





 本文介绍了强化学习的基本概念,包括马尔科夫过程、马尔科夫决策过程、价值函数及最优策略等内容,阐述了如何通过强化学习让智能体最大化长期收益。
本文介绍了强化学习的基本概念,包括马尔科夫过程、马尔科夫决策过程、价值函数及最优策略等内容,阐述了如何通过强化学习让智能体最大化长期收益。
参考了《Reinforcement Learning: An Introduction》和
David Silver强化学习公开课,
这一章主要来自David Silver的ppt,建议直接看ppt,我只把容易犯错的地方点出来了
马尔科夫过程是强化学习的基础
Finite Markov Decision Processes
Markov property
A state StSt is Markov if and only of
P[St+1|St]=P[St+1|S1,⋯,St]P[St+1|St]=P[St+1|S1,⋯,St]
- The state captures all relevant information from the history
- Once the state is know, the history may be thrown away
- i.e. The state is a sufficient statistic of the future
A Markov process is a memoryless random process, i.e. a sequence of random states S1,S2,⋯S1,S2,⋯ with the Markov property.
Markov Process
A Markov Process (or Markov Chain) is a tuple ⟨S,P⟩⟨S,P⟩
- S is a (finite) set of states
- P is a state transition probability matrix, Pss′=P[St+1=s′|St=s]Pss′=P[St+1=s′|St=s]
A Markov reward process is a Markov chain with values.
Markov Reward Process
A Markov Process (or Markov Chain) is a tuple ⟨S,P,R,γ⟩⟨S,P,R,γ⟩
- S is a (finite) set of states
- P is a state transition probability matrix, Pss′=P[St+1=s′|St=s]Pss′=P[St+1=s′|St=s]
- R is a reward function, Rs=E[Rt+1|St=s]R is a reward function, Rs=E[Rt+1|St=s]
- γ is a discount factor, γ∈[0,1]γ is a discount factor, γ∈[0,1]
注意这里Pss′Pss′的定义,是指从状态ss到的概率
后面常因为名字(return)忘记这个的定义,跟上面的单个Reward不一样
Return
The return GtGt is the total discounted reward from time-step t.
Gt=Rt+1+γRt+2+⋯=∑k=0∞γkRt+k+1Gt=Rt+1+γRt+2+⋯=∑k=0∞γkRt+k+1
- The discount γ∈[0,1]γ∈[0,1] is the present value of future rewards
- The value of receiving reward R after k+1 time-steps is γkRγkR
- γγ close to 0 leads to “myopic(近视)” evaluation
- γγ close to 1 leads to “far-sighted(远见)” evaluation
后面提到的很多方法都是看的很远(远见)的
Value Function
The state value function v(s) of an MRPMRP is the expected return starting form state s
v(s)=E[Gt|St=s]v(s)=E[Gt|St=s]
确实有必要看一下MRP的Bellman Equation,并与MDP对比。在MRP中没有考虑任何关于action的事情。因为MDP才是强化学习的主角,所以不看David Silver的ppt中的MRP实例了,容易对后面MDP的理解造成误解。
简单看一下Bellman Equation
MRP的状态转换,没有任何action的影响,我们在后面MDP中会考虑actions的影响
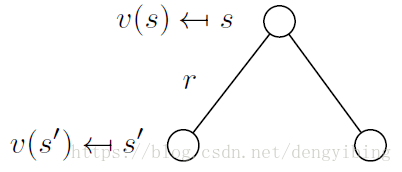
其实观察上式,上面计算的是动态规划,而注意到Bellman Equation又称为动态规划方程,上面的计算就很容易理解了
A Markov decision process (MDP) is a Markov reward process with decisions. It is an environment in which all states are Markov.
