







R-CNN
- 使用启发式搜索算法来选择锚框
- 使用预训练模型来对每个锚框抽取特征
- 训练一个SVM来对类别分类
- 训练一个线性回归模型来预测边缘框偏移
兴趣区域(RoI)池化层
把一个锚框分割为n×m块,输出每块里面的最大值,这样无论锚框多大,总是输出nm个值。RoI主要是为了解决锚框大小不同的问题,使得锚框可以被pooling成固定大小的,可以做一个batch的处理。
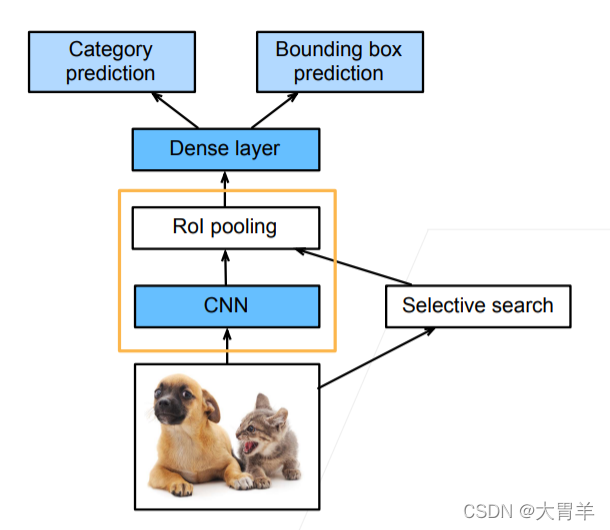
Faster RCNN
将图片变成一个特征图,再变成一个特征向量,在特征上对应锚框。这样的CNN不是对每个锚框抽取特征,而是对整个图片抽取特征,避免了上千次的锚框抽取特征。
- 使用CNN对图片抽取特征
- 使用RoI池化层对每个锚框生成固定长度的特征
Faster RCNN
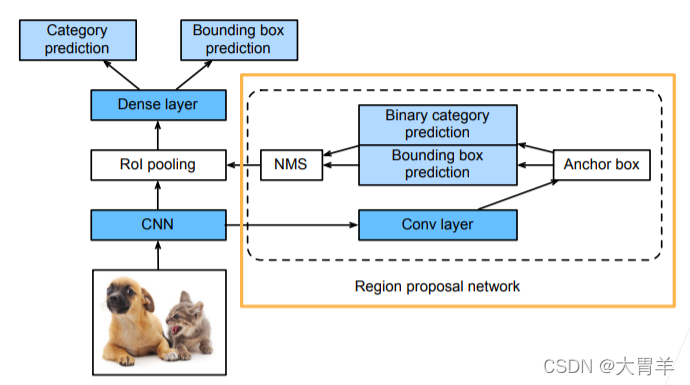
- 使用区域建议网络 RPN来替代启发式搜索算法来获得更好的锚框,RPN相当于是一个比较粗的目标检测,整体相当于有两个stage,速度相对还是比较慢。
- Faster RCNN精度非常高,但是速度较慢
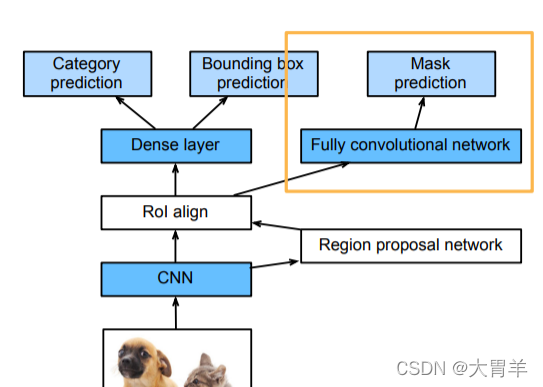
Mask R-CNN
- 如果有像素级别的编号(语义分割),使用FCN全卷积神经网络来利用这些信息。
- RoI变成了align,无法整除的就直接把像素切开
小总结:
RCNN是最早、最有名的基于锚框的方法;Faster RCNN和Mask RCNN主要用在高精度场景下,Mask RCNN在无人车中用的比较多。
单发多框检测(SSD Single Shot Detection)
SSD是single stage的网络(和Faster RCNN区分)。
- 首先使用一个基础网络来抽取特征,然后用多个卷积层来减半高宽
- 在每个阶段(多尺度)都生成锚框(每个像素为中心生成多个锚框),底部的段用来拟合小物体,顶部的段用来拟合大物体
- 对每个锚框都取预测类别和边缘框
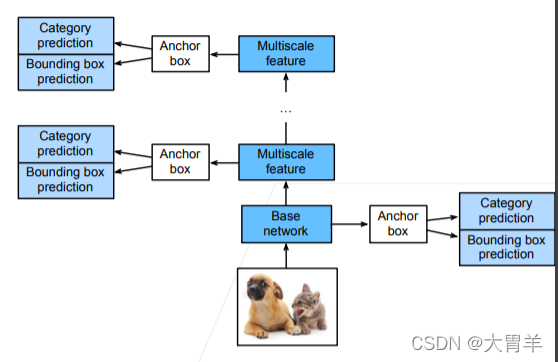
SSD速度相对比较快,但精度不够高,但是网络简单,启发了后续的一系列网络。
YOLO
YOLO从SSD发展而来,SSD中有大量锚框重叠,浪费了很多计算,YOLO把图片均匀分成S×S个锚框,每个锚框预测B个边缘框(解决一个框中有多个种类的物体的问题)。
YOLO V3的精度没有那么高,但是一些trick的使用可以提高它的精度。

















 454
454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









