





 本文介绍了多臂老虎机问题的基础概念及解决方法,包括行动价值方法、ε-贪婪策略、非平稳问题跟踪、乐观初始值法、上置信界行动选择算法以及梯度老虎机算法等内容。
本文介绍了多臂老虎机问题的基础概念及解决方法,包括行动价值方法、ε-贪婪策略、非平稳问题跟踪、乐观初始值法、上置信界行动选择算法以及梯度老虎机算法等内容。
本文为看《reinforcement learning :an introduction》时的笔记总结
标题解释为:多臂老虎机
因为我最开始看的时候不知道这个名词的意思
这一章基本上把后面要讲到的所有方法都简介了一遍,初步了解这些方法对理解后面的内容很有帮助
1. A k-armed Bandit
该问题指老虎机,有k个臂,对应k个不同的options或actions。在每次选择之后,你会收到一个数值奖励,该数值奖励取决于你选择的行动的stationary probability distribution
expected reward given that a is selected
其中 At A t 表示t时刻被选中的action
We denote the estimated value of action a at time step t as Qt(a) Q t ( a ) . We would like Qt(a) Q t ( a ) to be close to q∗(a) q ∗ ( a ) .
在t时刻总是有一个estimated value最大的action,贪心的选择这个动作被称为exploiting,而选择nongreedy actions则被称为exploring,平衡这两种选择的是个问题
2. Action-value Methods
一种很自然的方法是平均化所实际收到的奖励
其中 1predicate 1 p r e d i c a t e 表示随机变量是1,如果predicate为true,否则为0
这里根据大数定理 Q(a) Q ( a ) 是收敛到 q∗(a) q ∗ ( a ) 的
greedy action selection method 则可以写为
因为greedy 方法总是exploit,不会去explore,所以可以用 ε-greedy ε -greedy 方法。
大多数时候(概率 1−ε 1 − ε )正常greedy选择;只是偶尔(以概率 ε ε )从所有actions中等概率的选择action,与action-value estimates独立
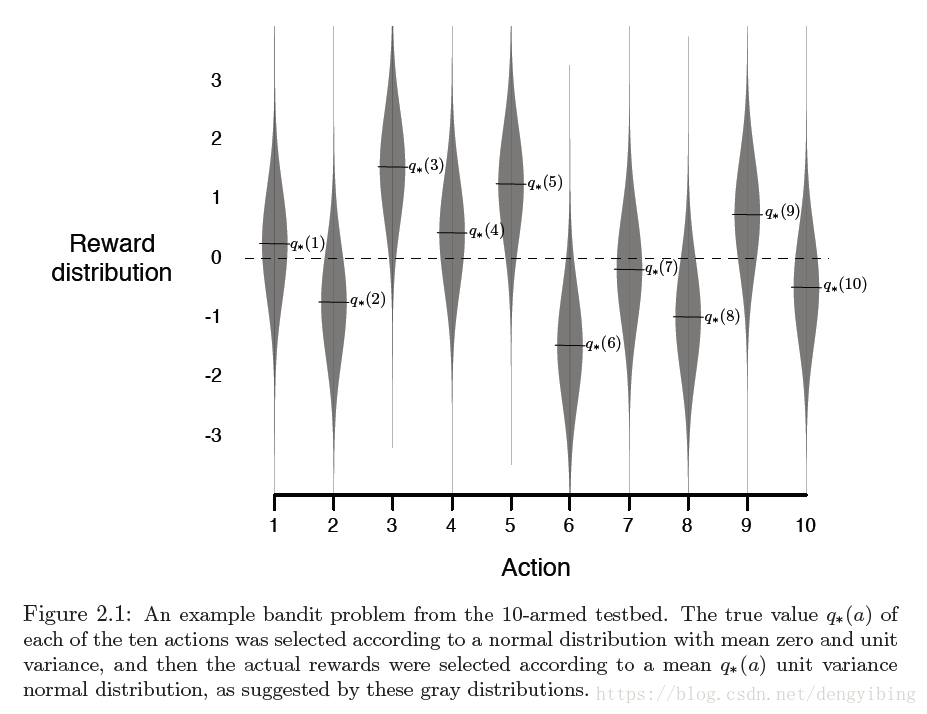
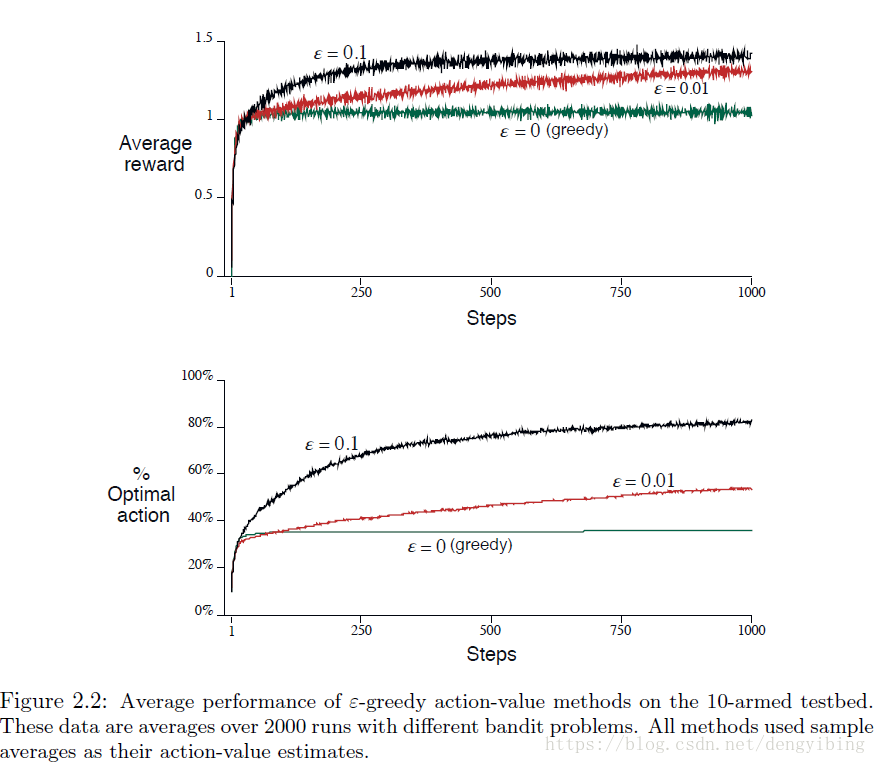
3. The 10-armed Testbed
用一个实例来说明 ε-greedy ε -greedy 方法比 greedy greedy 方法要好
4. Incremental Implementation
我们迄今为止所讨论的action-value methods都将action-values估计为观察到的rewards的样本平均值。
考虑增量的计算这些averages,这样更高效,而且每一步的内存和计算都是固定的
Ri R i now denote the reward received after the ith selection of this action
Qn Q n denote the estimate of its action value after it has been selected n-1 times
则有
对于n=1,有 Q2=R1 Q 2 = R 1
上述更新公式的一般形式将会一直出现在后面的文章中
NewEstimate←OldEstimate+StepSize [Target−OldEstimate] N e w E s t i m a t e ← O l d E s t i m a t e + S t e p S i z e [ T a r g e t − O l d E s t i m a t e ]

