



一种自适应和基于聚类的隐写方法: OSteg
Marwa Saidia,RhoumaRhoumaa,b,RasheedHussainc,OlfaMannaiaaRISC实验室,突尼斯国家工程学院,突尼斯埃尔马纳尔大学,突尼斯市,突尼斯b应用科学 学院,萨拉拉,阿曼苏丹国c信息系统研究所,因诺波利斯大学,鞑靼斯坦,俄罗斯
7.1引言
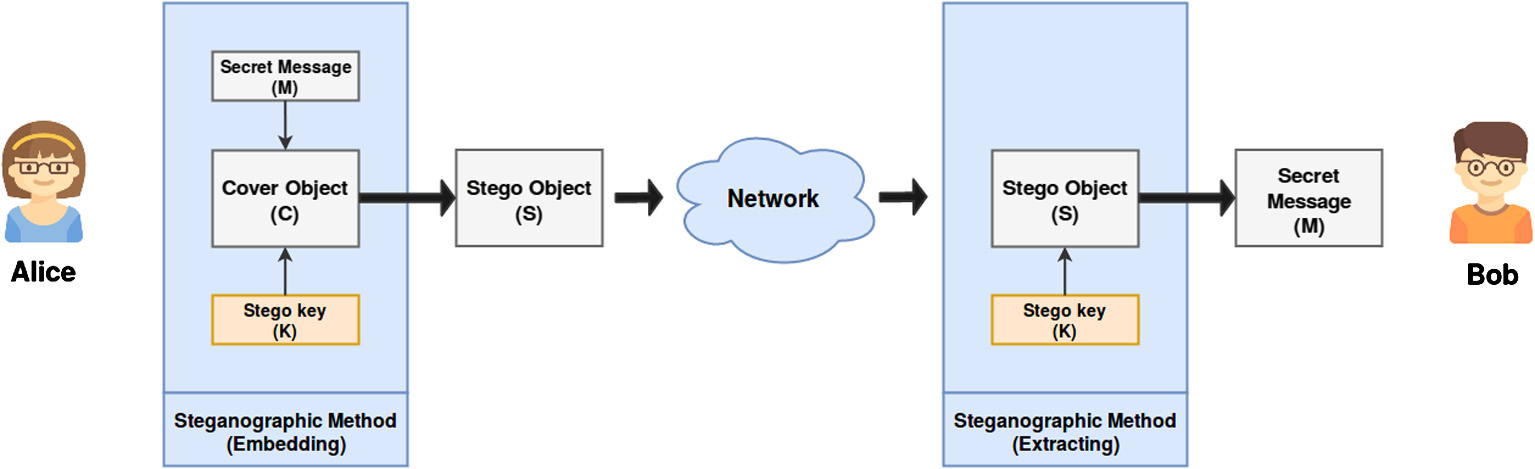
在众多应用中,保护交换信息的隐私至关重要,并已通过多种方法得到广泛研究和建立。其 中两种最常用的方法基于密码学或隐写术。隐写术是将秘密数据隐藏在看似无害的载体中的 过程。图7.1展示了隐写通信的框图。
由于世界上一些政府禁止在通信渠道中使用密码学,因此采用隐写术[1,2]来规避此类 限制。在过去几十年中,多媒体对象,特别是数字图像处理,因其多重属性和层次结构,在 信息安全应用尤其是隐写术方面成为一个有趣且被广泛研究的研究领域。因此,已有多种隐 写方案被提出,涵盖频域[3–5]和空间域[6–8]。
隐写分析是识别可疑对象并确定其是否包含编码载荷(隐写对象)或不包含(载体对象) 的过程。隐写分析通常可分为两类:
针对性隐写分析 :隐写分析者基于对所用数据隐藏方法的深入了解,设计出精确的检测器。通过考虑特定嵌入方法引起的修改和伪影,该学习策略可用于针对性攻击和盲攻击。在分类 方面,其局限性体现在对不同图像格式和不同隐藏方法的非自适应性。
盲隐写分析 :与针对性方案不同,隐写分析者不了解所使用的方法,因此所提出的检测器必 须具有灵活性、可调节性,并能有效分类各种隐写对象,而不论其嵌入函数类型如何。因此, 这些盲攻击主要通过一种学习策略来设计数字媒体隐写术。htt p s://doi.or g /10.1016/B978-0-12-819438-6.00015-3版权所有© 2020ElsevierInc.保留所有权利。
在本章中,我们介绍了一种用于检测隐写对象的盲检测方法的应用。如图7.2所示,给 出了相应检测平台的框图。通常,攻击者将数据分割为两个集合,一个用于训练,另一个用 于测试,随后进行特征提取。目的是对传输图像进行分类,分为两类:载体或含密图像。
值得一提的是,隐写术与隐写分析之间的竞争可以通过隐写者或隐写分析者必须考虑的 一系列防范措施来体现。对于隐写者而言,这些防范措施可以表述如下:
- 嵌入效率越高,修改概率越低,意味着嵌入更改越少,从而安全性越高。
- 失真减少嵌入,其中仅选择导致最小失真的位置进行嵌入。
- 确保原始图像适用于嵌入。
另一方面,隐写分析者通常通过考虑在每次攻击中适用的以下策略,力求放大载体与隐 写之间的差异。
- 改进从隐写图像中估计原始图像的估计方法。攻击者将研究隐写特性是否与估计的载体相 似,以确认或否认秘密消息的存在。
- 在测试图像上进行第二轮嵌入(这将揭示其统计特征 之前是否已被改变),该方法对某些隐写技术(如最低有效位(LSB)嵌入)[10,11]有效。
- 应用滤波方法对测试图像进行去噪。两幅图像的滤波残差之间的差异可提供有效的信息。
当前的空间域隐写方法主要基于设计失真函数来度量嵌入伪影;然而,这些失真函数会 带来更高的计算复杂度,因为必须考虑并确定修改的代价每个像素,从而使嵌入仅限于低成本的像素。为了填补这一空白,提出了OSteg,这是一种 基于对像素块进行聚类并在图像纹理区域中嵌入的简单、高效且有效的方法。为了准确提取 秘密消息,只需应用相同的聚类方法,而无需像现有方法那样交换失真函数。为了评估 OSteg的性能,将其与最先进的方法进行了比较,例如小波获得权重(WOW)、多元高斯 隐写方法(MVG)、空间通用小波相对失真(S‐UNIWARD)以及多元广义高斯方法( MVGG)。
结果表明,OSteg在可检测性方面优于先前的方案,并在保持相同直方图模式的同时, 对隐写分析攻击表现出有效的抵抗能力。在OSteg中,嵌入时我们计算每个图像 individually可隐藏的最佳不可检测载荷。我们将分类器在不同载荷上的训练视为真实场景, 因为在所有图像上嵌入相同载荷而不考虑其纹理是不现实的。这就是OSteg考虑了在图像纹理中自适应隐藏信息的事实。如果纹理复杂度高,则隐藏更多的比特。简而 言之,我们总结本章的主要贡献如下:.
