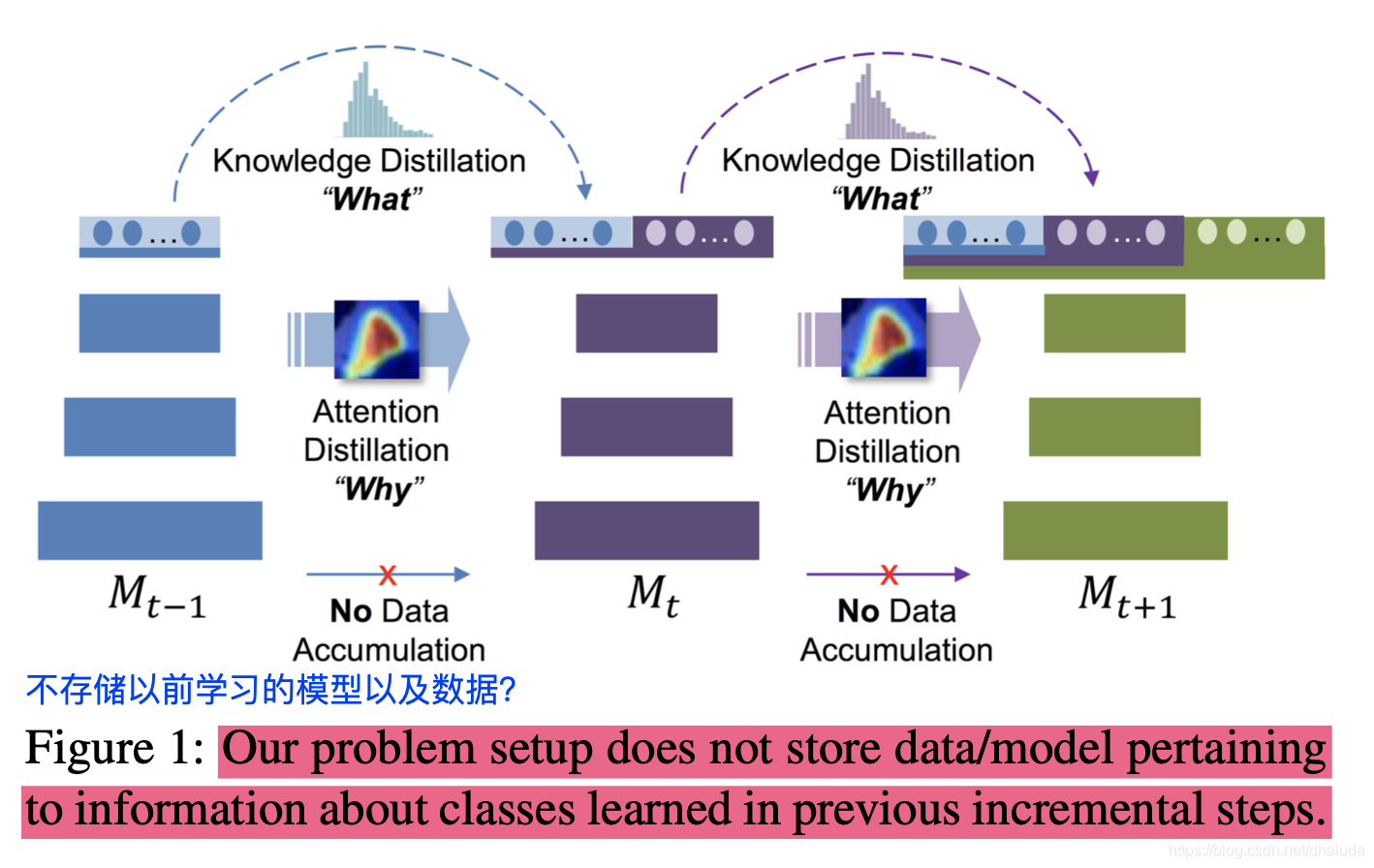
 本文介绍了一种新的增量学习方法,通过引入AttentionDistillationLoss,解决了传统KnowledgeDistillationLoss在注意力区域转移的问题,使CNN在增量学习过程中能更好地保留类别特征。
本文介绍了一种新的增量学习方法,通过引入AttentionDistillationLoss,解决了传统KnowledgeDistillationLoss在注意力区域转移的问题,使CNN在增量学习过程中能更好地保留类别特征。
前言
我将看过的增量学习论文建了一个github库,方便各位阅读,地址
main work
提出了Attention distillation loss,与knowledge distillation loss混合使用训练神经网络,在不需examplar的前提下达到较好的准确率。
motivation
CNN准确定位到与类别相关的区域后,提取的特征才更具有区分性,常见的distiilation loss存在一个问题,当CNN对某类别的注意力区域发生转移后,其大小并不会发生太大的改变,如下图:

注意力区域发生转移,很有可能导致CNN无法提取到足够具有辨识度的特征,如上图所示,挂盘电话的有区分度的区域为挂盘号码,挂盘电话下方的提示符并不能显示这是一个挂盘电话,分类器很有可能把这张图片划分其他类别,而常见的knowledge distillation loss对此并不敏感,因此提出了attention distillation loss。
