






 本文通过绘制SVM分类器的学习曲线,分析模型在不同超参数设置下的状态,从欠拟合到过拟合的转变过程,以及如何选择合适的模型。
本文通过绘制SVM分类器的学习曲线,分析模型在不同超参数设置下的状态,从欠拟合到过拟合的转变过程,以及如何选择合适的模型。
以iris数据集合SVM分类器为例,使用sklearn的learning_curve函数绘制分类器的学习曲线,并根据学习曲线判断模型的状态,是欠拟合还是过拟合。
1、加载iris数据集

2、划分训练集和测试集

3、设置超参数C=0.05, gamme=0.1训练SVM模型
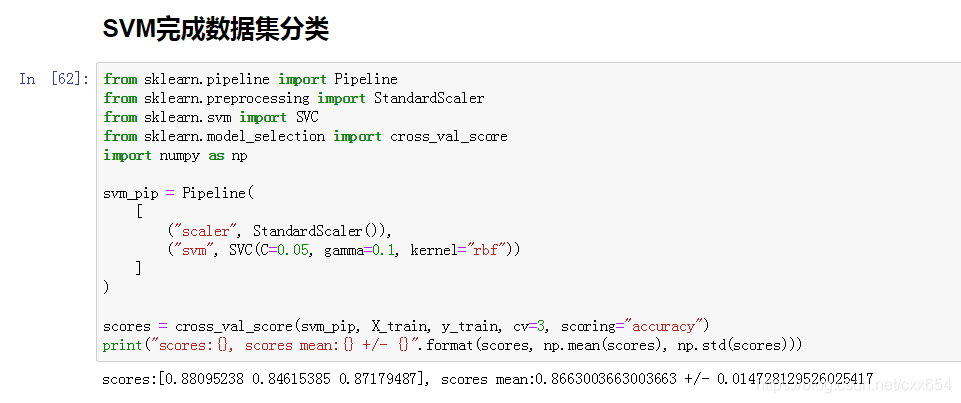
交叉验证结果准确率0.86,结果好像还不错!!!
4、使用learning_curve绘制分类器学习曲线
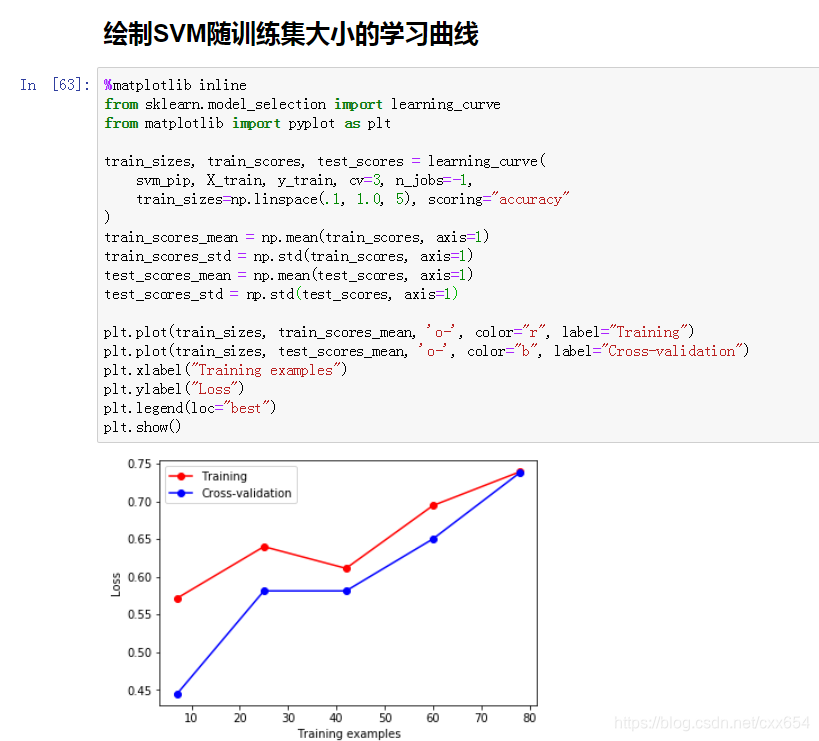