Markov Decision Process
A Markov Process (or Markov Chain) is a tuple ⟨S,A,P,R,γ⟩⟨S,A,P,R,γ⟩
- S is a (finite) set of states
- A is finite set of actions
- P is a state transition probability matrix, Pass′=P[St+1=s′|St=s,At=a]Pss′a=P[St+1=s′|St=s,At=a]
- R is a reward function, Ras=E[Rt+1|St=s,At=a]Rsa=E[Rt+1|St=s,At=a]
- γγ is a discount factor, γ∈[0,1]γ∈[0,1]
注意与上面MRP的区别,这里的黑点是执行一个action之后到达的中间状态,后面用q(s,a)q(s,a)来定义此状态,黑点到达后面的状态s′s′的概率就是上面MDP中定义的那个Pass′=P[St+1=s′|St=s,At=a]Pss′a=P[St+1=s′|St=s,At=a]
Policy
A policy ππ is a distribution over actions given states,
π(a|s)=P[At=a|St=s]π(a|s)=P[At=a|St=s]
- A policy fully defines the behaviour of an agent
- MDP policies depend on the current state (not the history)
- i.e. Policies are stationary (time-independent), At∼π(⋅|St),∀t>0At∼π(⋅|St),∀t>0
- Given an MDP M=⟨S,A,P,R,γ⟩M=⟨S,A,P,R,γ⟩ and a policy ππ
- The state sequence S1,S2,⋯S1,S2,⋯ is a Markov reward process ⟨S,Pπ⟩⟨S,Pπ⟩
- The state and reward sequence S1,R2,S2,⋯S1,R2,S2,⋯ is a Markov reward process ⟨S,Pπ,Rπ,γ⟩⟨S,Pπ,Rπ,γ⟩
- where
Pπs,s′=∑a∈Aπ(a|s)Pass′Rπs=∑a∈Aπ(a|s)RasPs,s′π=∑a∈Aπ(a|s)Pss′aRsπ=∑a∈Aπ(a|s)Rsa要特别注意policy的distribution的定义,因为在后面讲的off-policy方法的概念中,生成样本的policy和目标policy是不同的
Value Function这个是针对MDP的
The state-value function vπ(s)vπ(s) of an MDP is the expected return starting from state ss, and then following policy
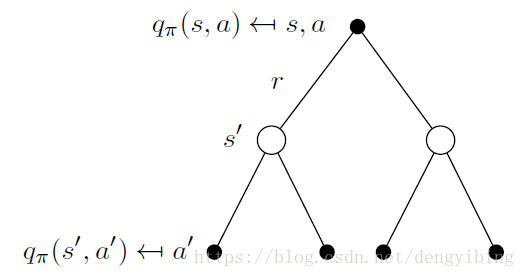
vπ(s)=Eπ[Gt|St=s]vπ(s)=Eπ[Gt|St=s]The action-value function qπ(s,a)qπ(s,a) is the expected return
starting from state ss, taking action , and then following policy ππ
qπ(s|a)=Eπ[Gt|St=s,At=a]qπ(s|a)=Eπ[Gt|St=s,At=a]
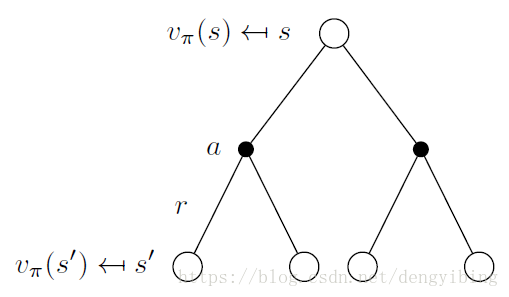
Bellman Expectation Equation for VπVπ
