



使用C语言扩展开发嵌入式软件:一项案例研究
摘要
我们报告了一项工业案例研究,该研究使用C语言及其领域特定扩展(如组件、物理单位、状态机、寄存器和中断)开发智能电表的嵌入式软件。我们发现,这些扩展在管理软件复杂性方面起到了显著作用。它们主要通过支持硬件无关的测试,显著提高了可测试性,这从较低的集成工作量中得到了验证。此外,这些扩展在内存消耗和性能方面并未带来显著开销。本案例研究基于mbeddr,即一种可扩展的C语言版本。而mbeddr本身则构建于MPS语言工作台之上,该语言工作台支持语言和集成开发环境的模块化扩展。
分类与主题描述
D.3.2[可扩展语言]; D.3.4[代码生成]; D.2.3[程序编辑器]; C.3[实时与嵌入式系统]
关键词
嵌入式软件, 语言工程, 语言扩展, 领域特定语言, 案例研究
1. 引言
根据埃伯特和琼斯的说法,[12], 80%的嵌入式系统公司使用C语言实现嵌入式软件。C语言擅长处理底层算法并生成高效的二进制文件,但在定义自定义抽象方面支持有限。这可能导致代码难以理解、维护和扩展。
另一方面,高层建模工具难以有效应对嵌入式软件中重要的底层细节。为解决这一明显矛盾,itemis和fortiss的一个团队开发了mbeddr,一种可扩展的C语言版本,附带与嵌入式软件开发相关的扩展。同时,C语言的原生结构可用于在需要时编写高效的底层代码。有关mbeddr的详细信息,请参见第2节。
Contribution 为了提供实证证据以说明mbeddr支持的语言扩展在多大程度上具有实用性,我们报告了一项关于智能电表(SMT)开发的案例研究。我们的贡献是在一个真实项目中分析这些扩展如何影响嵌入式软件的复杂性、可测试性和运行时开销,以及其开发的工作量。
Audience 我们的目标读者包括语言工程研究人员(关注用以证明其工作的实证数据,或希望了解他们可能解决的问题)以及嵌入式系统开发者(希望了解语言扩展如何在实践中帮助他们)。
Structure 我们根据Runeson等人[41]和Yin[60]提出的案例研究结构来组织本文。首先,在第2节中概述嵌入式软件、语言工程、MPS和mbeddr的背景。在第3节中介绍研究问题和收集的数据。第4节描述了案例研究的相关背景(如Dyba等人[11]所建议),包括软硬件架构、初始制品和开发时间线。第5节概述基于mbeddr的SMT的实现,并说明扩展的使用方法。我们在第6节回答研究问题,并在第7节进行补充性的讨论。最后,分别在第8节和第9节总结相关工作和结论。
2. 背景
2.1 嵌入式软件Engineering
嵌入式软件在时间和内存限制下控制硬件设备。它可以很简单(在具有几KB RAM的8位微处理器上运行的照明控制),也可以很复杂(飞机、导弹和过程控制)。设备中嵌入的软件数量正在增长,其对企业价值也在迅速增加[9]。
根据我们自己的经验以及其他人的经验 [5, 26, 28, 29, 48],,开发嵌入式软件面临诸多挑战。这些挑战包括在产生较小运行时开销的同时实现有意义的抽象(因为单元定价通常限制了资源的增加),解决C语言带来的安全与安保问题(因为许多嵌入式系统也是安全关键型的),与各种元数据的集成(用于分析、部署或参数化),支持测试与监控(因为更新已部署的故障系统通常成本高昂),以及遵循有关需求追溯或文档的开发流程和标准。再加上对更短上市时间和产品线可变性的需求,这使得该领域极具挑战性。
2.2 使用MPS进行语言工程
语言工程指的是构建、扩展和组合通用语言及领域特定语言(DSL)[54]。语言工作台[13, 14]是用于高效实现语言及其集成开发环境(IDEs)的工具。
JetBrains元编程系统(MPS)1是一个开源的语言工作台,全面支持结构、语法、类型系统、转换与代码生成、调试器以及IDE支持(见图2)。MPS依赖于投影式编辑器。投影式编辑器避免了解析语言的具体语法来构建抽象语法树(AST);相反,编辑操作直接修改抽象语法树,而具体语法则从变化的抽象语法树中被渲染(“投影”)出来2 。这意味着除了文本之外,语言还可以使用数学符号、表格和图表等不可解析的表示法 [52]。由于投影式编辑器不会遇到语法歧义,因此能够支持语言组合[50]。传统上,投影式编辑器使用起来较为繁琐,在实践中很少被采用。相比之下,MPS中的文本语法编辑非常接近“常规文本编辑”,并且还支持在投影后的具体语法层面上进行差异合并。[57]中的研究表明,用户在适应之后愿意并能够有效地使用该编辑器。
2.3 C 扩展和mbeddr
mbeddr[55]将投影式编辑应用于嵌入式软件工程。基于MPS构建,它提供了可扩展的C语言版本以及一组预定义扩展,如物理单位、接口与组件、状态机和单元测试。由于这些扩展嵌入在C程序中,用户可以将高层抽象与底层C代码混合使用。开发人员不必强制使用这些扩展;他们可以在认为合适时选择使用。
mbeddr还支持产品线可变性、需求以及形式化验证[34]。mbeddr 在 Eclipse 公共许可证下开源,可从 http://mbeddr.com 获取。多个商业系统已使用 mbeddr 开发。它构成了西门子PLM软件控制工程工具的基础。
得益于MPS,每个mbeddr扩展都是模块化的:无需对C语言进行侵入式修改即可添加新的扩展,并且多个扩展可以在特定程序中无缝组合。扩展提供具体语法、类型系统、执行语义以及IDE支持。通过AST变换将扩展逐步还原为C语言。最终生成文本C代码,并使用现有的(可能是平台特定的)编译器进行编译。
我们鼓励用户使用MPS的功能来定义自己的领域特定的C语言扩展。有关构建语言和语言扩展的详细信息见 [54]和[51]。
3. 案例研究设置
本研究的目的是了解C语言扩展(在mbeddr中实现)在开发嵌入式软件方面的有用程度。我们采用案例研究方法来调查mbeddr在实际商业项目中的应用,因为我们相信只有在这种项目中才能观察到语言扩展的真实风险和益处。专注于单一案例使我们能够对该案例提供大量细节。为了超越这一单一案例提供更深入的见解,我们在第7.4节中进行分析性推广。
为了构建案例研究的结构,我们在第3.1节中提出了四个具体的研究问题。这些问题与第2.1节中讨论的嵌入式软件的一般挑战以及当前SMT案例的关键非功能性需求保持一致。我们在第3.2节中介绍了为评估这些研究问题所收集的数据。
该案例研究并非明确地进行对比。然而,其中隐含的比较对象是嵌入式系统开发领域的实践现状,即使用纯C语言(我们在第8节“相关工作”中简要提到了其他方法,特别是基于模型的方法)。这种比较并不是与一个实际构建的、采用纯C语言的替代实现进行的,因为构建一个生产级质量的第二个实现成本过高。团队所掌握的一个智能电表实现示例由于第4.4节中讨论的原因尚未达到生产就绪状态,因此无法作为有用且公平的比较基准。相反,该比较是分析性的,基于多位作者在使用C语言开发嵌入式系统方面的丰富经验。
最后,本文并未考虑 mbeddr 本身的开发(作为语言工程的一个示例)。我们建议读者参考 [51] 的第10章。
3.1 研究问题
C语言使得为高效管理嵌入式系统的复杂性而创建抽象变得困难。然而,为了确保质量、长期的可维护性以及复用的机会,此类抽象是必要的。因此,第一个研究问题是:
RQ-复杂性 :mbeddr 提供的抽象对于掌握实际嵌入式系统中遇到的复杂性是否有帮助?还需要或可能有哪些有用的额外抽象?
