




前面几个小节讲解的Win和Linux部署DeepSeek的比较简单的方法,而且采用的模型也是最小的,作为测试体验使用是没问题的。如果要在生产环境使用还是需要用到GPU来实现,下面我将以有一台带上GPU显卡的Linux机器来部署DeepSeek。这里还只是先体验单机单卡,后期会更新多机多卡使用更高模型的文章。
1.确认配置
由于是虚拟机,并且虚拟机方面做了配置,所以这里并未显示真实显卡型号,实际型号:NVIDIA Tesla T4 16G。
[root@deepseek01 ~]# lspci |grep -i nvid00:0d.0 3D controller: NVIDIA Corporation Device 1eb8 (rev a1)[root@deepseek01 ~]#
2.下载驱动
根据自己的显卡型号下载对应的型号,我这里是NVIDIA Tesla T4 16G。
https://www.nvidia.cn/drivers/lookup/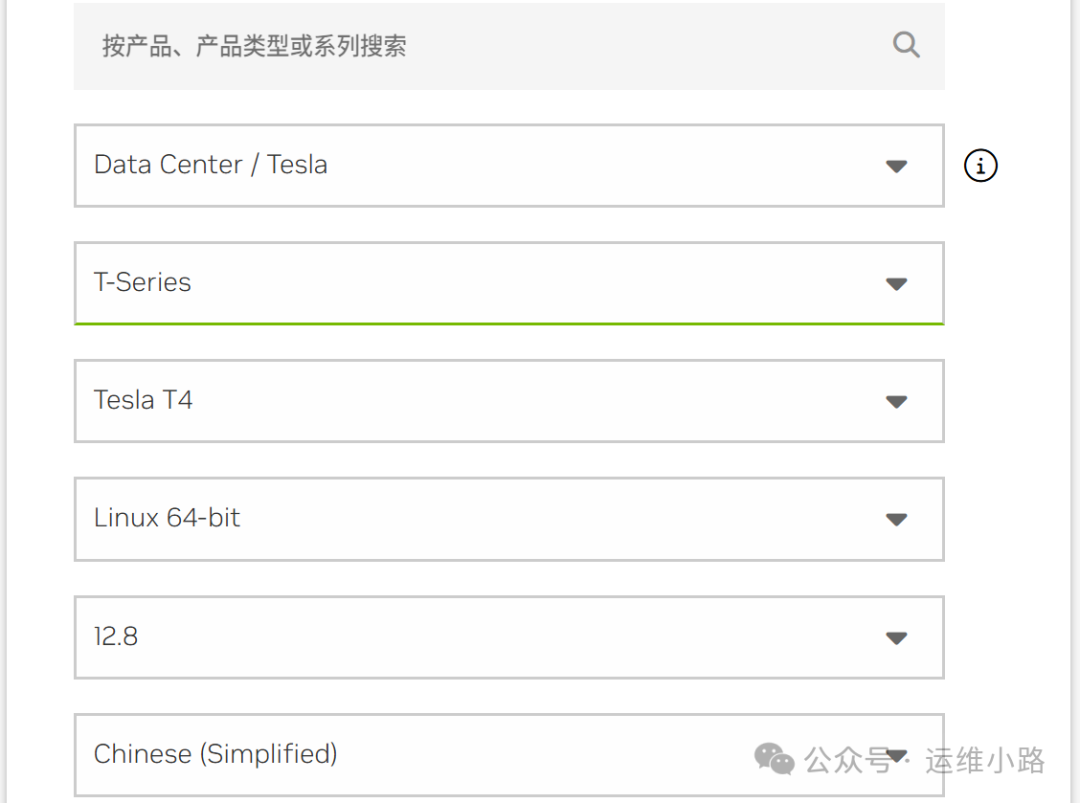
然后进入搜索下载页面,就可以看到下面的下载地址,这里下载是下载到本地电脑,如果是想直接下载到服务器里面,需要添加一个referer。

