







36 数据增广 data augmentation
背景问题:不同的色温、光反射会导致模型的泛化性出现问题。
方法:
- 在语言中加入不同的背景噪音
- 改变图片的颜色和形状
训练:一般的做法是在线生成数据,随机做增强数据,相当于一个正则项。
- 翻转:左右翻转可行,上下翻转不一定可行
- 切割:从图片切割出一块,再变形到固定形状,随机高宽比([3/4、4\3])、随机大小[8%、100%]、随机位置来进行切割。
- 颜色:改变色调、饱和度、明亮度(0.5、1.5)
37 微调 fine-tuning
也叫迁移学习,决定了深度学习能不能work的。
背景问题:标注一个数据集很贵,希望可以在有一定数据学习的基础上,有数据学习的拓展能力。
常规神经网络架构:CNN做特征提取,最后用线性分类器做分类
微调:CNN仍然可以做特征抽取,但是线性分类的部分无法直接用。所以把CNN的层直接copy过来,最后一层进行随机初始化,这样只需要微调(微训练)就可以得到比较好的学习效果。相当于一个有更强的正则化的训练过程,训练过程中使用更小的学习率、使用更少的数据迭代,目标数据集一般比源数据集复杂度小。
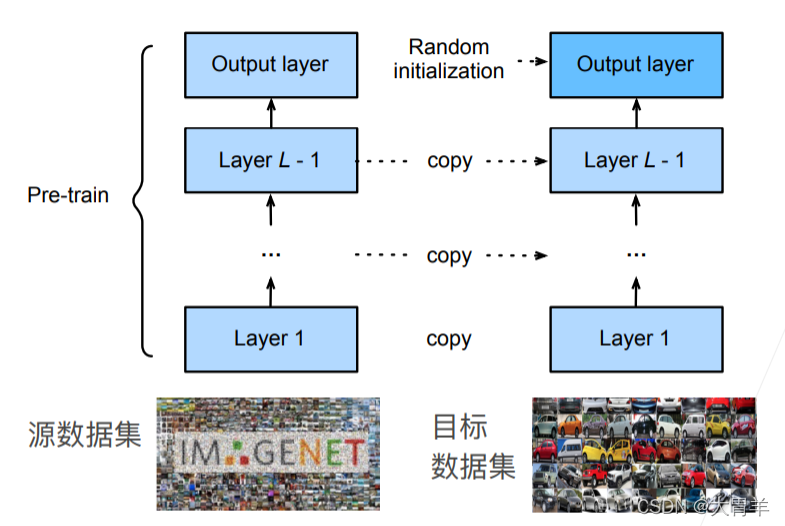
常用的技术:
- 重用分类器权重:如果分类相同,可以用最后一层的向量来进行初始化
- 固定一些层:神经网络的表示是有层次的。底层的特征更通用,高层次的更偏向于数据集相关,所以如果把底层的参数固定住,可以达到更高的正则化效果。
总结:
预训练模型质量很重要,微调通常速度更快,精度更高。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