5. Tracking a Nonstationary Problem
averaging methods到目前为止对于stationary bandit problems是合适的,因为对bandit problems,reward probabilities不随时间变化
但是很多强化学习问题是nonstaionary的,在这种情况下,给最近的reward更大的权重更有意义。这种做法最流行的方法之一是使用恒定的step-size参数
这里average Qn Q n 被修改为: Qn+1≐Qn+α[Rn−Qn] Q n + 1 ≐ Q n + α [ R n − Q n ] ,其中 α∈(0,1] α ∈ ( 0 , 1 ] ,而且是常数。
This results in
Qn+1
Q
n
+
1
being a weighted average of past rewards and the initial estimate
Q1
Q
1
:
有时,逐步改变步长参数是很方便的。但是不是所有的 αn(a) α n ( a ) 都保证收敛。
然而随机逼近理论中众所周知的结果为我们提供了确保以概率 1 收敛的条件:
6. Optimistic Initial Values
到目前为止,我们所讨论的所有方法在一定程度上取决于初始行动价值估计
Q1(a)
Q
1
(
a
)
。用统计学的语言来说,这些方法偏向于他们的初步估计
但这并不普遍
7. Upper-Confidence-Bound(UCB) Action Selection
因为采用 ε-greedy ε -greedy 方法,所以
根据其实际最佳的潜力,在非贪婪行为中进行选择会更好一些,同时考虑到它们的估计有多接近最大值以及这些估计值的不确定性
One effective way of doing this is to select actions according to:\
At=argmaxα[Qt(a)+clntNt(a)−−−−√] A t = a r g max α [ Q t ( a ) + c ln t N t ( a ) ]
- Nt(a) N t ( a ) denotes the number of times that action a has been selected prior to time t
- the number c > 0 controls the degree of exploration
UCB常用在蒙特卡洛搜索树中
8. Gradient Bandit Algorithms
到目前为止,前面讲到的方法都是使用estimates来选择actions。这通常是一个好方法,但它不是唯一可能的方法。
这里考虑action a的numerical preference Ht(a) H t ( a )
相对preference才是要考虑的,这里根据soft-max distribution来考虑,根据更大的相对preference选择action
这里的 πt(a) π t ( a ) 就是后面常说的policy,在时刻t选择动作a的概率
学习算法为
这里 α>0 α > 0 是学习率

















 1782
1782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