- 提出一种新的、简单且高效的不可检测的、混沌的和自适应的隐写方法,该方法基于聚类 方法,用于安全通信。
- 证明池田系统能够增强所提方法的安全性,因为池田系统的量化输出被用于嵌入过程的不同阶段:i)选择秘密比特的位置,以及ii)填充奇偶校验序列。
- 采用一种新的预处理阶段,该阶段仅通过交换密钥即可保证秘密消息的完美盲提取。
- 保持宿 主图像的原始模式。
- 该算法同时适用于彩色图像和灰度图像。
本章其余部分组织如下。在第7.2节中,我们讨论了图像隐写术中的相关工作。在第7.3 节中,我们提出了一种嵌入方案,该方案由载体图像的预处理阶段、Otsu聚类方法以及利用 混沌系统的随机行为并结合密钥的使用组成。实验结果在第7.4节中给出,其中在彩色图像数 据库[14]上应用了集成分类器[12]和空间和颜色丰富模型特征集(SCRM)[13]。此外, 还将与WOW[15],MVG[16], S-UNIWARD[17],和MVGG[18]等最有效的方法进行了比较。 最后,第7.5节对本章进行总结。
7.2相关工作
在保持载体对象统计特性的同时建立一种自适应的嵌入方法,并最小化隐藏秘密数据所引起 的失真,是设计安全的自适应方法中最有效的策略之一。通过控制嵌入伪影,使伪影仅局限 于丰富/纹理化/噪声区域,并完全排除统计可检测性较高的平滑区域,可以更深入地解释这 一概念。近年来,提出了多种空间自适应隐写方法。这些方案基于最小化一个建模的失真函 数,该函数以代价的形式量化将载体图像更改为隐写图像的影响。其有效性通过所设计函数 与统计不可检测性之间的相关性得以体现。
迄今为止,当前许多先进方法都基于失真函数。例如,WOW隐写术[15]利用方向滤波 残差,为更可预测的像素分配较高的代价,为较不可预测的像素分配较低的代价。空间通用 小波相对失真(S‐UNIWARD)[17]是另一种方法,其代价函数相较于WOW略有调整。事 实上,这两种失真函数在嵌入代价计算阶段是相似的;然而,使用WOW方法计算代价使其 难以应用于其他域的嵌入,例如变换域(DCT/JPEG),而S‐UNIWARD则更能自适应于任意域。
另一种将载体建模为多元高斯(MVG)分布序列的方法在[16]中被提出。所建模载体的参 数被估计后,通过考虑最小化载体图像和隐写图像之间的Kullback‐Leibler(KL)散度,分析 计算每个像素被修改的概率。在[16]中提出了一种经验性的安全性提升方法[18],,作者采 用多元广义高斯(MVGG)替代多元高斯分布(MVG)来建模像素,从而利用更通用的载体模型。
最近,研究人员提出了更多空间域隐写方法。在[19]中,提出了一种基于自适应方向像素值 差分的彩色图像自适应隐写方法。作者尝试通过在一个彩色载体图像上考虑三个方向的边缘: 水平、垂直和对角方向,以提高隐藏容量。所提出的方法根据最大的嵌入容量,为每个颜色通道自适应地选择合适的嵌入方向。在 [20]中,提出了一种基于像素值差分的新型数据隐藏方案,该方案使用3×3块在九像素组 中隐藏数据。在[21]中,引入了一种利用差分和替换机制的高容量隐写方法,它将图像划分 为不重叠的块。对于每个块中的每一个像素,在两个最低有效位上应用最低有效位(LSB)替 换,而在其余位上应用商值差分。在[22]中,提出了一种新颖的 n‐最右位替换图像隐写方 法,用于在图像中隐藏秘密数据。该方法旨在提高峰值信噪比(PSNR)、嵌入容量,避免边 界下降问题(FOBP),并确保对椒盐噪声和RS攻击的鲁棒性。空间数据隐藏方法不仅应通过 统计分析方法进行评估,还应通过分类方法进行评估。隐写分析的数学问题将图像视为隐写 或载体。隐写方法最重要的特征是不可检测性,这比容量或对攻击或变形的鲁棒性更为重要。