由于硬件依赖、设备上调试的限制以及复杂的时序和资源约束,嵌入式软件的测试具有挑战性。嵌入式软件通常缺少或根本没有自动化单元测试,这对质量、生产率和可维护性造成了问题。此外,由于存在硬件依赖,一些问题只有在调试阶段(即将代码部署到目标设备上运行的过程)才会被发现。因此,我们的第二个问题是:
RQ-测试 :mbeddr 扩展能否帮助对系统进行测试?特别是,是否支持硬件无关测试以实现自动化、持续集成和构建?是否支持增量集成和调试?
大多数嵌入式软件在可用内存、处理器性能或外部时序需求方面都受到约束。在效率与可维护性之间的权衡中,由于单件成本限制,通常优先考虑效率。因此,抽象不能带来过高的开销(“过高”的具体程度取决于上下文)。我们将其归纳为第三个问题:
RQ-开销 :从mbeddr扩展生成的底层C代码是否足够高效,可以部署到实际的嵌入式设备上?
无论一种方法在前三个研究问题上的效果如何,它都不应要求在开发的各个阶段投入显著增加的工作量,否则将不会被采用。这引出了第四个研究问题:
RQ-努力 :使用mbeddr开发嵌入式软件需要多少工作量?
3.2 收集的数据
以下是为回答研究问题而收集的数据,需注意这是一个真实的、产生收入的行业项目,某些期望的数据可能无法获得(参见第7.5节关于可靠性)。
RQ-复杂性 我们考察了在SMT中使用的mbeddr扩展,以及为该项目专门开发的扩展和尚未实现的扩展。我们定性地评估了这些扩展对实施复杂性的影响。
RQ-测试 我们研究了SMT实现的测试覆盖率,并讨论了与测试相关的SMT代码。我们报告了系统调试的经验以及客户预期的认证工作量。
RQ-Overhead 我们测量系统的规模,并将其与目标硬件的资源进行比较。我们分析所实现的性能。我们还分析mbeddr的部分生成器所带来的运行时开销。
RQ-Effort 我们测量并讨论开发SMT所需的工作量,区分系统的实施、测试和调试工作,以及自定义语言扩展的开发工作。
4. 案例研究背景
4.1 什么是智能电表?
智能电表利用模拟前端和模数转换器持续感知市电线路的瞬时电压和电流。根据测得的原始值,它随时间计算各种物理量的能耗数据,最重要的是均方根(均方根)电压和电流、有功功率、无功功率和视在功率、功率因数,以及有功电能和无功电能。生成的数据在液晶显示屏上显示,记录在历史记录中,并针对最大负载、用电时间和计费周期进行分析和评估。此外,智能电表通过网络将这些数据传输到外部世界,还可以通过网络接收命令。智能电表的主要成功标准是达到规定精度,并通过认证过程验证:实现这一目标的前提是底层计算具有实时性能(RQ-开销)。为了具备商业可行性,智能电表必须可靠、低成本,能够演进(随着时间推移和不同变体),并且开发工作量需达到或低于行业平均水平;这体现在RQ-复杂性、RQ-测试和RQ-努力中。本项目所开发的特定智能电表的规格说明见[44]。
4.2 硬件架构
SMT目标硬件由两个在25兆赫兹下运行的MSP430处理器3组成。系统的一个变体使用带有256KB闪存ROM和32KB内存的MSP430F67791,另一个变体使用较小的带有128KB闪存ROM和8KB内存的 MSP430F6736。其中一个处理器执行实时计量,另一个处理器执行高层应用程序逻辑和通信;这种分离确保了实时功能的无干扰执行。两个处理器通过UART接口5上轻量级的MQTT4实现进行通信。应用处理器通过RS485和红外数据接口以及一种称为 DLMS/COSEM的行业专用通信协议与外部世界通信6。系统配备了一个7段LCD显示屏,用于显示系统状态和测量值。硬件的选择独立于软件开发方法,因此实施必须适应该硬件的可用资源(RQ-开销)。
4.3 软件架构
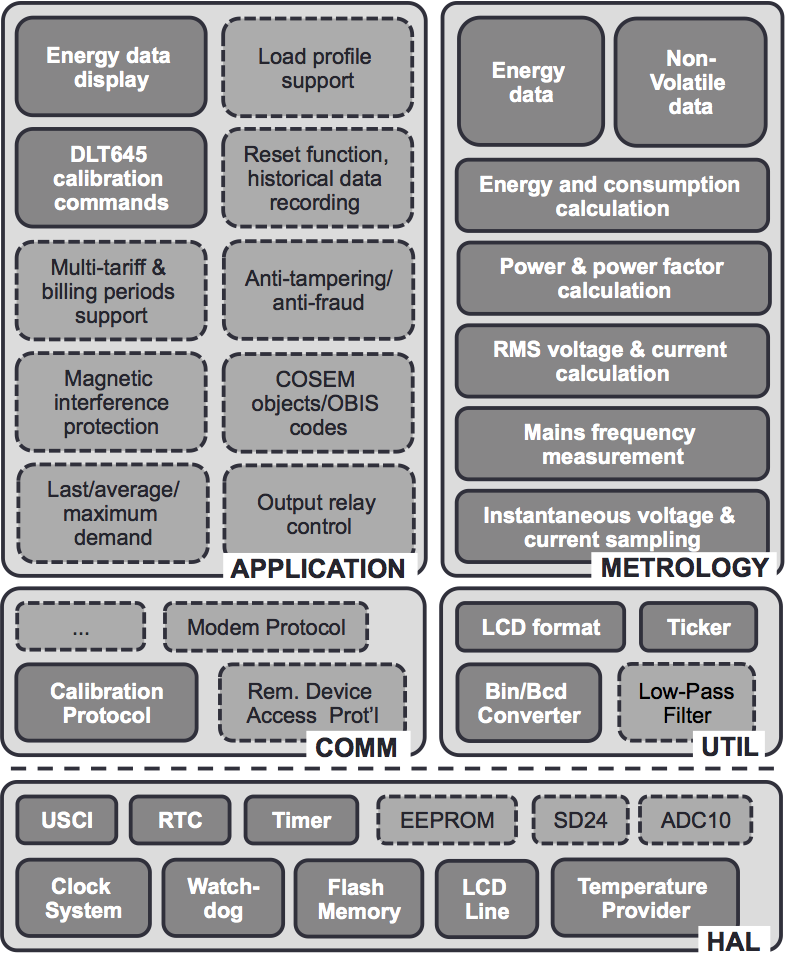
软件功能可以分为两个主要部分,对应于两个处理器:低级测量和高级应用功能。图1展示了更详细的划分。请注意,每个模块中与SMT相关的功能与此论文无关。
处理器上未使用实时操作系统,系统本质上是中断驱动的:由中断触发的后台任务会抢占前台任务,而前台任务则通过主函数周期性地激活。这种方法被称为单线程编程[40]。
中断触发的任务包括读取原始测量值(由ADC中断7触发)以及处理重新校准请求(由 UART-Receive触发)。中断触发的任务会抢占前台任务,并且总是运行至完成,因此具有时间敏感性。正因如此,测量任务仅执行简单的计算,然后通过消息传递将数据交给前台任务,由前台任务执行涉及耗时的除法和平方根运算等更复杂的计算。其他前台任务包括校准以及基于UART-MQTT的处理器间通信。
在性能方面,挑战在于确保背景任务在不到 1 4,096 秒的时间内完成,以维持所需的4096赫兹采样率,并为前台进程留出足够的时间,在其各自的时间预算内(上述计算为一秒)完成任务。
4.4 智能电表示例代码
SMT开发团队可以访问处理器供应商提供的现有 MSP430智能电表示例实现。8该示例智能电表代码 (ESC)旨在作为在MSP430上实现智能电表的一个真实但不完整的实施。ESC仅包含SMT所需功能的一部分,并且需要进行大量扩展(例如,使其能够在两个处理器上运行并支持更灵活的通信栈;参见第6.4节),因此必须深入理解该代码。此外,还提供了一份描述 ESC高层结构的文档。
SMT团队认为ESC的代码质量(可理解性、模块化、可维护性、可测试性及测试覆盖率)无法满足 SMT持续开发的要求;因此决定使用mbeddr构建 SMT的全新实现。除了核心算法来自ESC外,SMT是完全独立开发的新软件。
4.5 开发时间线和过程
开发始于2012年7月。截至2015年2月,大多数所需功能已实现,但开发和认证仍在进行中。该项目使用了一种基于规格说明[44]的迭代流程,该规格说明大约每年更新一次。与目标硬件的集成始于2014年2月,并持续了 2个月。截至目前,项目已耗时300人天(PD),分布在 31个月内,开发人员利用率为50%。由于项目资金、决策关卡和需求获取方面的约束,无法实现全职工作。
4.6 工具
除了mbeddr之外,SMT还使用了gcc和gdb(用于在PC上进行编译和调试)以及IAR EmbeddedWorkbench9和相关的硬件特定编译器。
5. mbeddr SMT实现
5.1 整体结构
图1展示了SMT的结构。每个小方框代表源代码中的一个或多个mbeddr组件。SMT包含一个依赖于硬件的硬件抽象层(HAL),以及独立于硬件的通信栈( COMM)、工具(UTIL)、实际测量功能( METROLOGY)和更高级别的计算及外部通信功能 (APPLICATION)。将系统分为硬件相关和硬件无关的层次是实现组件在PC上进行测试的前提条件(RQ- 测试)。