#直接下载会提示403,所以这里添加了一个refererwget --referer=https://www.nvidia.cn/drivers/details/240206/ \https://cn.download.nvidia.com/tesla/570.86.15/NVIDIA-Linux-x86_64-570.86.15.run
3.升级内核
这里需要内核高于4.15才可以,否则驱动会安装失败,所以建议选择更高内核系统,我这里使用是CentOS7.5,做了先升级内核,然后手工编译了gcc才最终安装成功驱动。我在其他环境安装Ubuntu 22.4 则没有这个动作,直接安装下面的包即可(gcc需要换成gcc-12)。
4.安装工具包
yum -y install gcc gcc-c++ tar make bzip2 pkgconfig libglvnd-devel libglvnd elfutils-libelf-devel5.安装GPU显卡驱动
./NVIDIA-Linux-x86_64-570.86.15.run -a -s -Z \--no-opengl-files
-
-a或--accept-license:这个参数表示你接受NVIDIA软件许可协议。如果不使用这个参数,安装过程中会提示你阅读并接受许可协议。 -
-s或--silent:这个参数使安装脚本以静默模式运行,不会显示任何用户交互提示,直接进行安装。 -
-Z或--disable-nouveau:这个参数用于禁用开源的Nouveau驱动,这是因为NVIDIA官方驱动与Nouveau驱动不兼容。在安装NVIDIA官方驱动之前,通常需要先禁用Nouveau驱动。Ubuntu 22.4需要手工禁用。 -