因此,研究人员关注如何嵌入敏感数据(数据可以尽可能小),并且他们应通过分类方法证 明隐写分析者是否能正确地将隐写图像与载体图像区分开来。作为数据隐藏方法的设计者, 他希望分类器具有较高的错误概率,并使ROC曲线的UAC尽可能小,以确保所设计的隐写方 法从分类器/隐写分析者的角度来看表现为一个随机过程。
7.3OSteg嵌入
在本节中,我们提出了一种替代的且轻量级的嵌入方法,该方法强调减少嵌入伪影,并将其 限制在图像的纹理区域。抽象地说,嵌入过程(图7.3)分为两部分。最初,我们的算法必须 确定载体图像中的最优像素块,以确保隐藏比特的不可检测性以及秘密消息的完美提取。然 后,
一旦此预处理(preprocessing)步骤完成,便进入所提出方法的第二阶段,其中发送方根 据要嵌入的比特隐藏消息并修改像素值。嵌入过程由准备、Otsu聚类、预处理(伪嵌入)和 有效嵌入组成。这些步骤的细节将在下文给出。
7.3.1准备
首先,将载体图像划分为 n× n重叠(在同一列/行)的像素块。然后计算每个块的标准差 σ, 如图7.4所示。使用公式(7.1)来计算各个块的标准差 σ。
$$
σ= \sqrt{ \frac{1}{n× n} \sum_{i=1}^{n×n} (xi −μ)^2 }, (7.1)
$$

其中,均值用 μ表示,每个 n× n块的标准差通过σi计算,像素值用 xi表示。因此,最终集合 由{σi, i= 1,2,…, K}描述。
7.3.2大津算法聚类
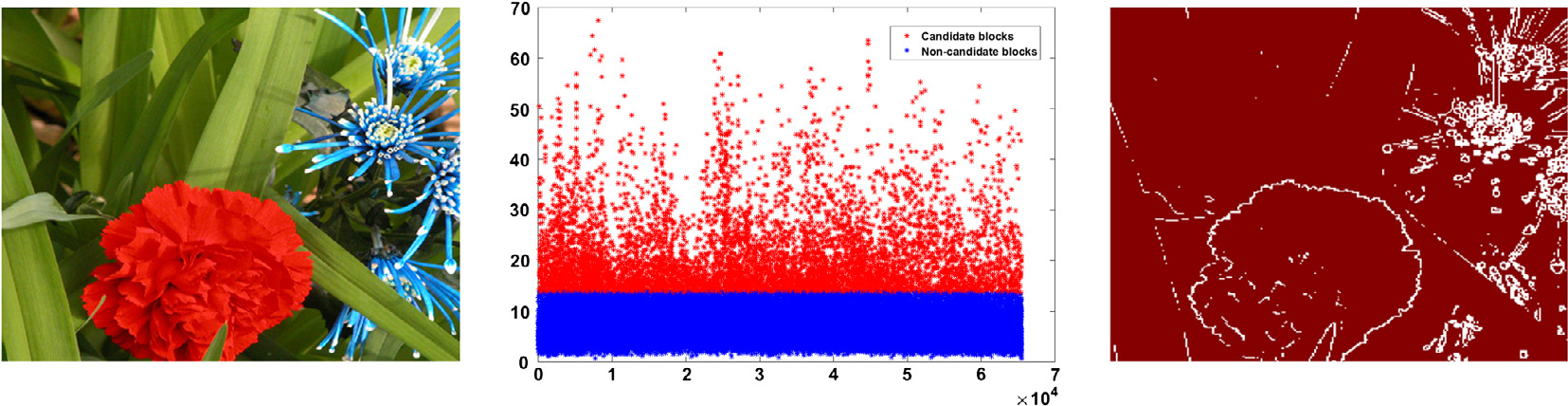
图像分割中最常用的方法之一是大津法[23],该方法通过最大化类间方差来选择全局最优阈值。通常,对于双水平方法而言,灰度级低于阈值的像素将被划分为背景(类别1),其余则划 分为前景(类别2)。上述方法应用于标准差值(而非像大津法那样应用像素值)。最初, 应用大津法将所有图像块计算出的标准差集合划分为两个独立的类别。这一步骤对于识别可 用于嵌入的初步候选块至关重要。该 step 是集合{σi, i= 1,2,…, K}。输出包含通过最优计算阈值 α × ξ分割的两类块,其中α 是一个初始化为1的可变因子,而ξ是由大津算法给出的固定阈值。构造一幅见证图像,用 于将初步候选块(σi> α× ξ)与非候选块(σi α× ξ)区分开。图7.5展示了得到的聚类标 准差和见证图像,其中 white块代表属于具有高 σ的丰富区域的候选像素,而 Red块代表 非候选点。
下文将介绍发送方和接收方所采用步骤的数学与理论描述。双方都将利用大津算法分割 方法来确定用于嵌入/提取秘密消息的候选块。 在准备步骤之后,图像被划分为 n× n块,并将计算出的标准差存储在向量 {σi, i= 1,2,…, K}中,随后构建概率集{pi, i=1,2,…, K}
$$
Pr[std(block)]= Pr(σi)=pi. (7.2)
$$
该概率表示每个σi在图像块内的出现概率 .
本质上,大津分离基于判别准则寻找一个最佳阈值,以最大化所得到的类别之间的可分 性,表示为C0和 C1。在我们的情况下,第一个类别 C0代表具有相对较高 σ的块,这些块将 被视为用于嵌入的初步候选块。第二个类别 C1由非候选块组成,其 σ相对于最佳阈值 ξ较低。 记 L为{σi, i= 1,2,…, K}中两个类别达到最优可分性的层级。换句话说, {σi, i= 1,2,…, K}中的最佳阈值等于层级 L处的标准差 ξ= σL。两个类别 C0和 C1的类出 现概率由下式给出
$$
\begin{cases}
P0= Pr(C0)=\sum_{i=1}^{L} pi, \
P1= Pr(C1)=\sum_{i=L+1}^{K} pi.
\end{cases}
(7.3)
$$
此外,类别 C0和 C1的均值,分别用μ0和μ1表示,分别为
$$
\begin{cases}
μ0=\sum_{i=1}^{L} \frac{i×pi}{P0}, \
μ1=\sum_{i=L+1}^{K} \frac{i×pi}{P1}.