5.2 系统规模
SMT实现包括部署到目标设备上的代码,以及仅用于测试的代码。表1以生成的 C语言表示部署代码的规模;大约为22,000行非空代码行数(LOC)。额外的测试代码规模大致相当,总计约44,000行代码。尽管与汽车、航空航天或国防系统相比规模较小,但该规模在工业传感器、AUTOSAR基础软件或物联网设备中的软件中具有典型性。
表2显示了重要语言概念的实例数量。由于投影式编辑可以使用非文本表示法,因此难以直接计算行数,我们采用类似于[53]中的转换因子来计算语言结构的代码行数;这导致总计约42,000个非空代码行,规模与生成的 C代码。这表明mbeddr的扩展并不会导致代码大小显著减少:它们在某些地方减少了样板代码,而在其他地方则提高了结构化程度、可读性、可分析性和可维护性。
5.3 使用 mbeddr 的内置扩展
表2 显示,SMT 使用了 mbeddr C 扩展的所有主要功能,表明这些扩展在嵌入式软件中的相关性及其可组合性。本小节的其余部分将较为详细地介绍 mbeddr 的扩展。由于篇幅限制,本小节中的代码示例较为简单,未展示各个扩展的全部特征;有关这些扩展的更多细节和更复杂的示例可参见[55]和[51]。图2展示了 mbeddr 集成开发环境的部分语言和表示法的截图。
代码块 mbeddr 将代码组织为代码块;一个代码块可以被视为(并且通常生成为)单个文件。存在用于单位和转换规则的代码块、用于需求的代码块、用于特征模型的代码块,以及用于(扩展的)C代码的代码块,称为实现模块(每个生成一个 .c 文件和一个 .h 文件)。代码块还充当命名空间,是组织 mbeddr 代码的主要方式。SMT 拥有 382 个实现模块和 46 个其他代码块。
C语言构造 mbeddr 支持几乎所有的 C语言构造(少数例外情况在 [53] 中讨论)。310 个函数、144 个结构体、334 个全局变量和 8,500 个常量在SMT中使用了大量常量,这在嵌入式软件中是典型特征。如下所述,大部分SMT实现被分解为组件;然而,仍有3,636条语句(约22%)保留在函数中。这些主要是数学工具和滤波器、转换、内存安全访问以及测试辅助函数。
组件 组件构成了SMT实现(以及大多数其他基于 mbeddr的系统)的核心。组件是通过接口指定的行为的模块化单元。接口要么定义操作(通过所需端口调用,并通过提供端口实现),要么定义数据项(通过提供端口和所需端口接收和发送)。以下是一个定义了一个操作的接口:
// ADC is the analog-digital converter interface
IADC {
int16 read(uint8 addr)
}
组件提供和需要端口。每个端口都与一个接口相关联。组件在可运行单元中实现与其提供端口相关联的接口的操作,本质上是组件内部的C函数。SMT有80个接口、167个组件和640个可运行单元。以下是一个提供 IADC接口的组件ADCDriver:
component ADCDriver{
provides IADC adc
int16 adc_read(uint8 addr) <= op adc.read {
int16 val = // low level code to read from addr
return val;
}
}
客户端组件现在可以声明一个使用IADC接口的必需端口。可运行单元中的实现代码可以调用该必需端口上的操作:
component CurrentMeasurer{
requires IADC currentADC
internal void measureCurrent(){
int16 current = currentADC.read(CURR_SENSOR_ADDR);
// do something with the measured current value
}
}
组件必须被实例化才能使用,并将其所需的端口连接到其他实例的接口兼容的提供端口。这可以通过图形化方式(在 “C编辑器”中内联)进行编辑,如图2底部窗格所示。
mbeddr 还支持复合组件,从而实现系统的层次化分解(它们包含自己的一组实例)。在 167 个组件中,有 27 个是复合组件。用于实例化、参数化组件实例以及连接其端口的代码共计 1,222 代码行数(用于部署和多个测试设置)。
大多数SMT行为存在于组件中:在总计16,840条语句中,40%位于组件可运行单元中,22%位于普通C函数中(如上所述),34%位于测试用例中;其余4%分布在状态机和其他一些位置。平均每个可运行单元包含11.5行代码。每个可运行单元的圈复杂度较低,平均为1.98。
状态机 状态机用于编码基于状态的行为,它们存在于实现模块内部,与C代码或组件共存。对于任意状态机,可通过多种投影方式提供文本、图形和表格语法。SMT并非主要基于状态的系统,因此状态机的使用仅限于两个示例。其中一个示例实现了通信协议和消息解析,这是状态机的典型应用场景。另一个示例用于驱动显示:由于显示空间有限,其内容会根据各种参数、事件和系统状态发生变化。该状态机跟踪这些变化并更新显示。以下是用于消息解析的状态机的一个高度简化的示例:
statemachine FrameParser initial=idle{
var uint8 idx=0
in event dataReceived(uint8 data) state idle{
entry{ idx=0;}
on dataReceived[data==LEADING_BYTE]->wakeup
}
state wakeup{
on dataReceived[data==START_FLAG]
->receivingFrame { idx++; }
}
state receivingFrame { .. }
}
状态机可以在C语言中用作类型。例如,下面的代码展示了一个类型为FrameParser的局部变量。可以使用内置操作符与它们进行交互:
// create and initialize state machine
FrameParser parser;
parser.init;
// trigger dataReceived event for each byte
for(int i=0; i<data_size; i++){
parser.trigger(dataReceived|data[i]);
}
