







 本文通过Logistic Regression预测Titanic乘客的生还情况。数据预处理包括处理缺失值,如用中位数填充age,删除大部分缺失的cabin数据,用众数填充embarked。分析发现,票价(fare)、仓位(pclass)、性别(sex)和是否独自旅行(TravelAlone)对生还率影响显著。女性和一等舱乘客生还率较高,而独自旅行的乘客生还率较低。
本文通过Logistic Regression预测Titanic乘客的生还情况。数据预处理包括处理缺失值,如用中位数填充age,删除大部分缺失的cabin数据,用众数填充embarked。分析发现,票价(fare)、仓位(pclass)、性别(sex)和是否独自旅行(TravelAlone)对生还率影响显著。女性和一等舱乘客生还率较高,而独自旅行的乘客生还率较低。
1. 导入工具库和数据
import numpy as np
import pandas as pd
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size=14)
import seaborn as sns
sns.set(style="white") #设置seaborn画图的背景为白色
sns.set(style="whitegrid", color_codes=True)
# 将数据读入 DataFrame
df = pd.read_csv("./titanic_data.csv")
# 预览数据
df.head()
| / | pclass | survived | name | sex | age | sibsp | parch | ticket | fare | cabin | embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | 1.0 | Allen, Miss. Elisabeth Walton | female | 29.0000 | 0.0 | 0.0 | 24160 | 211.3375 | B5 | S |
| 1 | 1.0 | 1.0 | Allison, Master. Hudson Trevor | male | 0.9167 | 1.0 | 2.0 | 113781 | 151.5500 | C22 C26 | S |
| 2 | 1.0 | 0.0 | Allison, Miss. Helen Loraine | female | 2.0000 | 1.0 | 2.0 | 113781 | 151.5500 | C22 C26 | S |
| 3 | 1.0 | 0.0 | Allison, Mr. Hudson Joshua Creighton | male | 30.0000 | 1.0 | 2.0 | 113781 | 151.5500 | C22 C26 | S |
| 4 | 1.0 | 0.0 | Allison, Mrs. Hudson J C (Bessie Waldo Daniels) | female | 25.0000 | 1.0 | 2.0 | 113781 | 151.5500 | C22 C26 | S |
data = df.copy()
2. 缺失数据处理
# 查看数据集中各个特征缺失的情况
df.isnull().sum()
pclass 1
survived 1
name 1
sex 1
age 264
sibsp 1
parch 1
ticket 1
fare 2
cabin 1015
embarked 3
dtype: int64
2.1. age
# "age" 缺失的百分比
print('"age" 缺失的百分比 %.2f%%' %((df['age'].isnull().sum()/df.shape[0])*100))
"age" 缺失的百分比 20.15%
年龄的分布情况:
ax = df["age"].hist(bins=15, color='teal', alpha=0.6)
ax.set(xlabel='age')
plt.xlim(-10,85)
plt.show()
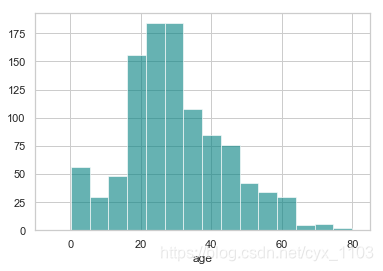
age的偏度不为0, 这里选择使用中间值替代缺失值。
注: 在概率论和统计学中,偏度衡量实数随机变量概率分布的不对称性。偏度的值可以为正,可以为负或者甚至是无法定义。在数量上,偏度为负(负偏态)就意味着在概率密度函数左侧的尾部比右侧的长,绝大多数的值(不一定包括中位数在内)位于平均值的右侧。偏度为正(正偏态)就意味着在概率密度函数右侧的尾部比左侧的长,绝大多数的值(不一定包括中位数)位于平均值的左侧。偏度为零就表示数值相对均匀地分布在平均值的两侧,但不一定意味着其为对称分布。
# age的均值
print('The mean of "Age" is %.2f' %(df["age"].mean(skipna=True)))
# age的中间值
print('The median of "Age" is %.2f' %(df["age"].median(skipna=True)))
The mean of "Age" is 29.88
The median of "Age" is 28.00
data["age"].fillna(df["age"] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9015
9015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









