





 本文深入解析了强化学习中的动态规划(DP)方法,包括策略评估、策略改进及迭代策略等核心概念,并探讨了策略迭代与值迭代两种算法的实现细节与应用场景。
本文深入解析了强化学习中的动态规划(DP)方法,包括策略评估、策略改进及迭代策略等核心概念,并探讨了策略迭代与值迭代两种算法的实现细节与应用场景。
本笔记参考《Reinforcement Learning: An Introduction》和
David Silver的公开课及其ppt
David Silver的课程在Tabular Soluction上介绍的比较多。可以配合David Silver的课程来理解《Reinforcement Learning: An Introduction》这本书的内容
DP指的是一组算法,可以用来计算最佳策略,给定一个完美的model作为马尔科夫决策过程(MDP)[这是必须的]。当然之后介绍的算法不是用DP解的,它只是给后面要介绍的方法基础理论
一定要注意DP解问题的必要条件。我们假设environment是finite MDP。其中我们假设它的state,action以及reward sets,S,A,and,RS,A,and,R是有限的,而且它的动态性是通过一系列的概率p(s′,r|s,a)p(s′,r|s,a)给出来的
4.2 Policy Evaluation (Prediction)
Policy evaluation Estimate vπvπ
Iterative policy evaluation
Policy Evaluation就是对于任意policy ππ ,计算出state-value function vπvπ。这也被看成prediction problem

4.2 Policy Improvement
Policy improvement Generate π′≥ππ′≥π
Greedy policy improvement
policy improvement theorem
假设有 π′π′ 比 ππ 更好
证明:
很自然的就会想到使用greedy policy在每个状态s根据qπ(s,a)qπ(s,a)选择最好的a,从而得到新的policy π′π′
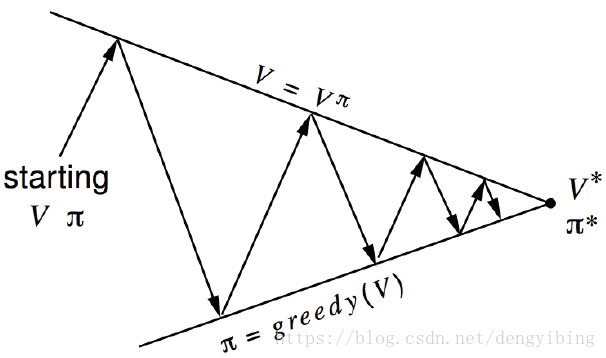
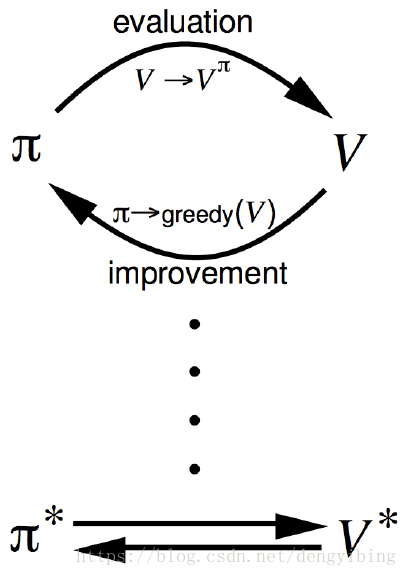
4.3 Policy Iteration
把Policy Evaluation (Prediction)和Policy Improvement两个过程迭代进行,最终获得收敛的最佳policy

注意上图的迭代是Policy Evaluation和Policy Improvement交替进行的
这个过程被证明是收敛的,最后一定可以收敛到最佳的policy
4.4 Value Iteration
Value Iteration不像policy iteration,没有显式的 policy evaluation。policy iteration的一个缺点是每次迭代都要进行完整的policy evaluation,这非常的耗时。
policy evaluation的步骤可以被截取为少许的几步,而且还保证policy iteration的收敛。一个特殊的例子就是在仅进行一个sweep后停止。

在每个sweep中,执行一个sweep的policy evaluation和一个sweep的policy improvement
注意与policy iteration的区别p(s′,r|s,π(s))p(s′,r|s,π(s))与p(s′,r|s,a)p(s′,r|s,a)
| Problem | Bellman Equation | Algorithm |
|---|---|---|
| Prediction | Bellman Expectation Equation | Iterative Policy Evaluation |
| Control | Bellman Expectation Equation + Greedy Policy Improvement | Iterative Policy Evaluation |
| Control | Bellman Optimality Equation | Value Iteration |
4.6 Generalized Policy Iteration (GPI)
上面说的迭代就是强化学习的迭代框架

















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