PhysicalUnits C类型和字面量可以使用物理单位进行注解。可以根据现有单位声明新单位,并定义不同单位之间的转换规则。随后,类型系统将执行单位计算和检查。图3展示了一个示例。
在SMT中,单位提供了仅靠数据类型无法提供的额外检查层级,因为SMT会测量和采样现实世界中的量,并使用其他量进行校准。基于默认提供的7个SI单位,SMT拥有122个单位声明和181条转换规则(如km或mm等不同数量级的单位在mbeddr中被视为不同的单位)。代码中有593个类型被标注了单位(包括局部变量、全局变量、常量或参数),并且有1,294个数值字面量关联了单位。
测试 mbeddr 对断言、单元测试和测试套件提供了一流的支持。以下是包含 FrameParser 状态机的测试用例以及一个测试表达式(表示测试套件)的示例:
testcase testFrameParser1{
FrameParser p;
assert(0) p.isInState(idle);
// invalid byte; stay in idle
parser.trigger(dataReceived|42);
assert(0) p.isInState(idle);
// LEADING_BYTE, go to awakening
parser.trigger(dataReceived|LEADING_BYTE);
assert(0) p.isInState(awakening);
}
testcase testFrameParser2{...}
testcase testFrameParser3{...}
int32 main(int32 argc, char* argv){
return test[testFrameParser1, testFrameParser2, testFrameParser3];
}

6. mbeddr 评估
从表2可以看出,这些扩展被广泛用于应对SMT中的挑战。在本节中,我们将通过评估之前提出的关于mbeddr在 SMT中使用情况的研究问题,对此进行更详细的探讨。
6.1 RQ-复杂性
Improved Structure using Components 组件已被广泛使用,如表2和第5.3节“组件”所述。图1中的所有小方框均已实现为组件。这有助于将系统分解为更小的单位,从而便于独立理解和分析每个组件。接口为接口所指定服务的提供者与消费者之间提供了契约。复合组件支持层次化分解和增量式组合。这有助于提高可理解性,并实现对可变性的结构化处理,进而促进基于平台的架构。
平台和可变性 基于平台的方法依赖于可重用模块,从中开发出相似但不完全相同的系统。自定义代码通常与以SMT组件形式实现的可复用模块相结合。大约80%的代码已被分解到平台中,团队期望未来的项目能够复用该平台的部分或全部内容。参考图1,平台代码包括了全部的HAL、COMM和UTIL,以及部分APPLICATION和METROLOGY。
然而,由于基于该平台构建的产品线由相似但不完全相同的产品组成,因此必须能够表达可变性。在 SMT中,粗粒度变体性通过以不同方式组合组件来实现。组件对多态性(同一接口的不同实现)以及组件的多重实例化(类似于面向对象语言中的对象)的支持使得这一机制成为可能。据开发人员称,这接近于 “乐高TM式软件组装”的构想。例如,通过将计量和通信栈与不同的HAL组件相结合,可以在不同处理器上使用这些栈。
对于更细粒度的可变性,组件支持参数。这些参数在组件定义时声明,并在定义组件实例时赋予具体值。该机制在SMT中得到了广泛应用:50个组件共有 84个参数,设置为324个不同的值。示例包括原始测量值与物理值之间的转换系数。
存在条件(第5.3节,可变性)的使用较为节制;仅使用了117个存在条件来实现细粒度的可变性。这与大多数嵌入式软件(包括ESC)形成对比,后者通常大量使用 #ifdef,导致在可分析性和IDE支持方面出现各种问题 [27, 32]。
带单位的额外类型检查 从ESC中移植的算法包含多个错误,如果类型系统中支持物理单位,这些错误本可以被发现。例如,通过 T = T * T + offset; 对温度T进行“校准”就是明显的错误。显然,假设温度的测量单位是K(开尔文),则右侧单位将是 K2,这无法赋值给左侧的 K。mbeddr对物理单位的支持(第5.3节,物理单位)检测到了此类错误(变量T应声明为 double/K/ T;)。需要注意的是,C语言中使用 typedef定义的基本类型并不足够,因为C语言的类型系统无法进行单位运算(如 K2 ≡ K ∗ K或Ω ≡ V A )。
自定义扩展 第5.4节“消息”中引入的消息数组扩展可防止这些数组中的低级错误,从而消除了意外的复杂性。寄存器和中断的扩展(第5.4节,寄存器和中断)也降低了复杂性,因为它们封装了在目标设备变体和在PC上测试之间切换所需的可变性;代码中无需显式的#ifdef-like可变性。
缺失的扩展 SMT团队已确定需要额外的mbeddr扩展。这一需求本身就是一个挑战验证了mbeddr方法的可行性,因为它表明开发人员意识到语言扩展可以用来解决实际问题。接下来是S MT开发人员提出的一个“愿望清单”。
针对队列、栈和环形缓冲区的扩展,若能具有极低的开销和面向对象风格语法(如stack.pop),将非常有用。对Q格式定点数的支持将有助于没有浮点运算单元的平台。SMT团队还建议增加用于测试和调试的扩展,其中一些已在SMT中进行了原型开发。这些扩展包括用于信号分析的工具(将信号序列绘制成图形)、在目标系统中对信号序列进行跟踪(插桩代码、UART通信、在主机 PC上的可视化/评估),以及性能分析(通过端口引脚翻转、主机 PC上的示波器)。
SMT开发人员建议增加一些检查,其中部分由类型系统完成,另一部分通过可选生成的代码在运行时执行:(1)检测/避免对RAM变量进行不必要的初始化,以防止启动期间发生看门狗复位;(2)检测缺失的volatile使用;(3)检测有符号整数自动提升为无符号整数的情况;(4)检测对字节对齐(奇数)内存地址的字访问。
最后,提出了一种用于指定初始化参数及参数之间约束的语言,以简化组件配置。目前,使用基本的 C语言类型或结构体来实现此目的。
这些扩展都不是SMT特有的,因此它们将作为 mbeddr发展的一部分进行开发。其中一些(如环形缓冲区和栈)在撰写本文时已经实现。