在新类别首次训练时,CNN往往能定位到与类别相关的区域,通过attention distillation loss,希望在以后增量的过程中,CNN能保留类别首次训练时,定位类别相关区域的能力。
knowledge distillation loss只能解释一张图片是什么,与之相似的类别是什么,但是无法解释为什么它们会相似,而attention distillation loss能很好的解释why(例如猫和狗的耳朵很像等等),attention distillation loss的粒度比knowledge distillation loss更细,如下图:
method
符号约定
| 符号名 | 含义 |
|---|---|
| M t − 1 M_{t-1} Mt−1 | 第t-1轮增量的模型 |
| M t M_{t} Mt | 第t轮增量的模型 |
| L D L_D LD | knowledge distillation loss |
| L A D L_{AD} LAD | attention distillation loss |
| L C L_C LC | classification loss |
总体流程如下:
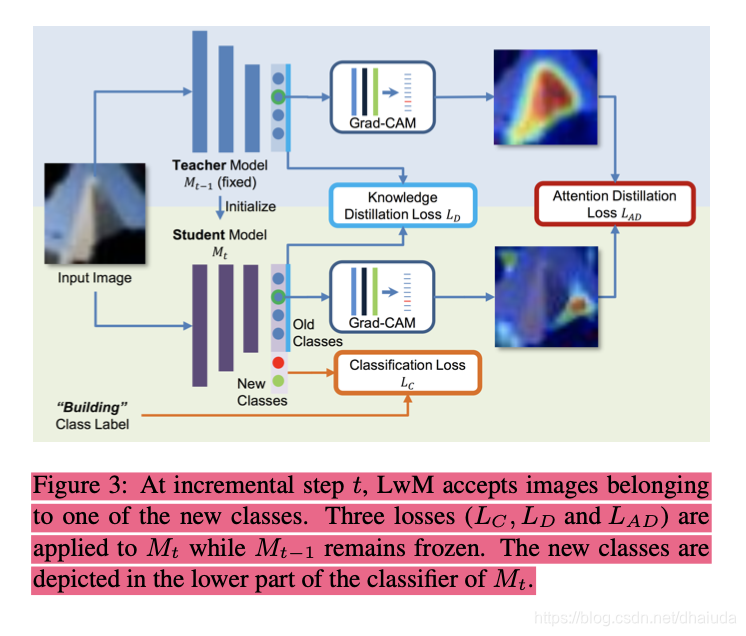