--no-opengl-files:这个参数告诉安装脚本不要安装OpenGL相关的文件。如果你不需要OpenGL支持(例如,你只打算使用GPU进行计算任务而不是图形渲染),可以使用这个参数。这可能会减少驱动程序包的大小,并避免在某些情况下可能出现的兼容性问题。
6.检查驱动安装情况
如下图已经识别到我的显卡。
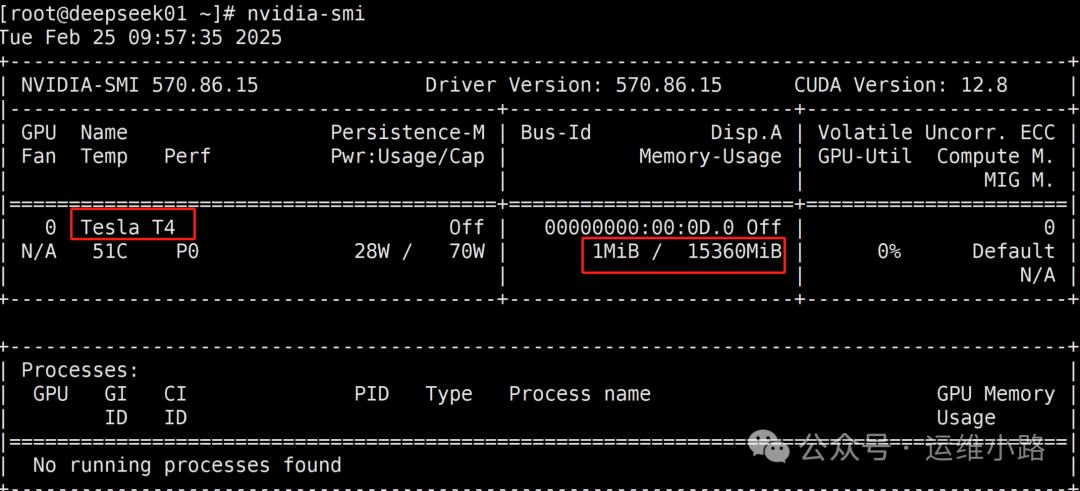
7.GPU驱动常驻内存
cd /usr/share/doc/NVIDIA_GLX-1.0/samples/tar xvf nvidia-persistenced-init.tar.bz2cd nvidia-persistenced-init/./install.sh#检查状态是否正常systemctl status nvidia-persistenced.service
8.下载CUDA
这里连CentOS7适合的CUDA都没有,这里先用8代替。
https://developer.nvidia.com/cuda-downloads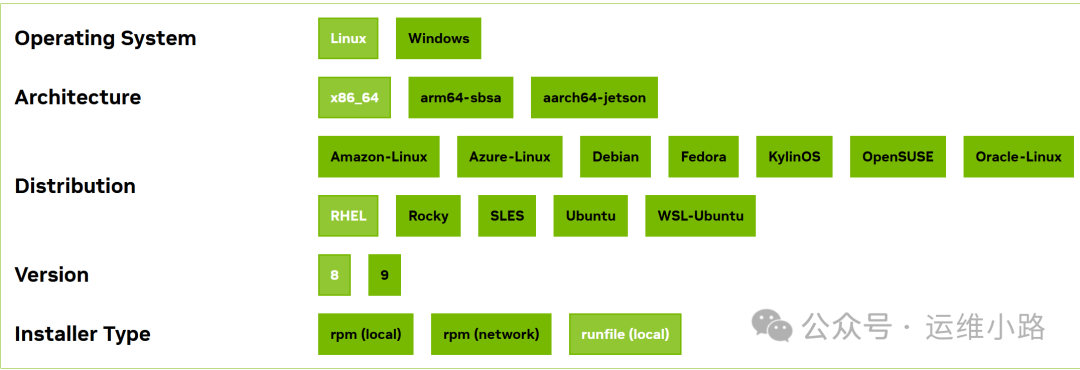
9.安装CUDA
接受协议,取消默认驱动,最后是安装
./cuda_12.8.0_570.86.10_linux.run --no-opengl-libs