未使用的 mbeddr 扩展 mbeddr 包含的扩展比 S MT 中使用的更多。其中最重要的两个是需求与需求追溯 [56] 以及形式化验证 [34]。需求和需求追溯未被使用,因为客户未提出该要求。验证支持本可用于静态检查接口契约,但团队因对形式化验证不熟悉,并认为单元测试已足以保证质量,故未采用。不过,这两个扩展在其他项目中已成功应用。特别是静态验证,目前已成为西门子PLMSoftware开发的控制工程工具的重要组成部分。
Notation and Readability 一旦建立了正确的抽象,MPS的投影式编辑器便可通过直观的符号将其渲染出来。SMT在某些地方使用了数学符号,例如求和、平方根或分数线符号。此外,组件实例和连接器以图形化方式渲染(类似于 UML复合结构图,参见图2):SMT共有72个实例配置,平均每个包含5个实例和8个连接器(规模最大的四分之一配置包含10个实例和19个连接器),用于设置测试场景。这些结构更易于理解使用易于识别的一等语言构造来表示领域相关概念(如寄存器、消息定义或状态机),并结合图形化表示法,通常可以提高可读性。
关于RQ-复杂性,我们总结如下:开发人员自然而然地从扩展的角度进行思考,并在项目期间提出了额外的扩展建议。mbeddr组件有助于构建整体架构,并实现复用和可配置性。mbeddr扩展有助于实现强静态检查,提高可读性,并帮助避免低级错误。
6.2 RQ-测试
组件与测试 组件化简化了测试,因为可以对定义明确的行为单元进行独立的单元测试。107个测试用例、2400个断言以及56个特定测试组件(包括9个桩模块和8个模拟对象)使得关键的计量子系统实现了80%的测试覆盖率(行覆盖率),而较不复杂的应用部分则达到了约40%的覆盖率。10工业界当前的实践(在安全关键领域之外)所实现的单元测试覆盖率要低得多,并且严重依赖硬件在环测试,通常是针对整个系统,并且经常手动执行。[43]
自动化、硬件无关测试 硬件无关测试是指能够在开发者PC和持续集成(CI)服务器上运行功能需求的单元测试。在SMT中,这通过使用组件和接口隔离硬件相关功能来实现。高效地测试SMT需要硬件无关测试,原因有两个。首先,SMT硬件直到软件开发开始后才可用。其次,它支持在CI服务器上进行持续构建、测试和集成。后者在软件工程中已被广泛采用,并已知能够提高质量并减少集成时间[15]。然而,在嵌入式软件中,这种方法仍然很少被使用(敏捷流程总体上也是如此[43])。在SMT中,所有硬件无关的部分都通过Teamcity CI服务器进行了持续构建、测试和集成11。
对测试的关注取得了成效:集成仅占总工作量的 13%。对于嵌入式软件而言,这一比例非常低:斯齐帕诺维茨[47]认为该比例为40%到50%,而布罗伊则称集成为“主要挑战”和“噩梦”[5]。
一种常见的硬件无关测试替代方案是使用模拟器。如果可用,模拟器由硬件供应商提供,并忠实地模拟硬件行为在软件中模拟硬件,执行特定于硬件的二进制文件。虽然这对某些测试很有用,但并不能替代在CI服务器上进行的自动化单元测试:仿真器很难集成到CI构建过程中,因为它们通常并未设计为以自动化、非交互的方式使用。
测试硬件相关部分 尽管如此,一些涉及硬件特性的测试仍在PC上执行,利用了寄存器和中断扩展所提供的增强可测试性:两者均可生成以模拟专用寄存器和中断的发生。这使得测试工作量降低至16%,因为以前需要手动执行的硬件特定测试现在可以作为自动化测试套件的一部分来运行。
某些方面(例如时序)必须在目标设备可用后手动进行测试。在一次测试中,由于串行接口上的校验和错误导致测试失败。基于示波器的底层调试发现,最后一个字节未被发送,原因是时序问题:触发每个字节发送的发送使能中断在最后一个字节发送之前已被禁用。通常,基于组件的增量集成有助于识别出引起问题的(硬件相关)组件。
增量式集成与调试 错误是指在PC端完成实施后,到使其在目标设备上运行之间所需的步骤。尽管进行了广泛的硬件无关测试,这一过程仍然具有挑战性:由于时序和资源分配的相互作用以及硬件配置问题,整个系统中可能会出现各种各样的问题。
通过分步调试系统,可以简化对这类问题的排查。最初仅部署一个最小系统,该系统仅执行单一任务且所需资源有限。然后逐步增量式地扩展至完整功能。出现的问题必然与上一步新增的部分相关。也可以通过迭代部署不同子集(而非线性地扩展完整系统)来缩小问题原因的范围。组件有助于这一过程,因为很容易将组件的子集组合起来用于调试。例如,考虑处理器间通信:它同时传输测量数据和校准数据。在完全部署的系统中,这两类数据通过单一连接进行多路复用。调试分为四个步骤:仅校准数据、仅测量数据、然后两者同时传输,最后两者同时传输并结合实际计量(这会改变时序)。
调试最小SMT系统的过程非常顺利,仅发现了一个问题:针对16位目标缺少了16位整数与32位整数之间的显式类型转换。这与团队以往的经验形成鲜明对比,过去集成通常意味着开发人员需要逐个修复漏洞才能推进工作。
认证 SMT设备必须由政府机构针对其准确性进行认证。这是通过对成品施加校准信号并测量所达到的精度来完成的。目前尚未进行认证。然而,与认证相关的信号场景是已知的,并且通过软件在环测试持续进行验证。这增强了对认证准备就绪的信心,从而避免了过早(且昂贵)的认证尝试。通过将这些测试纳入回归测试套件,还可以在软件演进过程中避免影响认证的问题。测试通过使用桩和模拟组件替代部分驱动程序来实现。特别是,ADC驱动程序被一个信号模拟器取代,该模拟器随时间生成变化的值。断言用于提示不准确的情况。
关于RQ-测试,我们将SMT经验总结如下:mbeddr组件通过清晰的接口和小型单元在提高可测试性方面发挥了关键作用,使核心组件的测试覆盖率达到80%。自定义扩展和组件有助于实现硬件无关测试、持续集成以及认证过程的自动化预演。组件带来的模块化有助于在调试期间追踪问题。
6.3 RQ-开销
内存消耗 在内存消耗方面,mbeddr生成的二进制文件足够小,适用于目标设备:计量处理器的完整配置系统使用了16,736字节的闪存ROM和4,321字节的RAM。对于应用处理器,这些数值分别为10,978字节和2,917字节(这两种情况均指未优化的调试代码,这意味着生产二进制文件会更小)。可用资源为512 KB闪存和32 KB RAM,因此未来仍有扩展空间。请注意,程序运行期间未使用动态内存分配(malloc、free),所有内存均在运行时静态获取或位于栈上,这在嵌入式系统中是常见做法。
组件化在内存消耗方面也很有用:由于系统被划分为具有明确依赖关系的(相对)小型组件,并且由于 mbeddr 组件生成器不会为未作为特定可执行文件部分实例化的组件生成 C代码,因此可以避免部署不必要的功能,避免消耗特定产品变体不需要的资源。反过来说,组件也会带来一些开销:二进制文件使用了 2,804 字节的 ROM 和 2,647 字节的 RAM 来存储表示组件实例及其连接的数据结构和指针。虽然这对 S MT 不是问题,但附录B讨论了如何减少这种开销。
