



 本文深入解析了sklearn中warm_start参数的作用与应用。当warm_start设为True时,模型会在前一次训练的基础上继续训练,避免了重复计算,提高了训练效率。文章通过对比warm_start为True和False时的模型训练过程,展示了该参数如何节省时间和资源。
本文深入解析了sklearn中warm_start参数的作用与应用。当warm_start设为True时,模型会在前一次训练的基础上继续训练,避免了重复计算,提高了训练效率。文章通过对比warm_start为True和False时的模型训练过程,展示了该参数如何节省时间和资源。
warm_start参数用在模型训练过程中,默认是False,从字面上理解就是“从温暖的地方开始”训练模型。
sklearn官网定义:

使用方法:
1、如果warm_start=True就表示就是在模型训练的过程中,在前一阶段的训练结果上继续训练
2、如果warm_start=False就表示从头开始训练模型
在Boosting类的集成算法中,往往通过集成不同数量n_estimators的弱模型来选择最优模型。那么当训练好了一个n_estimators=100的集成模型后,想再次训练一个n_estimators=200的模型,则可以设置warm_start=True,在n_estimators=100模型的基础上接着再训练100个弱模型。如果设置warm_start=False,则表示从头重新训练200个弱模型。设置warm_start可以降低计算量,加速模型训练。下面以训练Gradient Boosting模型为例,展示warm_start参数的用法:
1、模拟训练数据
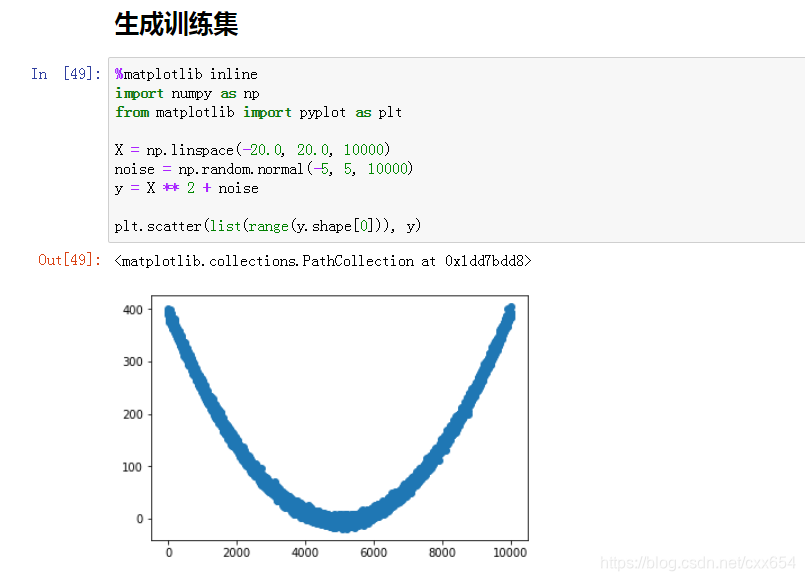
使用二次函数生成10000个数据点。
2、使用warm_start=True分别设置n_estimator=[100, 110, 120, 130, 140, 150, 160, 170, 180, 190]十个集成模型
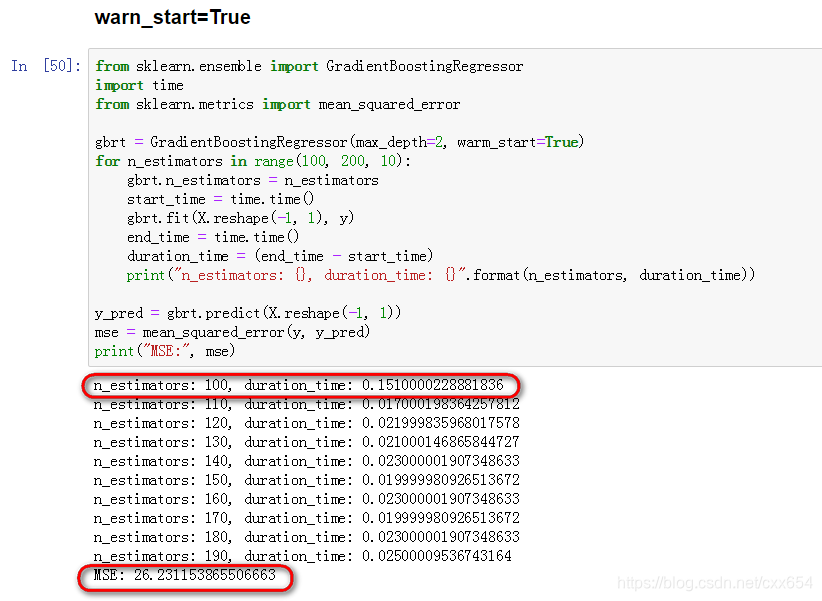
可以看到在训练n_estimators=100模型是,用时是0.151,之后的模型虽然n_estimators在增加,但是训练耗时都非常小,使用最后一个模型在训练集上的MSE是26.23.
3、使用warm_start=False分别设置n_estimator=[100, 110, 120, 130, 140, 150, 160, 170, 180, 190]十个集成模型
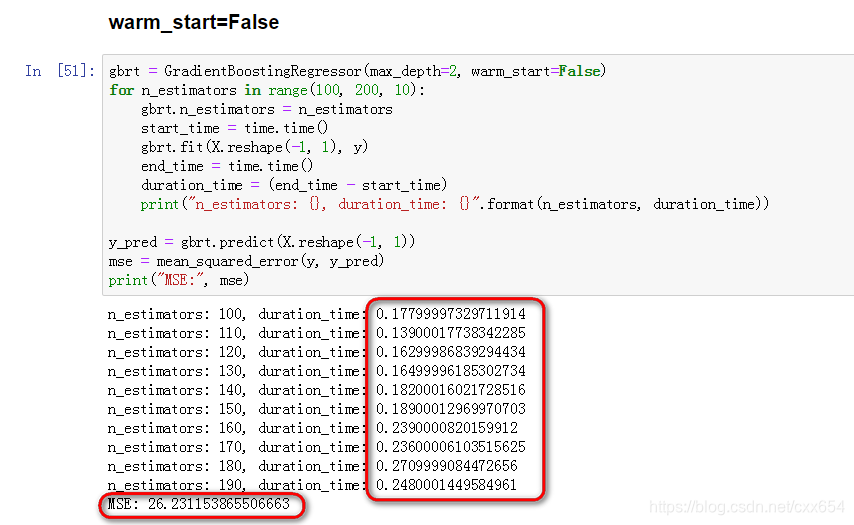
可以看到随着n_estimators数量的增加,模型训练耗时逐渐增加,使用最后一个模型在训练集上的MSE也是26.23.
结论:
warm_start参数在模型训练过程中起作用,当warm_start=True时,模型训练可以在前一阶段的训练结果上进行,而不同从头开始重新训练,可以提升模型的训练速度,且训练结果保持一致。

















 375
375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









