




作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
我们上一章介绍了Docker基本情况,目前在规模较大的容器集群基本都是Kubernetes,但是Kubernetes涉及的东西和概念确实是太多了,而且随着版本迭代功能在还增加,笔者有些功能也确实没用过,所以只能按照我自己的理解来讲解。
我们上一小节虽然介绍了如何续期,但是有没有什么方法可以在创建集群的时候就提供更长的证书时间呢?很遗憾,kubeadm并没有给我们提供这样的参数,这个计算逻辑在Kubeadm的源代码里面,所以只能修改源代码来实现。下面的方法可供参考,里面会涉及到部分未讲解的知识可以忽略不记。
准备工作
1.服务器安装go环境
go环境需要大于1.17,否则会报错,我这里用的是1.23
cd /usr/local
wget https://golang.google.cn/dl/go1.23.4.linux-amd64.tar.gz
tar xvf go1.23.4.linux-amd64.tar.gzvi /etc/profile
#添加下面2行到文件末尾
export PATH=$PATH:/usr/local/go/bin
export GOPATH=$HOME/go
#让环境变量生效
source /etc/profile2.服务器安装git命令
yum -y install git修改代码
1.下载代码
git clone --depth 1 --branch v1.23.12 https://github.com/kubernetes/kubernetes.git
cd kubernetes2.修改ca证书到100年
#把代码里面的*10 换*100
vi ./staging/src/k8s.io/client-go/util/cert/cert.go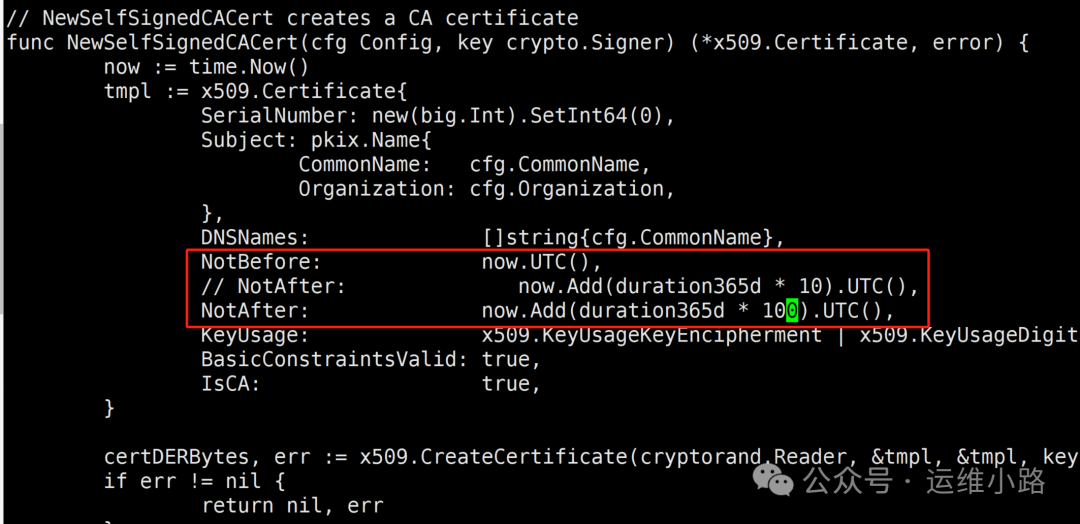
3.修改生成的其他证书
#把24*365 换成 24*365*100
vi ./cmd/kubeadm/app/constants/constants.go 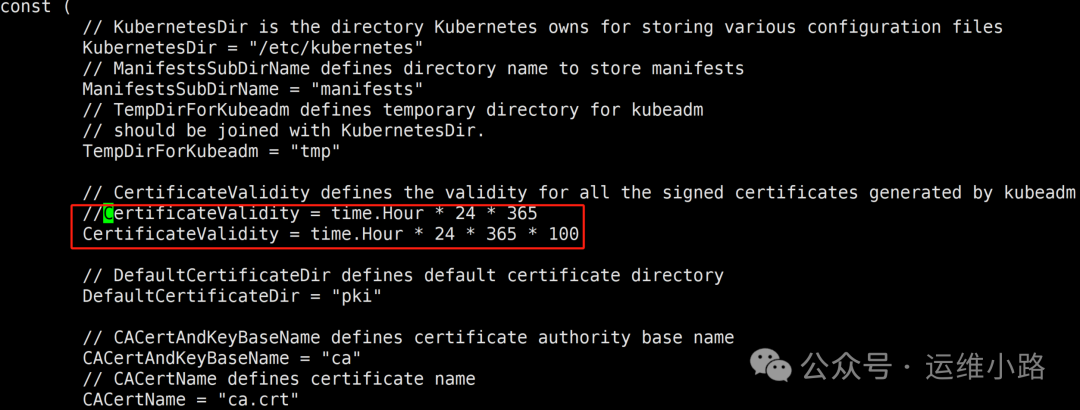
4.编译代码
我这里是在一台临时存量服务器进行编译的,如果你是新机器则可能还需要安装gcc等包。
yum -y install gccmake all WHAT=cmd/kubeadm GOFLAGS=-v编译完成以后,获取对应的kubeadm二进制包。
[root@localhost kubernetes]# ls _output/bin/kubeadm
_output/bin/kubeadm重新安装集群
参考Kubernetes(k8s)-k8s安装(docker版)。
这里需要使用我们手工编译的kubeadm二进制文件替换掉yum安装的kubeadm文件,文件路径是/usr/bin/kubeadm。然后使用进行集群的创建。
检查证书
可以看到,无论是ca证书,还是其他业务使用的证书都是100年,包括kubelet证书也是100年,这样我们的集群就不用在考虑证书到期的问题。
[root@node02 ~]# kubeadm certs check-expiration
[check-expiration] Reading configuration from the cluster...
[check-expiration] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml'
CERTIFICATE EXPIRES RESIDUAL TIME CERTIFICATE AUTHORITY EXTERNALLY MANAGED
admin.conf Dec 22, 2124 03:28 UTC 99y ca no
apiserver Dec 22, 2124 03:28 UTC 99y ca no
apiserver-etcd-client Dec 22, 2124 03:28 UTC 99y etcd-ca no
apiserver-kubelet-client Dec 22, 2124 03:28 UTC 99y ca no
controller-manager.conf Dec 22, 2124 03:28 UTC 99y ca no
etcd-healthcheck-client Dec 22, 2124 03:28 UTC 99y etcd-ca no
etcd-peer Dec 22, 2124 03:28 UTC 99y etcd-ca no
etcd-server Dec 22, 2124 03:28 UTC 99y etcd-ca no
front-proxy-client Dec 22, 2124 03:28 UTC 99y front-proxy-ca no
scheduler.conf Dec 22, 2124 03:28 UTC 99y ca no
CERTIFICATE AUTHORITY EXPIRES RESIDUAL TIME EXTERNALLY MANAGED
ca Dec 22, 2124 03:28 UTC 99y no
etcd-ca Dec 22, 2124 03:28 UTC 99y no
front-proxy-ca Dec 22, 2124 03:28 UTC 99y no #kubelet证书也是100年
[root@node02 pki]# openssl x509 -in /var/lib/kubelet/pki/kubelet-client-current.pem -noout -text |grep Validity -A2
Validity
Not Before: Jan 15 03:28:50 2025 GMT
Not After : Dec 22 03:28:51 2124 GMT
这样我们就实现了永久证书,再也不用考虑证书问题。
运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。

















 543
543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