| 开发任务 | 工作量 | 总计百分比 |
|---|---|---|
|
实施
重新实现 附加功能 测试,模拟器 集成与调试 自定义语言扩展 |
200 PD
145 PD 55 PD 48 PD 38 人天 14 人天 |
66%
48% 18% 16% 13% 5% |
表3. SMT开发工作量的分解。
性能 我们根据开销对语言扩展进行分类,并确定了三个类别。在接下来的段落中,我们将表2中mbeddr所使用的语言结构与这些类别相关联。
第一类没有运行时开销,因为相应的扩展在代码生成之前已被移除。在SMT中,物理单位(仅与类型系统相关)和产品线可变性(存在条件被静态求值,类似于#ifdef)属于此类别。
第二类的代码量与手动编写的惯用C语言代码相似。大多数mbeddr和自定义扩展属于此类别:状态机被简化为基于开关的实现;寄存器变为基于#define定义的直接内存访问;中断被简化为中断处理函数;协议消息定义被简化为其原生的、基于数组访问的形式;所有C语言构造均无变化地转换为C 代码文本。
第三类需要生成更复杂的代码结构,并导致一些性能开销。在SMT中,组件是唯一属于此类别的扩展:接口多态性通过函数指针实现,由于间接寻址而引入了性能损失。附录B讨论了现有和未来的优化方法以减少这种开销。由于这些优化以灵活性换取效率,并且在目标硬件上运行SMT软件时无需这些优化,因此团队决定不使用它们。
运行时性能对于SMT实现4096赫兹采样率至关重要,这直接影响测量精度。该实施达到了所需的采样率,证明了其运行时开销极小。关于开销,我们总结如下: SMT 的内存需求足够低,可以在目标硬件上运行,并且还有扩展空间。组件化能够仅部署变体所需的功功能,从而节约资源。性能开销足够低,可以在给定的硬件上实现所需的 4096赫兹采样率。
6.4 RQ-努力
开发与集成SMT软件总共消耗了300人天(PDs)。表 3将这300人日按不同的开发任务进行了分解。
总计200人天的工作量中,有66%用于SMT的实现。在mbeddr中实现ESC功能的可维护和可扩展的实施需要48%(145人天)。由于当时没有可用的C代码导入工具,即使是本应从ESC重用的算法代码也不得不重新输入到mbeddr中。现在已有导入工具;然而,团队估计,即使该工具早些可用,也仅能节省约10人天,因为如前所述,ESC的绝大部分必须完全重做。
整体工作量的18%(55人日)用于实现规格说明中超出ESC所需的附加功能。在两个处理器上运行的能力,•两个处理器之间的通信,•提高了通信基础设施的灵活性(校准数据与MQTT之间的多路复用,以及RS485和IrDa两种通信技术),•一个I2C总线驱动程序,•一个EEPROM控制器,•所需DLMS/COSEM消息的一个子集•以及额外的应用程序功能,如历史数据记录和复位功能。
由于此时核心系统已经采用mbeddr开发并被结构化为组件,因此集成这一附加功能非常直接;我们认为这 55人日的附加功能工作量是一个较低的数字。在这55 人日中,约有20人日用于MQTT实现。一旦完成这些工作,在两个处理器上的分布仅花费了几个小时。
总工作量的16%(48人日)用于单元和集成测试以及所需的测试框架,特别是模拟组件和信号发生器组件。
总工作量的13%(38人日)用于在目标硬件上的集成与调试,以及非功能性属性(性能、资源消耗)的验证。如前所述,对于嵌入式软件而言,这一比例非常低。团队认为这归功于组件化以及自定义寄存器和中断扩展,使得广泛的自动化测试成为可能,并促进了增量调试。
构建自定义扩展花费了5%的工作量(即14个人日)。考虑到这些扩展在测试与可维护性方面的优势,S MT团队认为这项工作量投入是值得的。此外,该数字足够小,使得自定义扩展成为实际项目中的可行选择。
基于 mbeddr 的承诺以及团队对 mbeddr 的一些初步经验,最初估计 SMT 的基于 mbeddr 的实现总工作量为 250 至 290 人天。最终 300 人天的工作量仅略高于该估算值,因此在开发过程中没有出现导致工作量增加的意外情况,mbeddr 如约交付:最终的软件具有比纯C更好的结构和更高的测试覆盖率。
关于RQ-努力,我们得出结论:附加功能、集成与调试的工作量低于嵌入式软件中的常见水平。构建扩展的工作量足够低,可以在实际项目中被吸收。总体而言,使用mbeddr不会导致显著的工作量超支,同时能够产生结构更好的软件。
7. 讨论
在前面的章节中,我们已经了解了 mbeddr 提供的 C 语言扩展如何影响商用智能电表设备开发过程中的复杂性、可测试性、开销和工作量。在本节中,我们将结果置于更广泛的视角下进行讨论。
7.1 内部有效性威胁
从内部有效性的角度来看,关键问题在于我们的研究结果是否可信。
偏倚 影响此问题的一个因素是由于作者自身参与了该案例研究而产生的偏倚。第一和第三作者是mbeddr的主要创建者,第四作者在工业界领导了SMT项目,并具有明显的商业利益。为了抵消这种偏倚,我们专注于可以客观测量的方面(规模、概念数量、工作量、开销),不仅针对本案例研究,也包括其他(未来的)项目。此外,第二作者与mbeddr及案例研究中涉及的公司均无关联,其主要因其在开展定性研究方面的经验而被引入。
Team Expertise 为了阐明团队对案例研究结果的潜在影响,我们描述了团队的背景和专业能力:该团队由一名高级开发人员领导,他在软件工程、面向对象以及使用Java和C语言进行应用开发方面拥有 15+年的经验。他在嵌入式硬件和使用C语言进行嵌入式软件开发方面具有扎实的背景。该团队在SMT领域没有经验。项目开始时,SMT团队对mbeddr语言或工具没有显著经验,但理解扩展背后的抽象概念(组件、状态机、产品线);因此所需的教育背景较少。然而,SMT团队可以获得mbeddr开发者的培训与支持。
示例智能电表代码 另一个可能影响结果的因素是ESC。一方面,它帮助团队理解SMT功能的具体细节(从而减少工作量)。另一方面,正如第6.4节中提到的,该团队没有智能电表方面的经验,团队估计200个人日的实施工作量中有30%到40%是由于缺乏专业知识造成的。我们估计ESC整体工作量的净效应大致为中性。在架构、结构、测试或性能考虑方面,mbeddr SMT实现是新的软件:ESC的不可用不会产生重大影响。
7.2 结论效度
结论效度提出了一个问题:我们的研究结果总体上是积极的,并支持采用语言扩展,这是否有合理的explanation?
