






仅供自己学习
目录
一.什么是爬虫
通俗理解:
一个模拟人类请求网站行为的程序。 可以请求网页,并把数据抓取下来,然后用一定规则进行分析。
通用爬虫:类似于百度搜索, 将互联网上的网页 下载到本地,形成一个互联网内容的镜像备份。
聚焦爬虫(需求):会对内容进行筛选,是面向特定去求的一种网络爬虫程序。
准备工具:
python3.6
pycharm
二HTTP协议的介绍
什么是http和https协议:
http协议:中文意思是超文本传输协议。服务端口是80端口
https协议:是http协议的加密版本,在http下加入SSL层。服务端口是443端口。
在浏览器中发送http请求的过程:

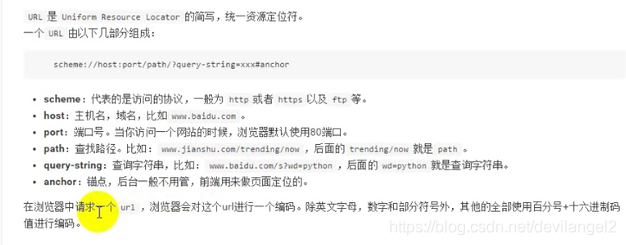
url详解:
统一资源定位符
一个域名映射一个IP地址
现在的url已经可以自动把端口加上了
三.抓包工具使用的网络请求
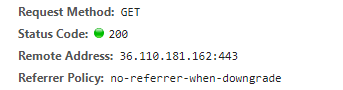
常用的网页请求方法:

请求头常见参数:
2.referer:记录的是从哪个页面过来的。
3.cookie:判断是不是一个人,(我只记得清垃圾的时候清除过。)

常见的状态码:

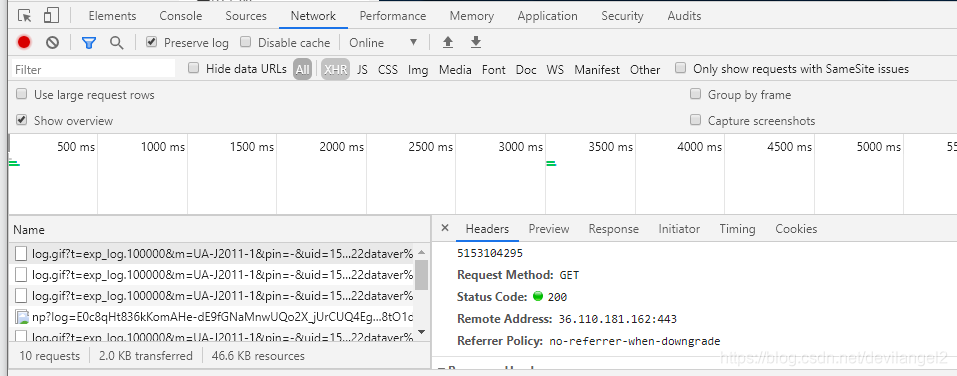
Chorme抓包工具:

















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