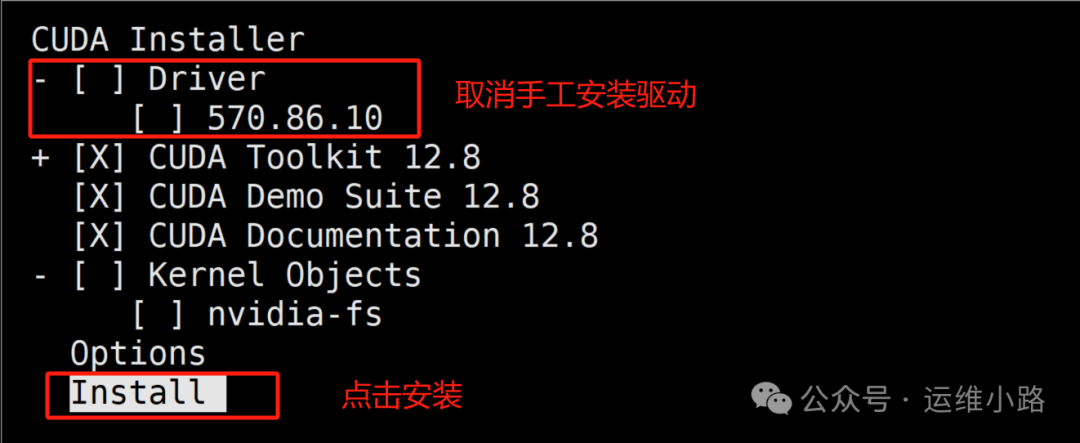

10.配置环境变量&检查CUDA安装情况
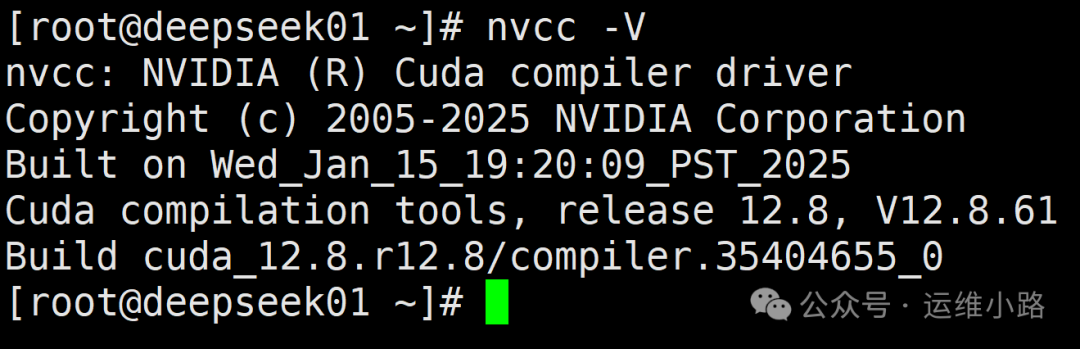
添加到/etc/profile文件中,对所有用户生效# vim /etc/profileexport PATH=/usr/local/cuda/bin:$PATHexport LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH# source /etc/profile#测试cuda安装是否正确,环境变量是否识别成功# nvcc -V
11.安装DeepSeek
参考上小节:快速搭建DeepSeek-Linux版本,只是这里我选择的8b版本,这里已经显示使用的是我们的GPU。
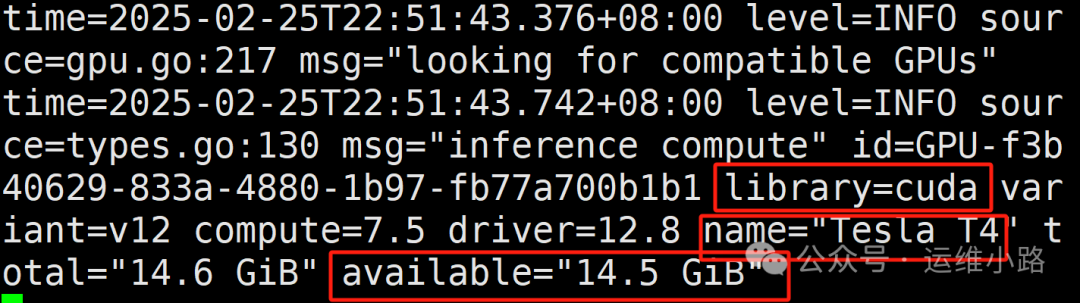
12.验证GPU
从下图已经可以看出来他正在使用GPU进行运算。
nvidia-smi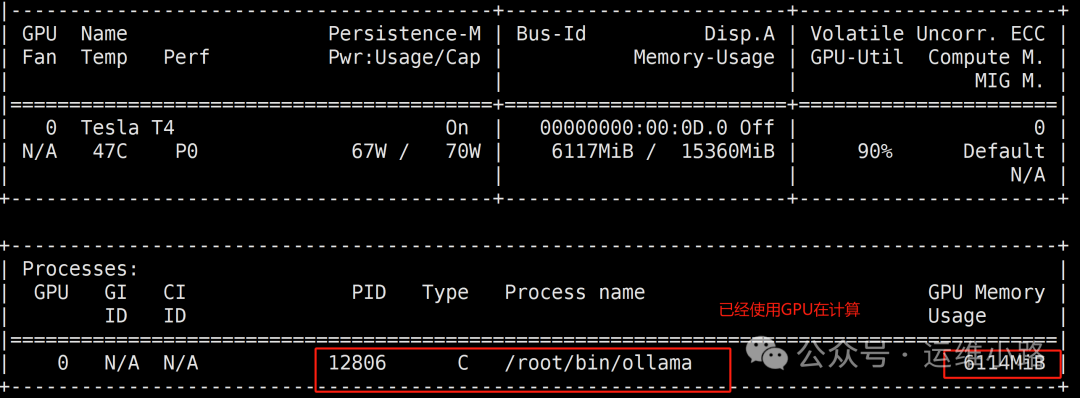
总结:操作系统尽量选择比较新的内核,CentOS7,还是老了。


















 1784
1784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