mbeddr 的设计 mbeddr 的 C 扩展 特别地 设计 用于实现本案例研究中报告的效益。因此,mbeddr 的设计原理构成了该案例研究结果的理论解释。有关此设计原理的详细描述,请参见[51]。
符号的认知维度 这些扩展根据格林的符号认知维度[18],(一组既定的语言评估标准)改进了C语言。扩展直接提升了五个维度。抽象梯度通过逐步向C语言添加扩展得以实现:抽象级别被逐步提高。用户无需被迫将所有内容编码为过低或过高的语言层次,而是可以针对每个具体情况使用(或开发)合适的扩展。添加领域特定的抽象和表示法增强了代码与领域之间的映射紧密性。额外的抽象和表示法也是调整语言(或特定程序)冗长/简洁权衡的一种方式。通常情况下,更简洁的程序更好,因为它表现出更低的复杂性[17],,前提是所使用的语言结构为所有相关人员所熟知。使用这些扩展减少了易错性,因为程序员可以忽略与当前问题无关的底层细节。最后,渐进式评估因IDE支持和良好的错误消息而得到改善;这两点在mbeddr中被高度重视,通常比普通C IDE中的支持更有帮助(部分原因是预处理器使得在普通C中难以实现这一点)。
概念与语言 我们所测量到的成功可能还有另一种解释: mbeddr的概念(如适当的模块化)起到了作用,而 mbeddr的语言扩展并非必需。但SMT团队持怀疑态度:如果没有这些扩展,将需要极大的自律性,而且团队非常认可这些扩展与C语言本身的无缝集成以及所提供的工具支持。事实上,其中一位开发人员此前曾在纯C语言中开发过面向组件的软件,他表示,将这些抽象作为一等语言构造,在生产率方面带来了巨大差异:“mbeddr让正确的方式变得更简单。如果没有语言和工具支持,你总会倾向于走错误的路,而且只能靠自己避免犯错。”
语言与工具 人们可能还会问,成功究竟是源于语言扩展本身,还是源于对扩展的IDE支持。然而,由于 MPS始终为语言及其扩展提供IDE支持,我们无法评估用户仅能访问语言扩展但没有IDE支持的情况。此外,扩展与IDE支持是协同的,因为扩展所提供的抽象使得 IDE能够提供有意义的支持。换句话说:定义语言扩展的一个主要原因就是为了实现更好的IDE支持。从这个意义上说,严格区分语言本身与对该语言的IDE支持是没有意义的。
7.3 嵌入式软件的其他挑战 es
在描述我们的案例研究设置(第3节)时,我们解释了所研究的四个方面(复杂性、可测试性、开销和工作量)如何与我们评估C语言扩展在开发嵌入式系统中的有用性的总体目标相关联。从结构有效性的角度来看,还有一些我们可以研究的其他方面(结构),我们将在下面简要介绍。然而,这些方面的重要性较低,且比研究问题中涵盖的标准更难衡量;因此我们在讨论部分对此进行说明。
调试 嵌入式软件开发需要进行调试,以理解某些特定于硬件的行为。尽管广泛的测试可以减少这种需求,但无法完全避免。我们区分了扩展级别调试(在 mbeddr中)和低级别调试(针对生成代码的调试)。
mbeddr的调试器支持在扩展[36]级别上进行单步执行和监视。尽管可以更换gdb后端以支持设备上调试,但扩展级别的调试主要用于在PC上运行的与硬件无关的测试用例,此时使用的是gdb后端。
生成代码的底层调试使用特定目标平台的调试器(例如 IAR Embedded Workbench 中的调试器)。在 SMT 项目中,这也必须用于查找 mbeddr 生成器中的错误,其中一些生成器在当时尚未完全完成(这种情况平均每月发生一次)。为了使底层调试可行,生成代码必须是可读的(见下文)。
两者都将长期存在:开发人员始终希望在扩展级别调试应用程序逻辑,因为扩展的构建旨在简化应用程序逻辑的表达。他们还需要了解底层表示,以理解时序和资源消耗(一些嵌入式软件开发人员至今仍在查看汇编代码)。
生成代码的质量 质量指的是资源消耗和性能,以及可读性和良好的编码实践。我们将在第6.3节中讨论开销和性能,因此这里我们重点关注另外两个标准。
可读性对于调试以及跟踪 mbeddr 生成器中的问题至关重要。mbeddr 具有始终将生成代码的可读性纳入考虑:名称从模型中传递,生成的名称具有明确意义,且代码缩进正确。生成的代码整体看起来就像是手写的一样,只是在高层扩展需要使用一些难看的低级习惯用法时例外(例如为支持组件多态性而使用的指针间接寻址,参见附录A)。我们目前正在研究使用(生成的)宏来提高此类代码的可读性。
mbeddr 支持命名空间,且生成的名称会以它们的命名空间作为前缀。由于这导致了一些非常长的名称, mbeddr 已添加一个选项,仅在未加前缀的名称不是全局唯一时才添加前缀。这显著提高了代码的可读性。
在嵌入式软件中,“良好的编码实践”通常等同于符合MISRA-C,这是一种行业标准,定义了用于提高C代码可靠性和避免错误[33]的规则。我们通过手动分析发现,所有MISRA规则中约有25%会由于mbeddr的语言设计而自动遵守,仅有少数规则会被代码生成器违反(例如标识符31个字符的限制或避免使用函数指针)。其余规则的符合情况则取决于开发者在mbeddr中编写的代码。未来的 mbeddr版本将附带一个检查工具,用于检测在 mbeddr中编写代码时对MISRA规则的违反情况。
在安全关键型环境中,生成代码的质量也非常重要。ISO 61508、ISO 26262 或 DO178 等标准对流程、工具和代码质量都有严格的规定。由于 mbeddr 不被视为已认证的工具(即其正确性未经形式化证明或长期验证),因此生成的C代码将被视为相对于标准的关键产物,这就要求具备高代码质量。关于工具认证和安全关键型系统的详细讨论不在本文范围之内。
可维护性 范·多尔森和克林特[49]得出结论:针对精心选择的领域设计并使用适当工具实现的领域特定语言,可能会大幅降低[..]维护[应用]的成本。我们尚无关于SMT可维护性的长期经验,但可以做出一些观察,这些观察证实了范·多尔森和克林特[49]的结论。
SMT的实现分为两个阶段进行。首先,使用 mbeddr重新构建了ESC功能,然后增加了额外的功能。第二个阶段可以视为SMT的演进。较低的工作量(55人日)体现了基于组件的架构的可扩展性,尤其是考虑到在这55人日内系统必须被分布到两个处理器上运行。
最近,出现了新的传感器硬件来执行核心的S MT测量。它提供了更高的准确性,并使SMT更易于认证。该团队已决定开发使用这种新传感器的SMT变体。初步调查发现,可以通过对少量接口提供替代实现来支持此传感器对于一组少量的接口。该变体本身可以通过集成(连接)新组件和现有组件的实例来创建。这证实了可以轻松处理新产品变体的预期。
软件维护工作量的一部分是开发者在经过可能很长的一段时间后重新理解代码。mbeddr 通过良好的抽象和表示法强调可读性,这表明与 C语言 实施相比,系统(重新)理解的难度得以降低。
另一个维护问题是,当语言以非向后兼容的方式发生变化时,现有代码的迁移问题(这是一个活跃的研究领域,如[20]所示)。由于mbeddr在SMT开发过程中经历了显著演进,这种情况反复发生。直到最近,MPS中一直缺乏迁移支持,必须进行手动(或通过手动编写的脚本)迁移工作;有时不得不显式协调mbeddr和SMT的演进,所幸项目时间表中的缓冲期使得这种协调成为可能。部分得益于SMT项目的实践经验,MPS 3.2已增加了对语言版本和代码迁移的系统性支持,从而在很大程度上解决了这些问题。
7.4 外部有效性
在本节中,我们讨论一个关键问题:本案例研究的结果在多大程度上可以被推广?