上图中训练准确率和验证准确率同步变化,且准确率没有太大差距,但是在训练集上的准确率只有75%左右,表明模型现在可能处于欠拟合的状态。
5、增加超参数C=10, gamma=1,降低对模型的约束,训练SVM分类器
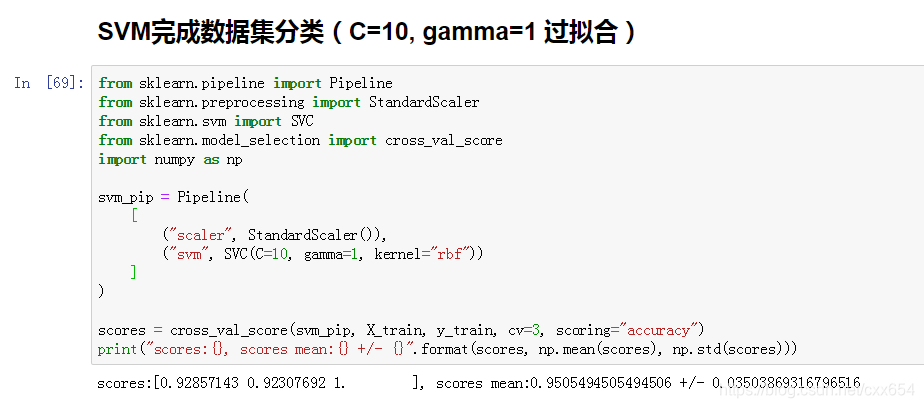
修改超参数后,交叉验证结果95%,说明模型的学习能力变强了,但是现在有可能已经发生了过拟合!!!
6、使用learning_curve绘制分类器学习曲线
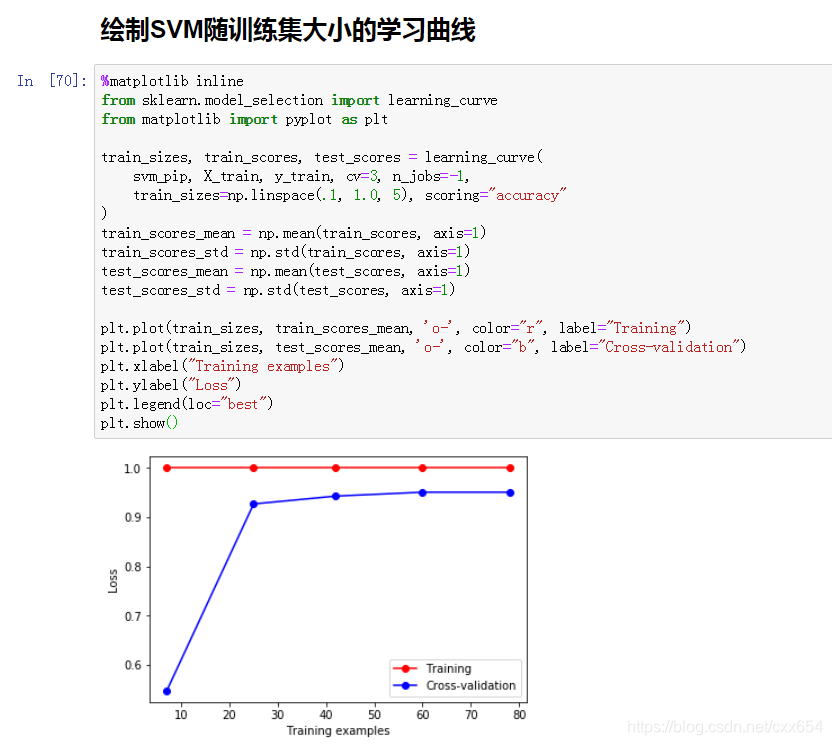
学习曲线显示,随着训练集的增大,训练集上的准确率一直是100%,验证集的准确率最终稳定在93%左右,模型在训练集合验证集上的结果相差较大,可能已经发生了过拟合。
7、设置超参数C=5, gamma=0.1,增强对模型的约束,训练SVM分类器
