




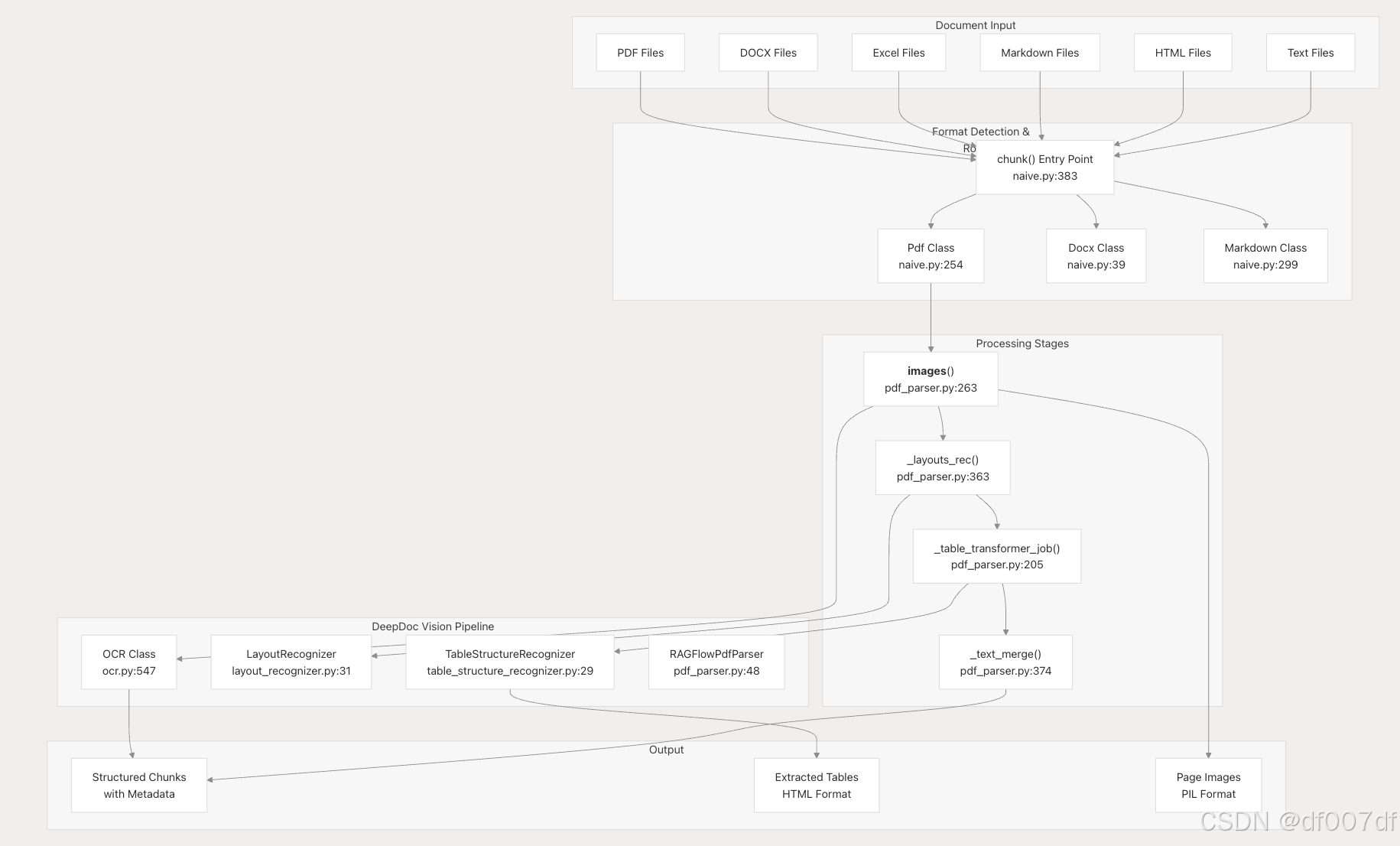
系统概述
文档解析和 OCR 系统提供多格式文档支持,并具有基于视觉的分析功能。它由几个关键组件组成:
- DeepDoc 视觉系统 :用于布局分析、表格检测和 OCR 的高级计算机视觉模型
- 多格式解析器 :支持 PDF、DOCX、Excel、Markdown、HTML 和纯文本
- OCR 引擎 :支持多种语言的文本识别
- 版面识别 :自动识别文档结构,包括标题、表格、图形
OCR 引擎架构
OCR 引擎提供文本检测和识别功能,并支持 GPU 加速。它由两个主要组件组成:文本检测和文本识别。
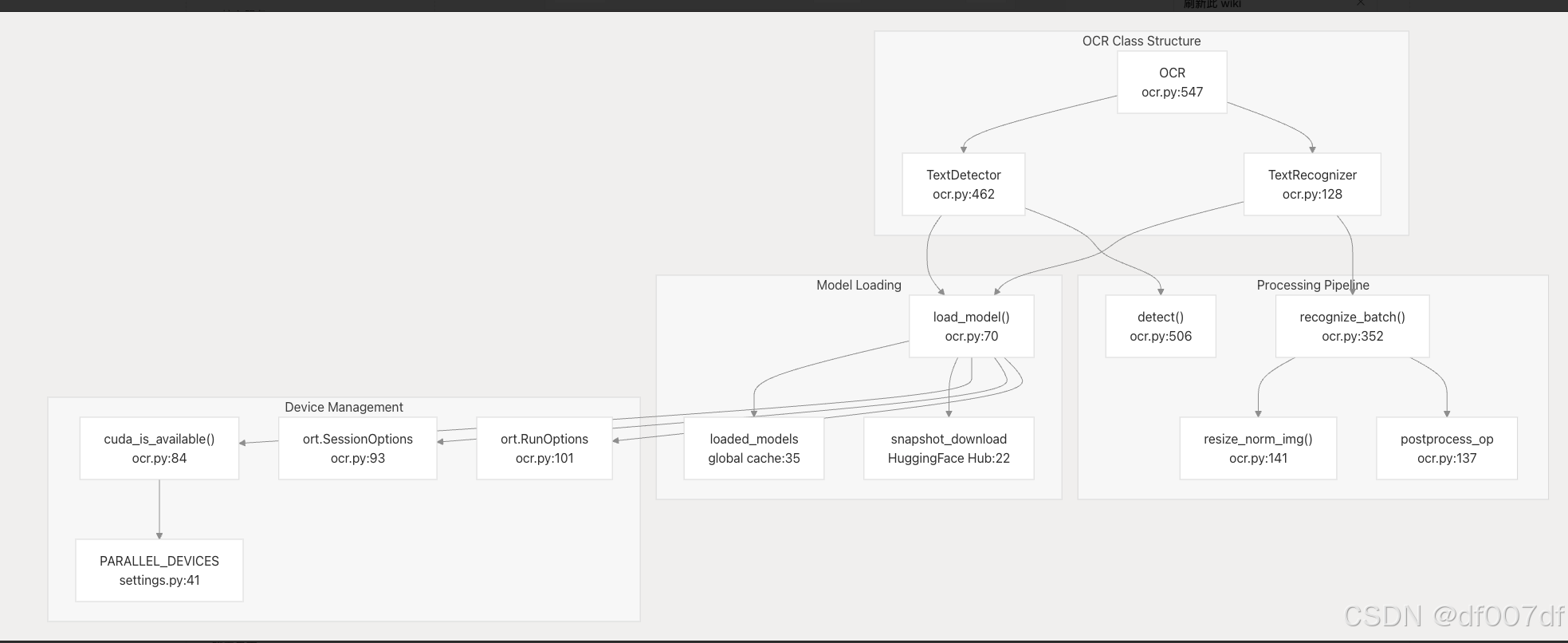
OCR 引擎支持多种图像预处理方法,可以处理批处理以提高性能:
文档格式支持
RAGFlow 通过专门的解析器类支持多种文档格式,每种解析器类都针对特定文档特征进行了优化:
| 格式 | 解析器类 | 主要特点 | 视力支持 |
|---|---|---|---|
| PDF 下载 (naïve.py:254) | 布局分析、表格检测、OCR | 是的 | |
| DOCX | Docx (naïve.py:39) | 图像提取、表格解析、 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2185
2185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