Beyond SMT mbeddr 最适合用于必须混合低级和高级代码、需要结合使用不同抽象且效率是重要(但不是唯一)考虑因素的系统。尽管到目前为止 SMT 是使用 mbeddr 构建的最重要的此类系统,但 mbeddr 也被用于多个较小的系统(参见 [51] 的第 5 章)以及许多其他工业项目。本文讨论的发现也在不同程度上适用于这些项目。
以控制算法为主的系统,最好使用数据流导向建模工具(如Simulink)进行开发(我们目前正在探索如何在西门子PLM软件开发的控制工程工具背景下,将数据流抽象添加到mbeddr中)。
Beyond the Team 要成功使用mbeddr,团队除了需要具备嵌入式软件和C语言方面的熟练技能外,还应具备扎实的软件工程技能(如抽象、模块化、复用和自动化测试)。SMT开发人员具备这些技能。然而,遗憾的是,这些技能在传统的嵌入式软件从业人员中并不普遍,该领域传统上更重视局部优化和高效的代码,而非(全局性的)软件工程。如果开发人员已具备这些技能,根据我们的经验,只需几天时间即可完成针对mbeddr的特定培训。其他使用 mbeddr的组织反馈称,通过用户指南、示例以及在论坛中偶尔提问就足以掌握mbeddr:无需mbeddr团队提供的专门培训。
Beyond the extensions 本文评估的C语言扩展已被证明是有用的,因为第6节评估研究生们解决了嵌入式软件开发中的实际问题。其他项目中构建的扩展也(根据传闻)表现出类似的益处。第 6.1节讨论的缺失扩展表明,可能还有其他有用的扩展。
基于这一经验,我们得出结论:如果语言扩展(1)解决了嵌入式软件中的实际问题,(2)其实施不会引入显著的运行时开销,以及(3)相比原生C语言抽象或宏,能够实现更优的类型检查、验证或IDE支持,则这些扩展是有用的。此外,构建这些扩展的工作量不能过高,而这一点通过依赖语言工作台作为基础可以得到保障。
Beyond mbeddr’s MPS Implementation 构建 mbeddr并实现其可扩展性所需的语言工程超出了本文的范围(参见[51]的第7.5节和第10章)。我们选择 MPS是因为它对模块化语言扩展和灵活表示法提供了强大的支持。只要其他语言工作台能够提供这些特征,我们预期在构建类似mbeddr和SMT的系统时可以获得类似的结果。虽然MPS对非文本表示法的支持对 SMT很重要,但模块化的语言可扩展性更为关键。模块化语言扩展在Rascal [25]和Spoofax [23],中也可用,事实上,这两个社区目前都在实现mbeddr的(子集),以比较不同语言工作台的特性。
7.5 可靠性(可重复性)
该案例研究报道了一个实际嵌入式系统的开发过程: SMT 并未专门作为案例研究而设立。这既有优点也有缺点。优点包括系统真实、约束条件真实、有真实的截止期限,以及具备行业级技能的有经验的开发人员。缺点是源代码不可获取,且数据的可获得性有限。用麦克格拉斯的术语来说[31],,本案例研究更强调真实性(一个真实的工业项目),而非可重复性(所有资源的可获取性)。
7.6 实际挑战与缺点
我们对mbeddr在SMT中的应用得出了总体上积极的结论。然而,在使用mbeddr时也存在一些挑战和缺点。其中一些问题与组织变革以及在组织中引入新理念有关[39],我们在此不做讨论。另一些问题则更直接地与 mbeddr相关,我们将在下文进行探讨。
有限的生成器优化 从mbeddr扩展生成C代码的生成器不如一些成熟工具(如Simulink或Stateflow)的生成器那样优化。由于我们现有的扩展本质上是命令式的,因此这不是问题。正如SMT所展示的那样,生成代码能够在规模合理的硬件上运行。此外,由于与C语言的紧密集成,用户始终可以编写高效的底层C代码以应对在某些情况下,生成代码的效率不够高(这在SMT中并不需要)。对于实现不同编程范式(如矩阵数学或数据流模型)的扩展,优化将变得更加重要,从而需要在生成器开发中投入更多工作量。
更长的构建时间 使用 mbeddr 及其扩展会延长构建时间,因为需要进行代码生成。与仅编译和链接 C语言 相比, mbeddr 的构建时间通常要长 2‐3 倍。在 SMT 中,我们对软件进行了模块化,以确保模型的增量构建(在开发人员编写代码并执行测试时)在 10 秒内完成。SMT 的完整重建最多可能需要 4 分钟(主要在夜间构建期间进行)。
工具锁定 mbeddr 依赖 MPS 进行编辑、差异合并和 C 代码生成;MPS 不依赖于任何建模标准(除了类 MOF 元元模型)。虽然可以导出为生成的文本或抽象语法树级别(例如,导出到 EMF),但只有使用 mbeddr/MPS 工具时,才能充分利用该方法在表示法和语言模块化方面的优势。由于 mbeddr 和 MPS 都是开源软件,因此在一定程度上缓解了工具锁定的缺点。
版本控制集成 mbeddr 将程序存储在文件中(作为XML序列化的抽象语法树),这些文件可以由任何基于文件的版本控制系统进行管理(例如 subversion 或 git,后者在 S MT 中使用)。然而,只有在 MPS 中才能有意义地进行差异合并,因为 MPS 在显示差异时也使用投影式编辑器(称为渲染差异)。这意味着基于文本的差异比较工具或基于 Web 的代码审查工具(如 Gerrit)无法使用。
学习曲线 使用MPS的投影式编辑器需要一些适应时间,可能会导致初期的挫败感。正如[57]中的研究显示,所需时间从几个小时到几天不等。此外,用户还必须学习mbeddr提供的扩展。这包括学习具体语法,以及相关概念和语义;如第7.1节“团队专业知识”中所讨论的,这方面问题的程度取决于开发人员的教育背景。在SMT项目中,由于团队成员的技术能力和能够接触到mbeddr开发者,这并未成为问题。
语言工程技能 mbeddr 可以开箱即用,利用现有的扩展。正如本文所示,这些扩展本身就能带来显著的好处。然而,为了充分使用 mbeddr 并通过领域特定扩展对其进行扩展(参见第6.1节中讨论的缺失的扩展),组织可能需要获得语言工程技能。这些技能在许多开发嵌入式软件的组织中并不天然存在,甚至可能难以招聘到具备此类技能的人才。
语言扩展生态系统 一个生态系统需要独立的第三方能够在不改变基础语言的情况下开发语言扩展。例如,第6.1节中指出的所有缺失的扩展都可以由第三方作为模块化语言扩展来构建。虽然SMT中的扩展是与mbeddr团队共同开发的,其他项目和公司(例如西门子PLM)也在没有m

















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









