







talk
这篇文章是GRACE的改进工作,通过不同的重要性来进行 掩码, 具体就是 通过节点重要性 来更倾向于丢弃 不重要的节点,重要性度量的三种方式:度中心性,特征向量中心性,pagerank中心性。 这里我开始觉得 这样相比较随机掩码,如果丢弃的都是不重要的节点,这没有随机性,有鲁棒性吗?模型会不会学得单一的模式。作者这里的论点是 认为这样 丢弃 能保留重要结构,使得原图语义不要发生太大变化,不去丢很重要边或特征,使得图直接被破坏。 特征上,不同重要性对于节点的每一维特征进行掩码,这里作者是以噪声作为论点。
1.model
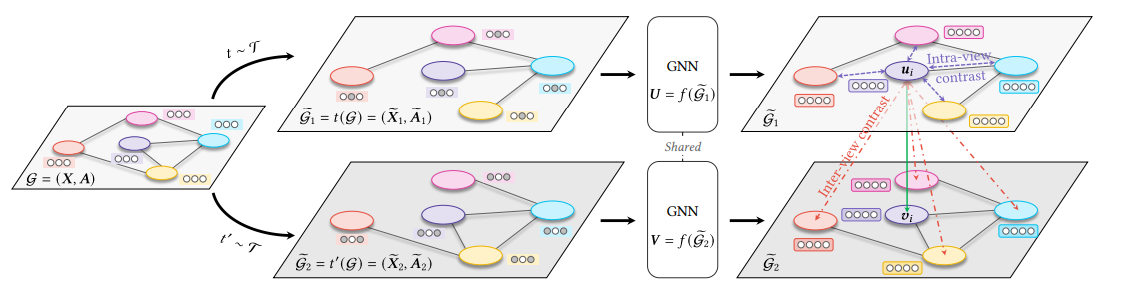
具体的细节都是和GRACE类似的,related work的语句都是照搬自己的GRACE。 损失和网络结构完全是一样的。
2. 两处改动
2.1 掩码A,丢弃边

这里的pe就是每个边 丢弃的概率,在GRACE中 是 固定的参数,从伯努利分布中采样出来。
2.1.1 本文改进:通过节点中心性
定义: 边的中心性=所连接两个节点的中心性。 无向图是两个节点求和取平均,有向图是所指向的target节点的重要性(这里引出一篇文章18年oxford出版的一个)来佐证。
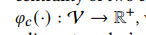
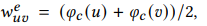
计算出之后,因为节点中心性和 节点的度一样可能在不同尺度上vary很大,因此 采用log 减缓节点有很多边的影响, 这里是 上一步求出的是 一个正数,采用log平滑,
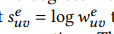
之后 进行正则化,放缩到概率上,同时采用pt来截断,防止概率过大破坏图结构。
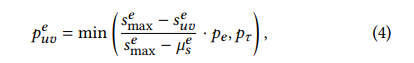
这里的pe是一个超参数,类似于GRACE的超参数,前面这一项就是 adaptive的权重
2.1.2 三种中心性度量

2.2 掩码X,丢弃部分特征(部分维度被掩盖)
从伯努利分布采样随机向量来掩码,这里对于每一个节点 都存在不同的掩码,但是mi 都是通过pif计算的,pif对于所有节点那维度都一样

和丢弃边的思路很像
自己定义:每个节点维度的重要性
pif应该反映 节点第i维度的重要性
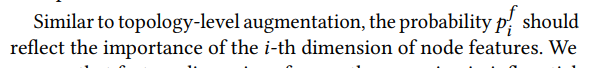
这里算出来的是 所有节点 的 维度重要性,因此 7式第二项是 每个节点的重要性, 第一项是 每个节点中 每一维度的重要性,算出来就是数据集整体上 每一个维度 的重要性(所有节点每一维度加权)