\end{cases}
(7.4)
$$
我们用 σ²B 表示类间方差,它通过不同阈值下各类别的类出现概率加权来计算两个类别之 间的距离。σ²B 可以按如下方式计算
$$
σ^2_B= P0 ×(μ0 − \sum_{i=1}^{K} i ×pi)^2 + P1 ×(μ1 − \sum_{i=1}^{K} i ×pi)^2 . (7.5)
$$
量 $\sum_{i=1}^{K} i×pi$ 是集合{σi, i=1,2,…, K}的总概率均值(记为μT),其表达式为
$$
μT= \sum_{i=1}^{K} i ×pi, (7.6)
$$
并且我们可以轻松地验证
$$
μT= P0 ×μ0+ P1 ×μ1. (7.7)
$$
因此,“类间”方差 σ²B 可以表示为
$$
σ^2_B= P0 × P1 ×(μ1 −μ0)^2. (7.8)
$$
因此,大津算法通过最大化类间方差来搜索对应于最佳阈值 ξ= σL的最优值 L,具体如下:
$$
\argmax_{L,ξ} σ^2_B= \argmax_{L,ξ}(P0 × P1 ×(μ1 −μ0)^2). (7.9)
$$
通过改变 ξ(类似地, L),公式(7.9)中的表达式找到最大的 σ²B ,然后可得到对应于 最优排序 L∗的最佳阈值 ξ∗。最终,两个类别之间的区别得以建立,并通过为属于 C1的嵌 入候选块分配白色,为属于 C0的非候选块分配红色,构造出记为ω的见证图像。见证图像 ω构造如下:
$$
ω=\bigcup ω_k , \text{ where } ω_k=
\begin{cases}
\text{Red}(n× n)\text{pixels} & \text{if Block } k ⊂ C0, \
\text{white}(n× n)\text{pixels} & \text{if Block } k ⊂ C1.
\end{cases}
(7.10)
$$
7.3.3预处理:伪嵌入
此步骤的主要目的是以递归方式使用大津聚类方法,正确且盲式地识别候选块{σi, i= K}在 嵌入后(嵌入伪影可忽略)的类别。除非对候选块执行伪嵌入,否则无法验证该条件。在此 递归搜索的每一轮中,基于在伪嵌入前(原始载体)和嵌入后(隐写)的图像上应用大津法, 生成两个见证图像 ωc和 ωs,直到在两个见证图像中均发现并检测到相同的潜在嵌入块,这 意味着ωc=ωs。
A ±1在一个给定块中,单个像素的嵌入变化会影响该块的标准差 σ,如图7.6所示。同 时也会直接影响该块属于第1类或第2类的隶属关系。
最初,将大津聚类方法应用于在 σ个块上测量的 n× n集合,以确定阈值 ξ。然后开始 对 αk=0= 1进行第一次迭代。从实验角度来看,在第一轮中,为载体图像ξcover计算出的 Otsu阈值与为隐写图像 ξstego计算出的Otsu阈值略有不同。这种现象导致了提取问题(图 7.7:造成缺失的候选块(MD块)或误报块(FP块))。
因此,主要目标是在嵌入或提取的两种情况下均类似地选择候选块,并完全消除将非候 选块误判为候选块(即FP块)的可能性。接下来,关键在于研究选择那些大于组合阈值的块 的可能性,该组合阈值表示为 σ,其中T h= α × ξ为计算得到的Otsu阈值, ξ为一个可配置 因子(见公式(7.11)),其主要目的是在递归预处理过程中从隐写对象中完美地提取秘密消 息。
$$
α_{k+1}= 1+(k ∗ ε), k ∈[0, N]; (7.11)
$$
在每次迭代中,ωc和ωs被比较以检查候选块在两幅见证图像中是否被完全一致地选中。 如果ωs和ωc展示的候选块相同,则最后计算出的 αk值被视为区分的最佳阈值
候选块和非候选块。如果不是这种情况,则制定一个新的阈值,并以递增的 α值进行观察, 记为 αk+1= αk+(k ∗ ε)。因此另一个
嵌入轮次在建模包含所有块的新见证载体图像时进行,从而验证了σi> T h= αk+1 × ξ。在实 验中,我们不妨选择 ε= 0.1。
7.3.4混淆选择:池田系统
在本节中,我们介绍并分析了具有不同特性和不同参数的池田系统,以证明其在信息安全领 域应用的有效性。本质上,我们的算法是一种基于密钥的隐写方法,因此我们选择交换的密 钥仅包含初始条件x0和因子 α。池田系统最初用于生成分配给图像中相邻像素的向量,每 个每像素8位对应于在给定块中根据中心像素检查奇偶性时所使用的8个方向。然后,利用生 成序列的其余部分进行比特填充,以提高本方法对抗攻击的复杂度。池田系统最初在[24] 中提出,并可用以下方程描述
$$
\frac{dx(t)}{dt}= −μx(t)+ m \sin(x(t − T)), (7.12)
$$
其中 x(t)、μ和 m是控制参数。
为求解方程(7.12),需要选择 x的初始条件,记为 x0(t),其位于区间[− T;0]内。然后可 通过每个周期 T中的 N个样本进行近似,如[25]中公式(7.13)所述。因此,在离散化时, T 按如下方式考虑: T= Nh,其中N是样本数N, h是采样步长h。在这种情况下,初始条 件应在单个列向量中表示为 N个值:x0(t)={x0 0, x1 0, x2 0,…, x(N−1) },
$$
x_n(i+ 1)=
\begin{cases}
x_n(i)+ F(x_n(i), x_0(i))× h, \
x_n(i)+(−μx_n(i)+ m \sin(x_0(i)))× h,
\end{cases}
(7.13)
$$
其中μ、 h和 m是控制参数,x0是大小为(N,1)的初始条件向量。对于 N= 3,公式(7.13)可 用矩阵形式描述如下:
$$
\begin{pmatrix}
x_0 & x_1^0 & x_2^0 & x_3^0 \
x_1 & x_2^0 & x_3^0 & f(x_1^0, x_3^0, m, h,μ) \
x_2 & x_3^0 & f(x_1^0, x_3^0, m, h,μ) & f(x_2^0, f(x_1^0, x_3^0, m, h,μ), m, h,μ)
\end{pmatrix}.
