




配置架构概述
RAGFlow 的配置系统通过多层运行,为不同的部署场景和运行时要求提供了灵活性。
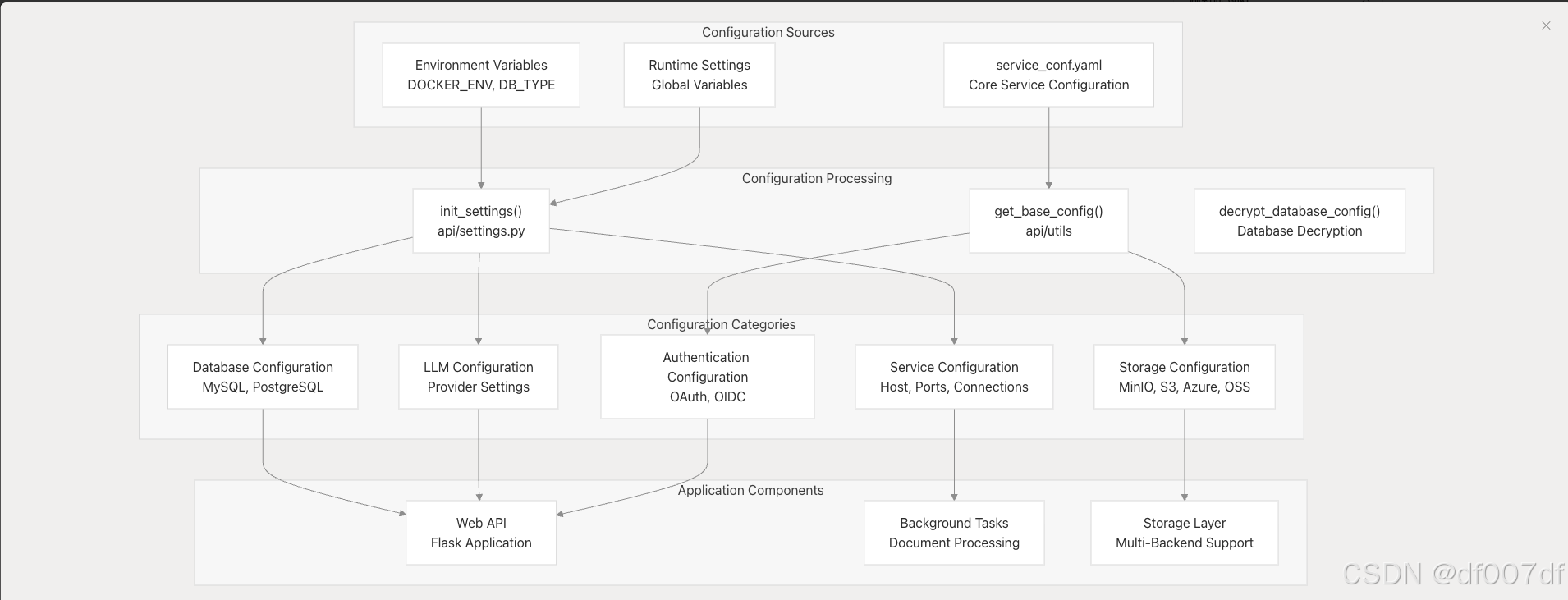
服务配置系统
主配置在 service_conf.yaml 中定义,它为所有核心服务及其连接参数提供结构化设置。
核心服务配置结构
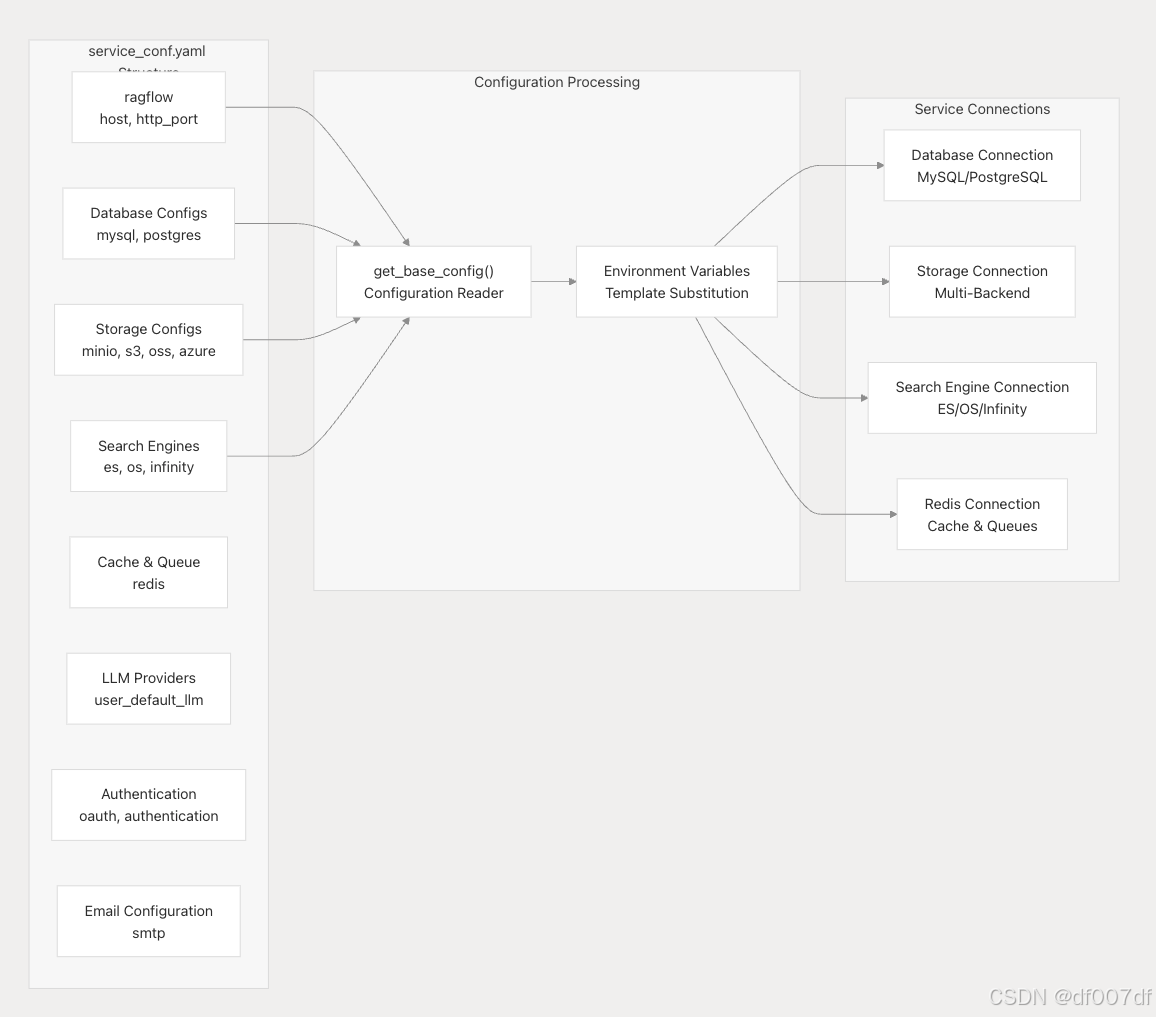
| 配置部分 | 目的 | 按键设置 |
|---|---|---|
| ragflow | 核心服务设置 | 主机 , http_port |
| mysql/postgres | 数据库连接 | 主机 、 端口 、 用户 、 密码 、 名称 |
| minio/s3/ 作系统 /azure | 对象存储 | 连接凭据和终结点 |
| ES/ 作系统 / 无穷大 | 搜索引擎 | 主机、身份验证、数据库名称 |
| redis | 缓存和任务队列 | 主机、端口、数据库、密码 |
| user_default_llm | LLM 提供 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