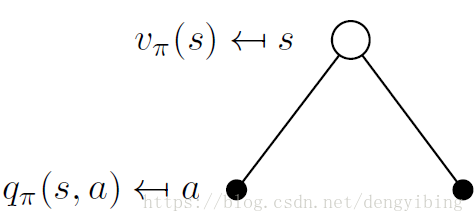
Bellman Expectation Equation for QπQπ
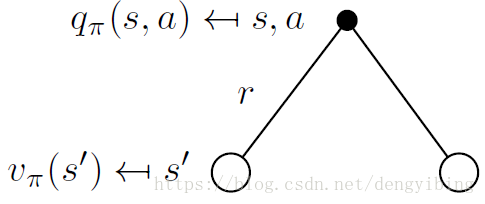
Optimal Value Function
The optimal state-value function v∗(s)v∗(s) is the maximum value function over all policies
v∗(s)=maxπvπ(s)v∗(s)=maxπvπ(s)The optimal action-value function q∗(s,a)q∗(s,a) is the maximum action-value function over all policies
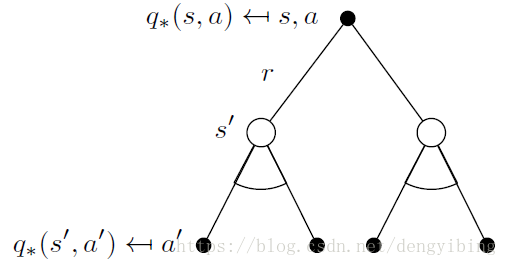
q∗(s,a)=maxπqπ(s,a)q∗(s,a)=maxπqπ(s,a)只要知道了q∗q∗问题就解决了,比知道v∗v∗更方便。还有注意的是,上面是在所有的ππ(policy)中选择使得 qq 最大的(policy),这就是值给出了最佳policy的概念,当然是没有很直接的办法得到结果的,后面将针对上述问题介绍各种逼近的方法
Optimal Policy
Dene a partial ordering over policies
Finding an Optimal Policy
An optimal policy can be found by maximising over q∗(s,a)q∗(s,a),
如果我们知道了q∗(s,a)q∗(s,a),那么我就可以马上得到optimal policy
Optimal Bellman Expectation Equation
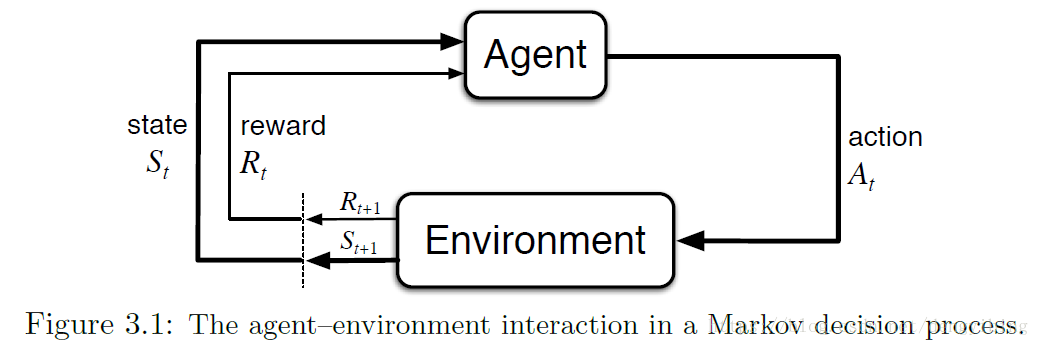
The Agent-Environment Interface
- The learner and decision maker is called the agent.
- The thing it interacts with, comprising everything outside the agent, is called the environment.
MDP和agent一起生成的sequence或者trajectory
以下函数定义了MDP的动态性,agent处于某个状态s,在该状态下采取行动a,然后到达状态s′s′,并获得奖励r。这个公式是MDP的关键。这个四参数的函数可以推导出任何东西
for all s′s′, s∈Ss∈S, r∈Rr∈R, and a∈A(s)a∈A(s)
其中有
3.2 Goals and Rewards
agent的目的就是最大化它收到的全部rewards
3.5 Policies and Value Functions
state-value function for policy ππ
action-value function for policy ππ
对于任何policy ππ和任何状态ss,state-value和其可能的后继状态的state-value之间存在以下一致性条件
3.6 Optimal Policies and Optimal Value Functions
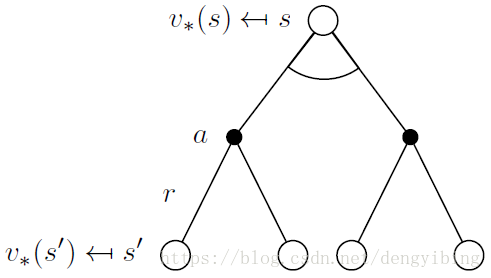
optimal state-value function
optimal action-value function
写出关于v∗v∗的q∗q∗
Bellman optimality equation

















 918
918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