(7.14)
$$
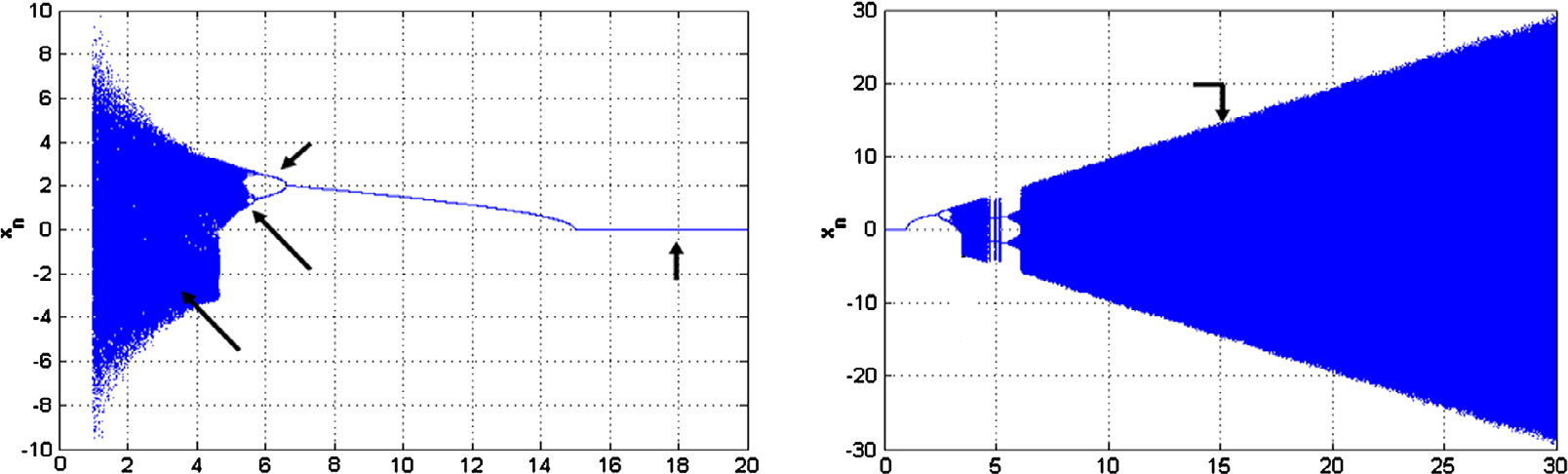
在实验中,我们选择了以下设置: μ= 1, h= 0.5, m= 20和N= 3。值得一提的是,采 用这些参数的取值时,池田系统表现出高度的随机性。该系统的有效性取决于其生成具有长 周期和高效统计特性的随机序列以确保安全性的能力。图7.8显示,随着控制参数μ和 m取 特定值,复杂度随之增加。更准确地说,当μ和 m的取值足够大时,a 超混沌行为(高混沌复杂度)可以被观察到(如图7.8所示)。这种状态有助于OSteg保持更 高的复杂度,并确保生成序列的随机性。表7.1列出了敏感范围并展示了性能‐
 (μ,xn)平面中的单参数分岔图,(B)(m, xn)平面中的单参数分岔图。)
(μ,xn)平面中的单参数分岔图,(B)(m, xn)平面中的单参数分岔图。)
池田系统在其控制参数变化下的性能。换句话说,如果p1 的值随着 ± 10−15发生改变,则 输出序列将与使用 p1原始值生成的初始输出序列完全不同。
| 参数 | 区间 I | pi敏感性 | 子密钥空间 | 密钥空间=∏4 i=1(I pi × S −1 i) |
|---|---|---|---|---|
| p1=μ | [1, 6] | 10−15 | I p1 × S −1 1= 6× 1015 | |
| p2= m | [17, 20.4] | 10−14 | I p2 × S −1 2= 4.4× 1014 | 1.3068× 1048 |
| p3= h | [0.1,0.5] | 10−3 | I p3 × S −1 3= 0.5× 103 | |
| p4= N | [2, 100] | 10−13 | I p4 × S −1 4= 99× 1013 | |
| ## 7.3.5秘密共享密钥和密钥空间 |
为了高效提取秘密消息,两个通信实体需要交换一个表示为的密钥,该密钥包含两个元素: 所用混沌函数的初始条件,表示为x0,以及用于划分两个类别的最佳阈值。
Given a secret key:(x0, αRGB)= ⎧⎪⎪⎨⎪⎪⎩ (x0, αR, α G , αB), (x0,1+(5· 0.1),1+(8· 0.1),1+(6· 0.1))
So the effective sent secret key is:
(x0, f actors)=(x0,5,8,6) (7.15)
Algorithm 1详细描述了预处理阶段,该阶段通过使用伪嵌入并比较载体与隐写图像的见证 图像,递归搜索阈值的最优值。
算法1:PreTreatment(Xc, α)。
数据:覆盖RGB图像: Xc,参数 α和 ε
结果:αopt
1 初始化;
2 α=1(仅用于第一轮);
3 对于 Xc中的每个颜色层执行
4 σc= std(Xc);
5 ξ=大津算法(σc);
6 ωc=见证(ξ, α);
7 Xs=FakeEmbedding(Xc,Wc);
8 σs= std(Xs);
9 ξs=大津算法(σs);
10 ωs=见证(ξs, α);
11 if ωs=ωc then
12 αopt= α;
13 else
14 α= α+ ε;
15 αopt= PreT reatment(Xc, α);
16 end
17 end
如前所述,使用密钥(x0, α)对于安全性和秘密消息的正确提取至关重要。实际上,通 过初始条件x0和一组控制参数μ、m、 h以及 N来参数化的非线性系统(池田系统)主要用 于嵌入阶段的像素随机生成,同时也用于填充过程。在公式(7.16)中,暴力破解攻击尝试的 总次数被估计为
$$
KS= \sum_{k=0}^{8} k C8 × 2^{128−(k+1)×8} , (7.16)