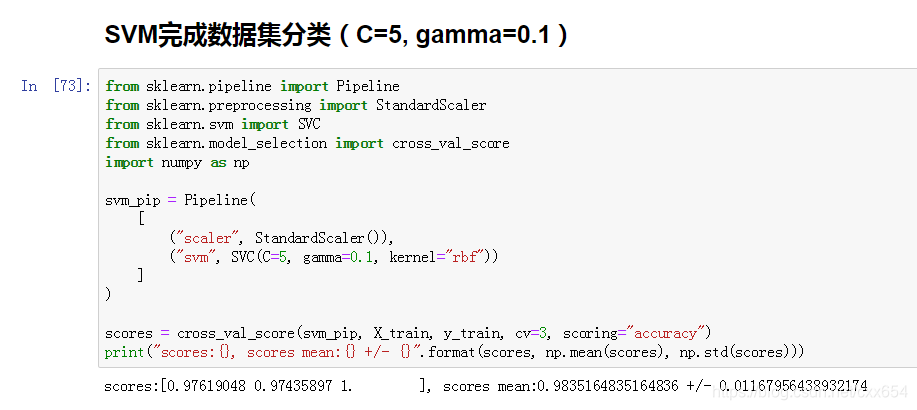
现在交叉验证的结果显示,在验证集上的分类准确率为98%,和第5步一样,现在也可能发生了过拟合的情况,绘制学习曲线看一下!!!
8、使用learning_curve绘制分类器学习曲线
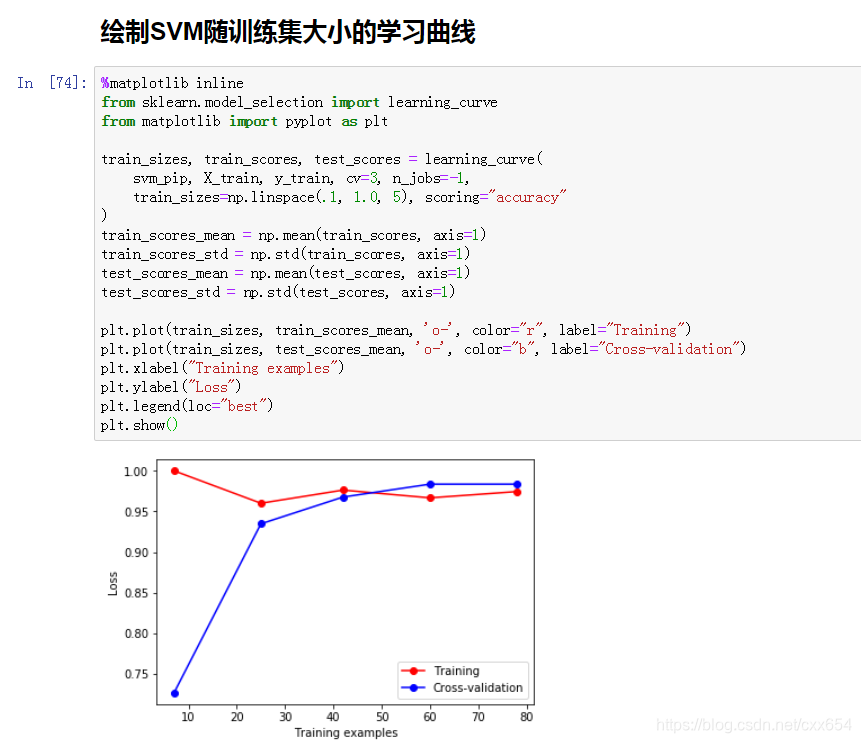
学习曲线看上去还不错,分类器在训练集和验证集上的准确率最终都稳定到了相当的数值,且和前一步交叉验证得到的准确率也相当,使用现在这个模型在测试集上试试看!!!
9、模型在测试集上的表现

模型在测试集上的预测准确率在96%,与之前交叉验证的结果以及学习曲线的最终收敛结果相当,说明模型在未知数据上的泛化效果还不错!!!

















 316
316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









