




系统架构
LLM 集成概述
型号类型分类
| 型号类型 | 主接口 | 关键方法 | 使用案例 |
|---|---|---|---|
| 聊天 | Base.chat()、Base.chat_streamly() | 聊天()、chat_with_tools()、bind_tools() | 对话式 AI、RAG 生成 |
| 嵌入 | Base.encode()、Base.encode_queries() | 编码()、encode_queries() | 文档矢量化、语义搜索 |
| 重新排名 | Base.similarity() | similarity() | 搜索结果重新排名 |
| 图片2文本 | Base.describe()、Base.describe_with_prompt() | 描述()、 聊天() | 文档 OCR、图像分析 |
| 语音2文本 | Base.transcription() | transcription() | 音频处理、语音输入 |
| TTS | Base.tts() | tts() | 语音输出、音频生成 |
工厂模式实现
动态模型加载系统
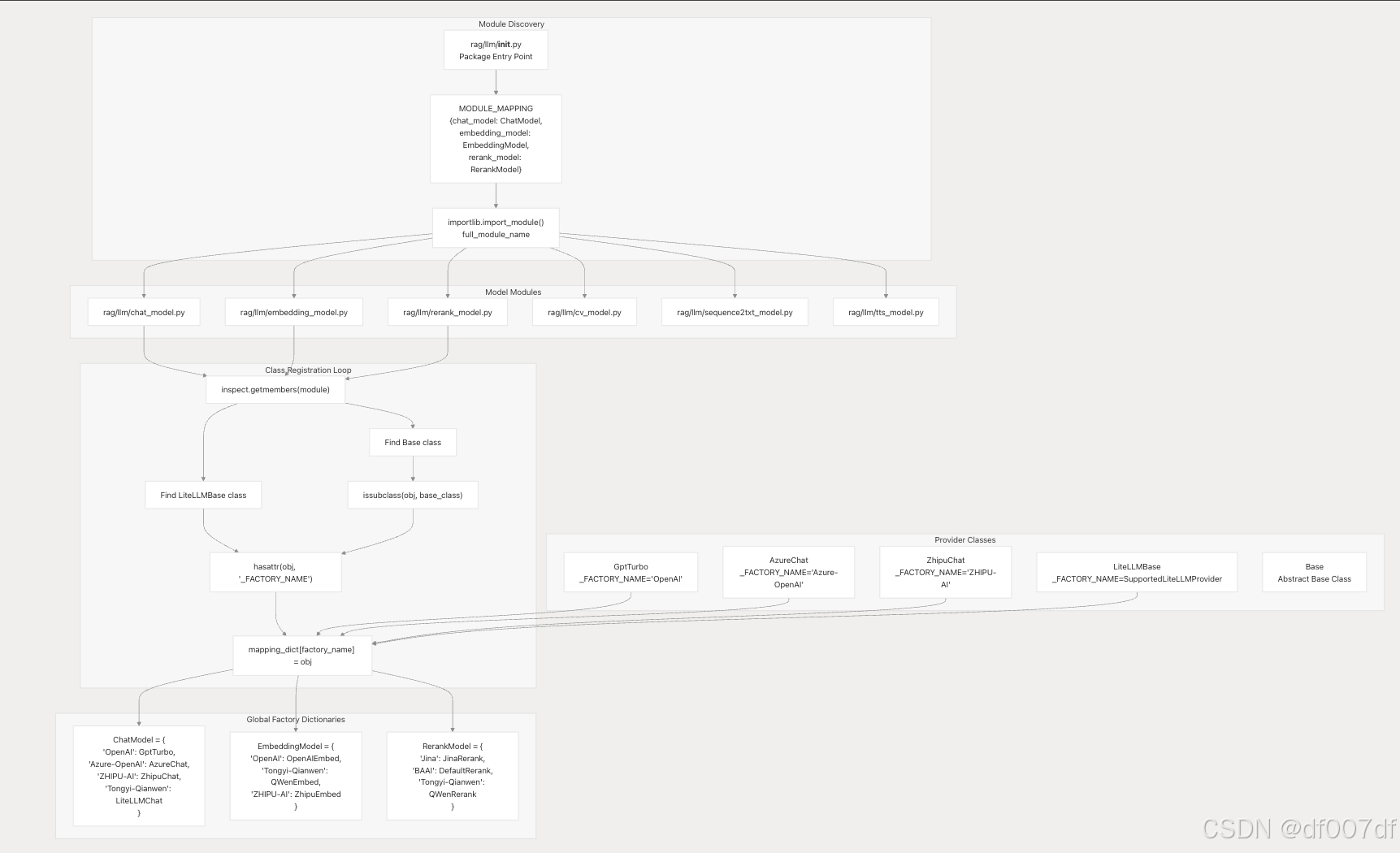
聊天模型类层次结构

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3220
3220

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