$$
其中 $k C8= \frac{k!}{8!(k−8)!}$ 。
7.3.6有效嵌入
在准备和递归伪嵌入阶段之后,发送方知道秘密向量 ϑ被隐藏的确切候选块。对于每个候选 块,通过迭代混沌(Ikeda)系统[24]生成一个伪随机密钥流。
每个块的子密钥流长度等于 n × n − 1说明在计算给定块的奇偶校验时应考虑的像素。 根据此信息,可判断该候选块所承载的秘密位应为值“1”还是值“0”。这些邻域像素可用 以下偏移和方向(公式(7.17))描述:
$$
\text{Offset}=[{e,w},{n,s},{se,nw},{sw,ne}], (7.17)
$$
其中字母(e,w,n,s)分别代表(东、西、北、南)。
密钥流的一个示例由 ψ表示,如图7.9所示,其中针对两个候选块:ψ i∈[1,2]
$$
ψ_1=[{e, w},{n, s},{se, nw},{sw, ne}]=[{1,1},{1,1},{1,1},{1,1}], (7.18)
$$
$$
ψ_2=[{e, w},{n, s},{se, nw},{sw, ne}]=[{0,1},{0,0},{0,1},{0,1}]. (7.19)
$$
这意味着在进行奇偶校验测试时,应包含西、西北和东北方向的像素。
每个候选块中考虑的二进制序列包含选定的邻域像素和中心像素(pixel of interest c) 的二进制表示的并集(连接)。该并集由以下给出
$$
B_i= \bigcup_{\text{neighbor}} \text{dec2bin}(x_{\text{neighbor}}) \bigcup \text{dec2bin}(x_c) (7.20)
$$
然后,迭代池田系统以生成更多比特,用于检查每个块中长度为128位的二进制序列的 奇偶性。最初,每个块中至少有9个像素,每个像素可表示8比特,使得原始二进制序列的总 长度达到72位。见图7.10。
如前所述,序列的最终长度必须为128比特,这意味着池田额外位的长度在(56,120)之 间:
$$
B’_i = B_i \bigcup \text{Ikeda}{128 - \text{length}(B_i)} , (7.21)
$$
其中 Ikeda{·}表示使用公式(7.13)从池田系统生成的二进制比特。从每个候选块中提取出的 二进制序列B′ i将用于隐藏秘密消息中的一个比特 ϑ,具体取决于序列中1的个数是偶数( $\sum=1 B′ i \mod 2= 0$ )还是奇数( $\sum=1 B′ i \mod 2= 1$ )。
算法2:有效嵌入算法:奇偶校验
数据:B′ i , xc, ϑi
结果: x c
1 如果{( $\sum=1 B′ i \mod 2= 0$ )& ϑi= 0}或{( $\sum=1 B′ i \mod 2= 1$ )& ϑi= 1},则
2 xc= xc
3 否则
4 fliplsb(xc)
5 end
嵌入还取决于 ϑ中实际处理比特的值。满足这两个条件时,给定块的中心像素xc 的值 将保持不变,或其最低有效位将被翻转(fliplsb(xc))。有效嵌入的详细过程如算法2所示。 提取过程可以通过检查序列的奇偶性来执行,即根据算法 B′ i 判断它是奇数还是偶数, 具体遵循算法3。
算法3:提取算法:奇偶校验。
数据: B′ i
结果: ϑi
1 如果( $\sum=1 B′ i \mod 2= 0$ ) 则
2 ϑi= 0;
3 否则
4 ϑi= 1
5 end
7.4实验结果与讨论
在本节中,我们评估OSteg的性能,并将其与现有方案进行比较。实际上,嵌入方案需要使 用经验度量而非信息论方法进行评估。近年来提出的隐写分析方法基于二元分类器来区分载 体对象和含密对象。更具体地说,本文阐述了安全评估指标(错误概率 PE和接收机操作特 性(ROC)曲线)、特征集、所使用的机器学习工具以及图像数据库。
