




 提出了一种新的图对比学习方法GCA,该方法通过自适应增强图结构和节点属性来改善无监督图表示学习的效果。在拓扑层面,基于节点中心性度量来调整边的去除概率;在节点属性层面,则通过识别不重要的特征维度并增加噪声来破坏节点特征。
提出了一种新的图对比学习方法GCA,该方法通过自适应增强图结构和节点属性来改善无监督图表示学习的效果。在拓扑层面,基于节点中心性度量来调整边的去除概率;在节点属性层面,则通过识别不重要的特征维度并增加噪声来破坏节点特征。
代码链接:https://github.com/CRIPAC-DIG/GCA
基于自适应增强的图对比学习
摘要
近年来,对比学习(CL)已成为一种成功的无监督图表示学习方法。大多数图CL方法首先对输入图进行随机增强,以获得两个图视图,并最大限度地提高两个视图的表示一致性。尽管图CL方法的蓬勃发展,但图增强方案的设计——CL中的一个关键组成部分——仍然很少被探索。
我们认为,数据增强方案应该保留图的内在结构和属性,使模型学习对不重要节点和边缘的扰动不敏感的表示。然而,现有的方法大多采用统一的数据增强方案,如均匀的丢弃边和统一的清洗特征,导致性能次优。
在本文中,我们提出了一种新的具有自适应增强的图对比表示学习方法,该方法包含了图的拓扑和语义方面的各种先验。
具体来说,在拓扑层面上,我们设计了基于节点中心性度量的增强方案来突出重要的连接结构。在节点属性层面上,我们通过向不重要的节点特征添加更多的噪声来破坏节点特征,以强制模型识别底层语义信息。
我们在各种真实世界的数据集上进行了广泛的节点分类实验。实验结果表明,我们提出的方法始终优于现有的最先进的基线,甚至超过了一些有监督的基线,这验证了自适应增强对比框架的有效性。
1 引言
DGI、GMI、MVGRL等数据增强方法的缺点:
- 结构域或属性域中的简单数据增强,如DGI中的特征转换,都不足以为节点生成不同的邻域(即上下文),特别是当节点特征稀疏时,导致难以优化对比目标。
- 以前的工作忽略了在执行数据增强时节点和边缘影响的差异。例如,如果我们通过均匀地掉边来构造视图,去除一些有影响的边会降低嵌入质量。
由于对比目标学习到的表示往往对数据增强方案引起的corruption是不变的,数据增强策略应该自适应【学习重要性】输入图,以反映其内在模式。
本文提出的GCA框架如图1所示:
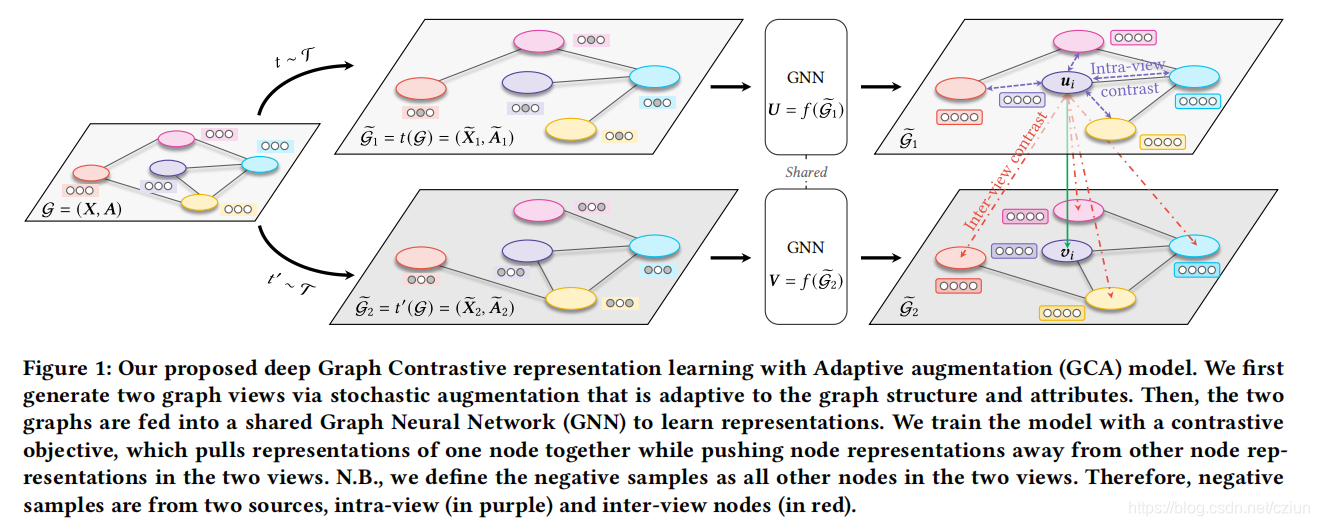
整体过程和之前的GRACE等一样,不同之处在于数据增强以产生两个视图的方法。
具体来说,我们在拓扑和节点属性级别上提出了一种联合的自适应数据增强方案,即去除边缘和掩蔽特征,为不同视图中的节点提供不同的上下文,以促进对比目标的优化。
此外,我们通过中心性度量来识别重要的边缘和特征维度。
然后,在拓扑层面上,我们通过给不重要的边很大的去除概率来自适应地掉边,以突出重要的连接结构。在节点属性层面上,我们通过向不重要的特征维度添加更多的噪声来破坏属性,以强制模型识别底层的语义信息。
2 相关工作
3 方法
3.1 准备工作
G = { V , E } \mathcal{G}=\{\mathcal{V},\mathcal{E}\} G={ V,E}, V = { v 1 , v 2 , . . . , v N } \mathcal{V}=\{v_1,v_2,...,v_N\} V={ v1,v2,...,vN}, E ⊆ V × V \mathcal{E}⊆\mathcal{V}×\mathcal{V} E⊆V×V。
特征矩阵: X ∈ R N × F \pmb{X}∈\mathbb{R}^{N×F} XXX∈RN×F,其中 x i ∈ R F \pmb{x}_i∈\mathbb{R}^F xxxi∈RF是节点 v i v_i vi的特征。
邻接矩阵: A ∈ { 0 , 1 } N × N \pmb{A}∈\{0,1\}^{N×N} AAA∈{ 0,1}N×N,当 ( v i , v j ) ∈ E (v_i,v_j)∈\mathcal{E} (vi,vj)∈E时, A i j = 1 \pmb{A}_{ij}=1 AAAij=1。
在无监督设置下进行训练时, G \mathcal{G} G中没有给定节点的类别信息。
目标是学习一个GNN编码器 f ( X , A ) ∈ R N × F ′ f(\pmb{X},\pmb{A})∈\mathbb{R}^{N×F'} f(X
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1166
1166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