训练 M t M_t Mt时,新类别的每一张图片分别输入到 M t − 1 M_{t-1} Mt−1与 M t M_t Mt中,选择 M t M_t Mt中旧类别值最高的分支,利用grad-cam对其进行可视化,得到一张注明了attention区域的图片,接着利用这两张图片构建attention distillation loss,具体而言,对第 i i i张图片,第 c c c个类别,grad-cam可视化的结果记为

vector表示向量化,
L
A
D
L_{AD}
LAD的定义如下:
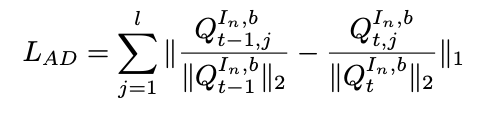
相似度的定义很多,论文比较了L1距离与L2距离后,发现L1距离效果更佳。
论文并没有解释为什么选择 M t M_t Mt旧类别分支最大的值进行可视化,这点很迷
最终的loss定义为:
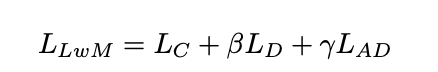
β
\beta
β与
γ
\gamma
γ为超参数,取值0到1之间,需注意的是,LwF不会使用examplar
实验
此部分只给出较为有趣的部分,更多实验结果可以查看原论文
baseline:LwF-MC、C(只使用classification loss)
论文给出了四次增量模型的可视化图,结果如下:
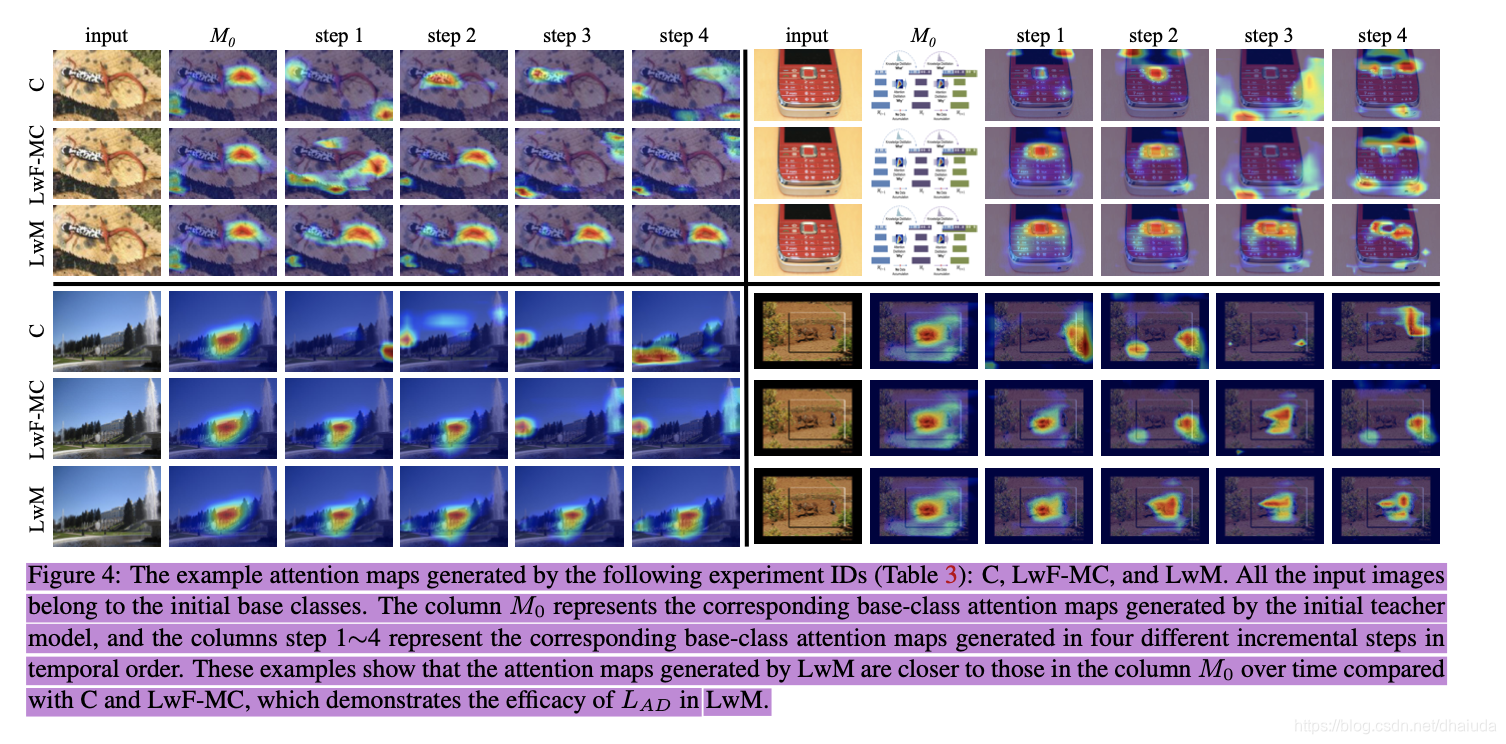
可以看到,使用attention distillation loss的LwM,在多次增量后,注意力区域并没有发生太多改变

















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