实验在来自[14]的位图(bmp)格式、具有不同纹理的彩色图像数据库上进行。图像被 调整为 512 × 512大小。OSteg与空间域中四种著名的最先进的方案进行了比较:WOW[15], MVG[16],S-UNIWARD[17],和MVGG[18]。此外,采用了为丰富模型设计的空间域特征提 取器[13],该提取器可在[26]获取。
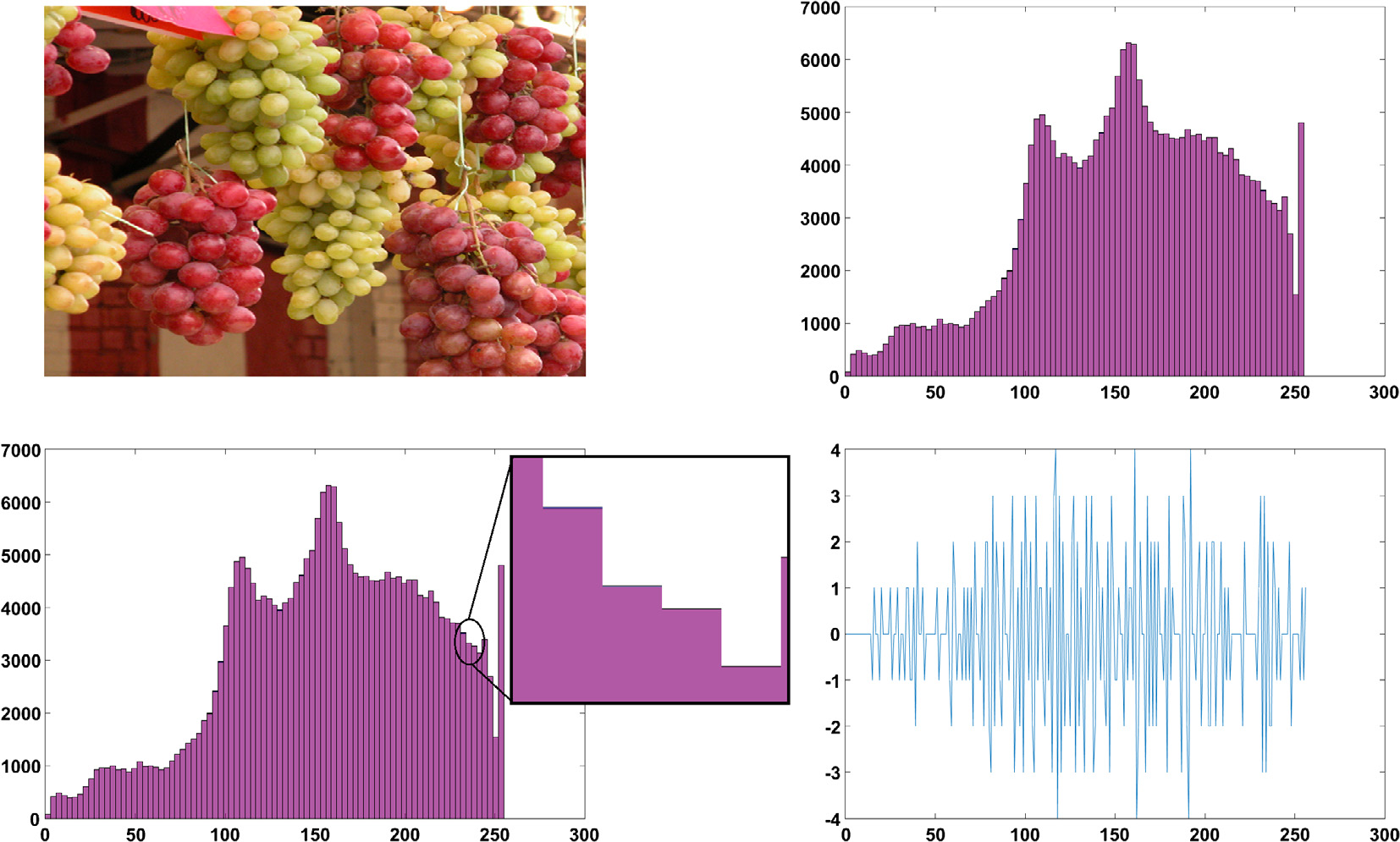
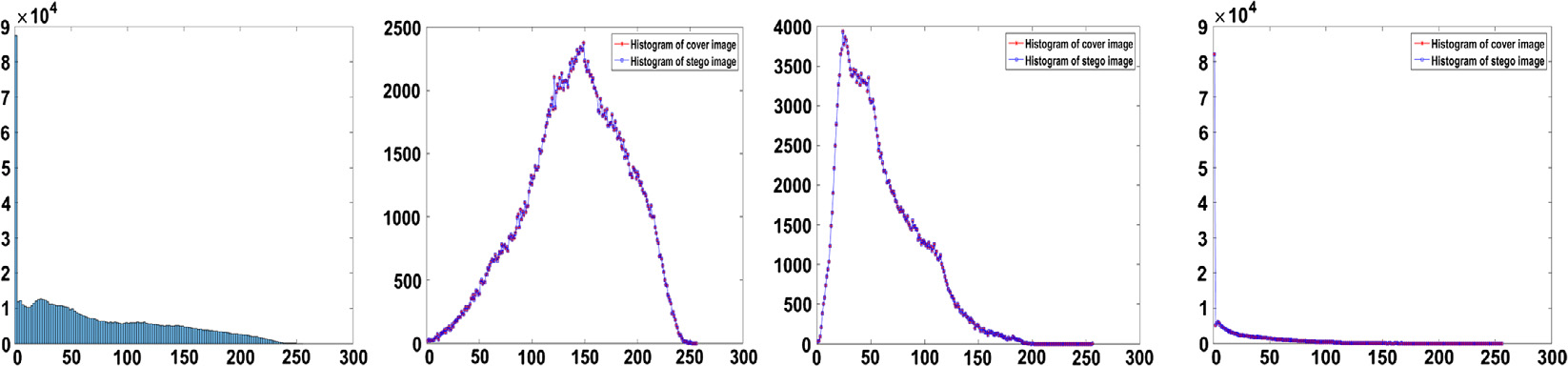
图7.11展示了给定载体图像与其在红色层上的含密版本直方图之间的差异。可以明显 看出,我们的嵌入方法在较低值处保持了直方图的相同模式,而在较高值处则根据载荷和选 定的候选块对直方图进行了轻微改变。
通过图7.12,可以观察到在彩色图像的三个层中携带秘密消息的选定焦点像素。对于每 个层(RGB),展示了有效嵌入位置,并分别绘制了载体和隐写直方图。注意,嵌入方法 OSteg的伪影针对每个层进行了调整,以保持两个直方图之间的相同模式。
为了评估OSteg的性能、安全性和分类准确率,我们使用一个丰富的特征模型 SCRM, 该模型总共包含 18157[27]个维度,专为在空间域中从所有三个颜色通道计算得到的彩色图 像设计。该特征模型由多个子模型组成,用于度量跨颜色通道的像素相邻噪声残差之间的依 赖性。这些依赖性通过对称联合概率分布来表示。 SCRM的构建过程在数据的训练阶段中 进行,在模型维度与检测精度之间建立了满意的权衡,从而使其具有灵活性,能够检测空间 域中的各种嵌入伪影。
在机器学习中,使用集成方法[28]是通过组合准确性较低的分类器来获得高精度分类器 的有效方法。我们采用了文献[12]中提出的集成分类器(ECs),其基学习器为费舍尔线性判 别(FLD),独立训练多次,每次使用从原始训练集中随机抽取的包含 m个样本的子集。 我们通过聚合各个基学习器的决策结果来做出最终决策。
这种操作训练样本的方法在机器学习领域被称为自助聚合,术语bagging源于该过程。 默认情况下,集成方法最小化总的分类错误概率
$$
P_E= \frac{1}{2} ×(P_{FA}+ P_{MD}), (7.22)
$$
其中PFA和 PMD分别表示误报概率和漏检概率。安全性通过在两个独立的集合(194幅图 像:130幅(训练)/64幅(测试))上测量的PE进行平均来评估。表7.2显示了五种不同方法 (包括OSteg)在10个互不重叠的训练和测试子集(分割)上获得的平均 PE。注意,所有 方法的P E都较为稳定,且大致处于[0.4,0.5]范围内,这表明EC无法区分图像中高度丰富纹 理区域的各种变化模式。同时注意到,OSteg的平均PE值最高,这表示使用OSteg进行分类的难度更高。
| 特征:SCRM | 分割1 | 分割2 | 分割3 | 分割4 | 分割5 | 分割6 | 分割7 | 分割8 | 分割9 | 分割10 | 平均PE (+/- 标准差) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| WOW | 0.4844 | 0.4635 | 0.4635 | 0.4740 | 0.4740 | 0.4740 | 0.4844 | 0.4740 | 0.4792 | 0.4792 | 0.4750 (+/- 0.0073) |
