






 本文深入讲解了BeautifulSoup4的使用方法,包括与lxml的对比、解析器的选择、find_all和select方法的应用,以及如何获取标签、属性和文本信息。
本文深入讲解了BeautifulSoup4的使用方法,包括与lxml的对比、解析器的选择、find_all和select方法的应用,以及如何获取标签、属性和文本信息。
目录
1.BeautifulSoup4
1.与lxml一样也是HTML/XML的解析器
2.B会载入整个文档,解析整个DOM树,lxml是局部,所以B的时间内存开销大。
3.操作简单。

几大解析工具对比

from bs4 import BeautifulSoup
html=""
bs=BeautifulSoup(html,"lxml")#“lxml”为解析器,还有三种解析器如下
print(bs.prettify())
#会打印出比较规范的格式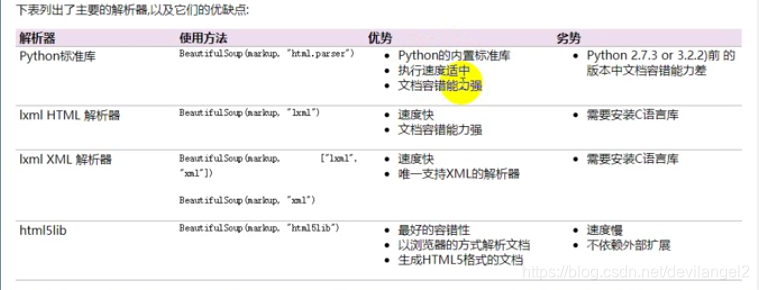
BeautifulSoup的常用方法
(1)find_all
from bs4 import BeautifulSoup
html=""
bs=BeautifulSoup(html,"lxml")
print(bs.prettify())
#会打印出比较规范的格式
#1.找到所有的tr标签
trs=bs.find_all("tr")
for tr in trs:
print(tr)#
#1.找到第2个tr标签
trs=bs.find_all("tr",limit=2)[1]#limit是遍历前两个,find_all返回的列表,列表中每个元素是以字符串的形式显示,但实际上是Tag
#3.获取所有class等于even的tr标签
trs=bs.find_all("tr",class_="even")#class后面加下划线是为了与关键字class区别
trs=bs.find_all("tr",attrs={"class":"even"})#也可以
#4.获取所有a标签的href属性
aList=bs.find_all("a")
for a in aList:
#1.通过列表获得属性
href=a["href"]
#2.通过attrs获取
href=a.attrs['href']
#5.获取文本信息
trs=bs.find_all("tr")
for tr in trs:
tds=tr.find_all("td")
position=tds[0].string
time=tds[1].string
#还可以
trs=bs.find_all("tr")
for tr in trs:
infom=list(tr.stripped_strings)

(2)select
使用css选择器语法
#1.找到所有的tr标签
trs=bs.select('tr')
for tr in trs:
print(tr)
#1.找到第2个tr标签
trs=bs.select("tr")[1]#limit是遍历前两个,find_all返回的列表,列表中每个元素是以字符串的形式显示,但实际上是Tag
#3.获取所有class等于even的tr标签
trs=bs.select("tr.even")
#或者
trs=bs.select("tr[class='even']")
for tr in trs:
print(tr)
#4.获取所有a标签的href属性
aList=bs.select("a")
for a in aList:
#1.通过列表获得属性
href=a["href"]
#2.通过attrs获取
# href=a.attrs['href']
#5.获取文本信息
trs=bs.select("tr")
for tr in trs:
# tds=tr.find_all("td")
# position=tds[0].string
# time=tds[1].string
inform=list(tr.stripped_strings)

















 1451
1451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