稀疏特征(one-hot): xui是指示向量,比如词袋向量中 哪一维度 存在特征,哪一个维度就是1

对于密集的特征,每一维不是 one-hot,采用value的绝对值
下面采用: 平滑+正则+截断和 A处理的一样

3. 实验
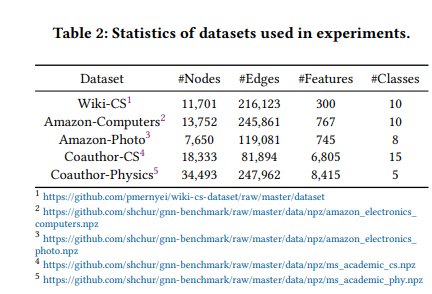
trian等的划分

两层GCN

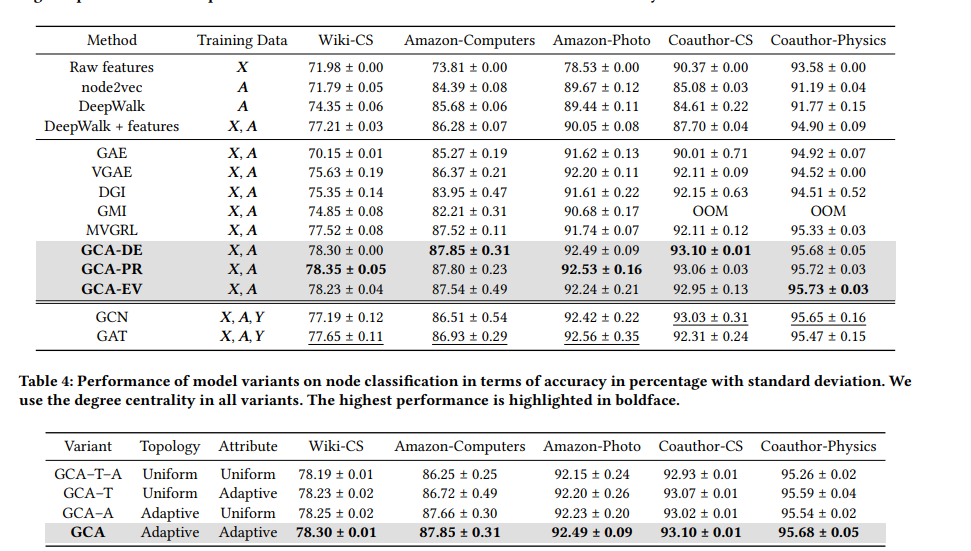
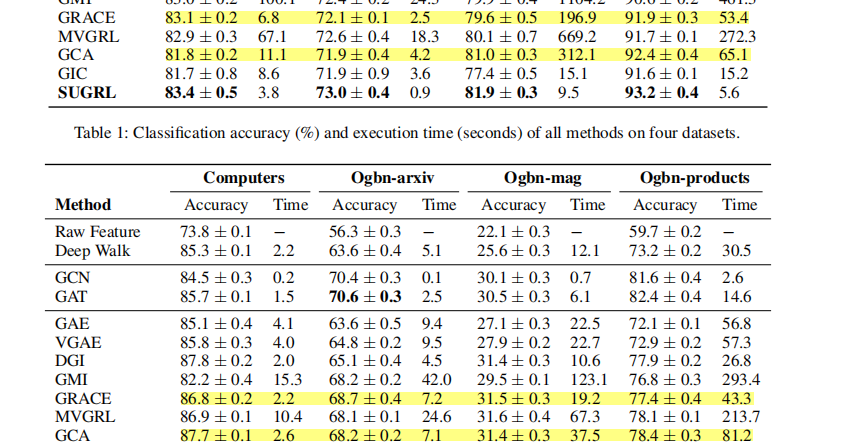
这里并没有采用 cora那三个,不知道是否是实验效果不行
因此我从 SUGRL(AAAI22)找出两个方法,cora效果不行,但是后面有上有下,因此原作者应该是进行了选择。


















 1118
1118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