| MVG | 0.4896 | 0.4688 | 0.4948 | 0.4844 | 0.4740 | 0.4635 | 0.4688 | 0.4688 | 0.4635 | 0.4844 | 0.4760 (+/- 0.0113) |
| S‐UNIWARD | 0.5000 | 0.5052 | 0.5000 | 0.4844 | 0.5104 | 0.4896 | 0.4948 | 0.4948 | 0.5000 | 0.4688 | 0.4948 (+/- 0.0118) |
| MVGG | 0.4896 | 0.4896 | 0.5000 | 0.4740 | 0.4740 | 0.4844 | 0.4740 | 0.5000 | 0.5208 | 0.4792 | 0.4885 (+/- 0.0151) |
| OSteg | 0.4948 | 0.4740 | 0.5000 | 0.4844 | 0.5365 | 0.5052 | 0.4948 | 0.4948 | 0.4844 | 0.4844 | 0.4953 (+/- 0.0171) |
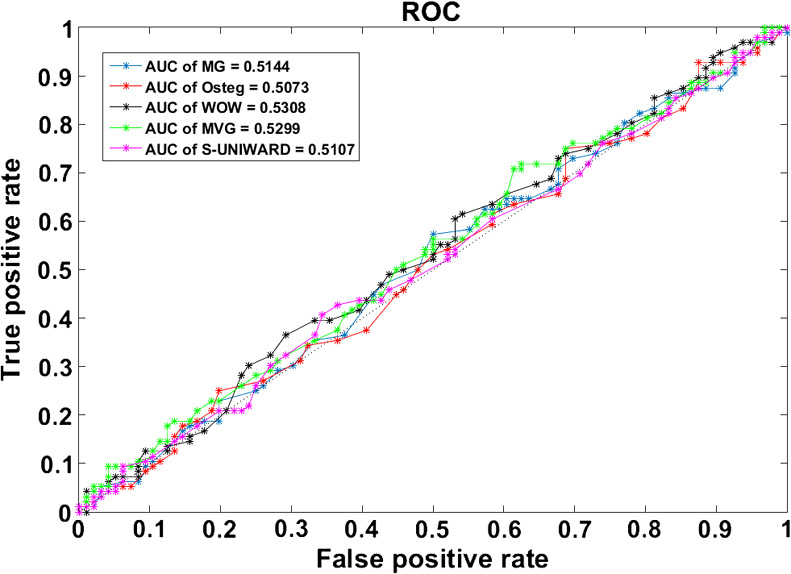
通常,ROC曲线用于评估给定分类器的性能;它绘制了在某个区间内不同分类阈值下的真阳性率与假阳性率的关系[0,1]。从攻击者的角度来看,ROC曲线越接近图中左上角,性能越好,因为在该情况下分类器能够成功区分两个类别(载体,隐写)。图7.13展示了所提方法的ROC,并与文献中四种最著名的空间隐写方法 WOW、MVG、S‐UNIWARD和MVGG进行了对比。该图表明,所提出的方法实现了最小 的曲线下面积和最高的错误概率PE。
从图中可以看出,尽管集成分类器被公认为是确保更高检测精度的有效工具,但在所有 给定的隐写方法下,其在分离载体与隐写对象的两个分布方面表现较差。这一现象表明,由 于所有曲线均接近对角线,分类过程的效果并不比随机猜测更好。
作为评估指标,曲线下面积(AUC)越大,隐写方法的可检测性越高。研究发现,集成 分类器将 OSteg方法分类在与其他方法相同的性能范围内。比较它们的曲线下面积(A UC),可以看出OSteg优于所有其他方法,并且具有最小的曲线下面积(AUC= 0.5073), 从而保证了其不可检测性。
7.5结论
在本章中,我们介绍了一种用于信息隐藏的替代性、轻量级、高效且简单的空间域隐写方法, 称为OSteg。OSteg基于一种聚类方法,用于有效选择具有高不可检测概率的像素块。该嵌 入方法设计为自适应地在每幅图像(各层分别处理:红、绿、蓝层)中隐藏一定数量的比特。 这种自适应性表明集成分类器在检测隐藏数据方面的性能较弱,从而提高了该隐写方法的适 用性。该嵌入方案包含两个主要步骤:第一步的主要作用是准备并选择载体支持可容纳秘密 比特的位置;第二步则根据待嵌入的比特精心调整像素值。由于秘密比特的嵌入是针对每一 层独立进行的,因此OSteg也可适用于灰度图像。修改过程旨在保持彩色图像三个分量(红、 绿、蓝层)的直方图。此外,利用混沌映射来隐藏数据比特,以增强OSteg对抗隐写分析攻 击的安全性。
在分类给定图像集合是载体还是含密图像时的分类概率误差方面,OSteg优于现有的知 名方法,如WOW、MVG、S‐UNIWARD和MVGG。此外,在ROC曲线的AUC方面,其性 能表现相当。进一步地,OSteg对试图发现秘密比特嵌入位置的攻击者具有抗性。这意味着 针对OSteg的隐写分析等同于在大小为$\sum_{k=0}^{8} k C8 × 2^{128−(k+1)×8}$的密钥空间中进行暴力破解攻 击。

















 1141
1141

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









