




昨天有朋友,在 YOLOv10添加输出各类别训练过程指标 评论区下面提到了这个需求,实现一下

版本说明: yolov5-7.0,
v5 代码没有封装很深,修改起来主要集中在 val.py
val.py 分析
针对检测任务,即根目录下的 train.py val.py,其他任务 可参考实现
计算各种指标
# Compute metrics
stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
if len(stats) and stats[0].any():
tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
可以看到这里有很多 基础指标 包括 tp fp p r f1 ap[不同iou下的p] ap_class[存储时 label 对应 下标 0 1 2] 以及处理得到的 ap50 ap
和 多类的平均值,包括 mp mr map50 map
nt 是每一个类别的目标数(框数/实例数)
stats 是list(tuple) 存储 # (correct, conf, pcls, tcls)
debug过程
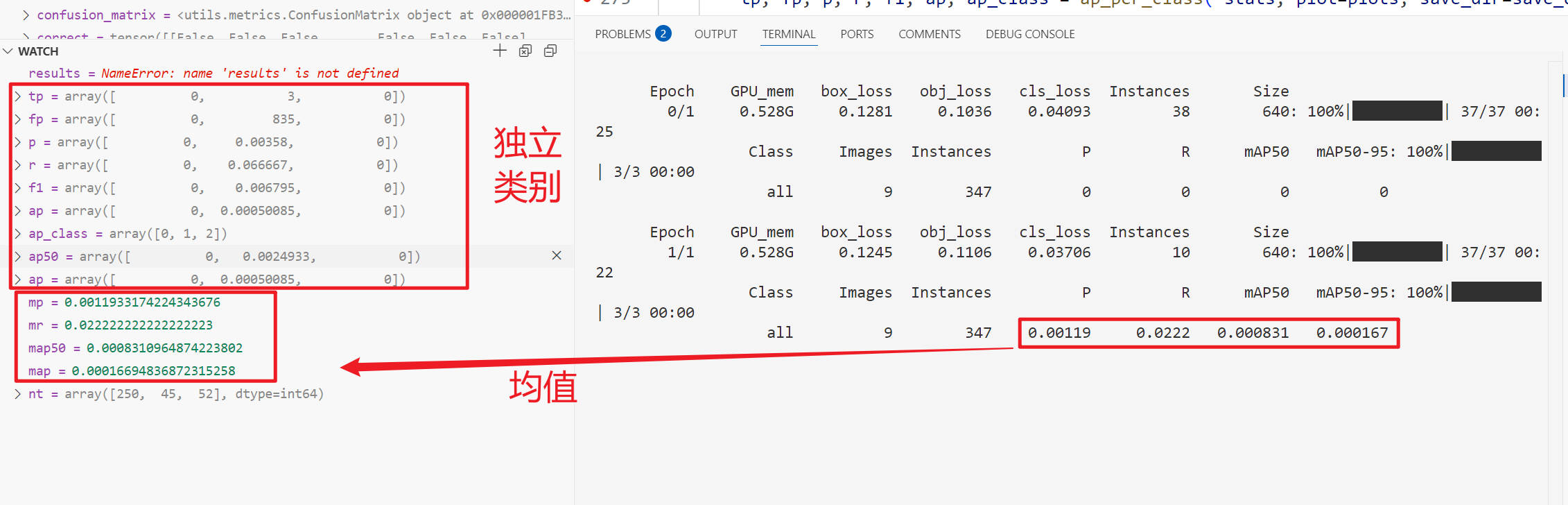
打印输出
# Print results
pf = '%22s' + '%11i' * 2 + '%11.3g' * 4 # print format
LOGGER.info(pf % ('all', seen, nt.sum(), mp, mr, map50, map))
if nt.sum() == 0:
LOGGER.warning(f'WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels')
# Print results per class
if (verbose or (nc < 50 and not training)) and nc > 1 and len(stats):
for i, c in enumerate(ap_class):
LOGGER.info(pf % (names[c], seen, nt[c], p[i], r[i], ap50[i], ap[i]))
可以看到 在训练时候 默认不会启用 打印每一类的指标结果
当启用 validate.run() verbose=True 或 nc < 50 同时 不是训练状态 以及 nc > 1 和 stats 有结果的状态 下会启用
训练时查看
- 启用 verbose (train.py 中)
#
if not noval or final_epoch: # Calculate mAP
results, maps, _ = validate.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
half=amp,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss
,verbose=True # 添加
)
启用效果
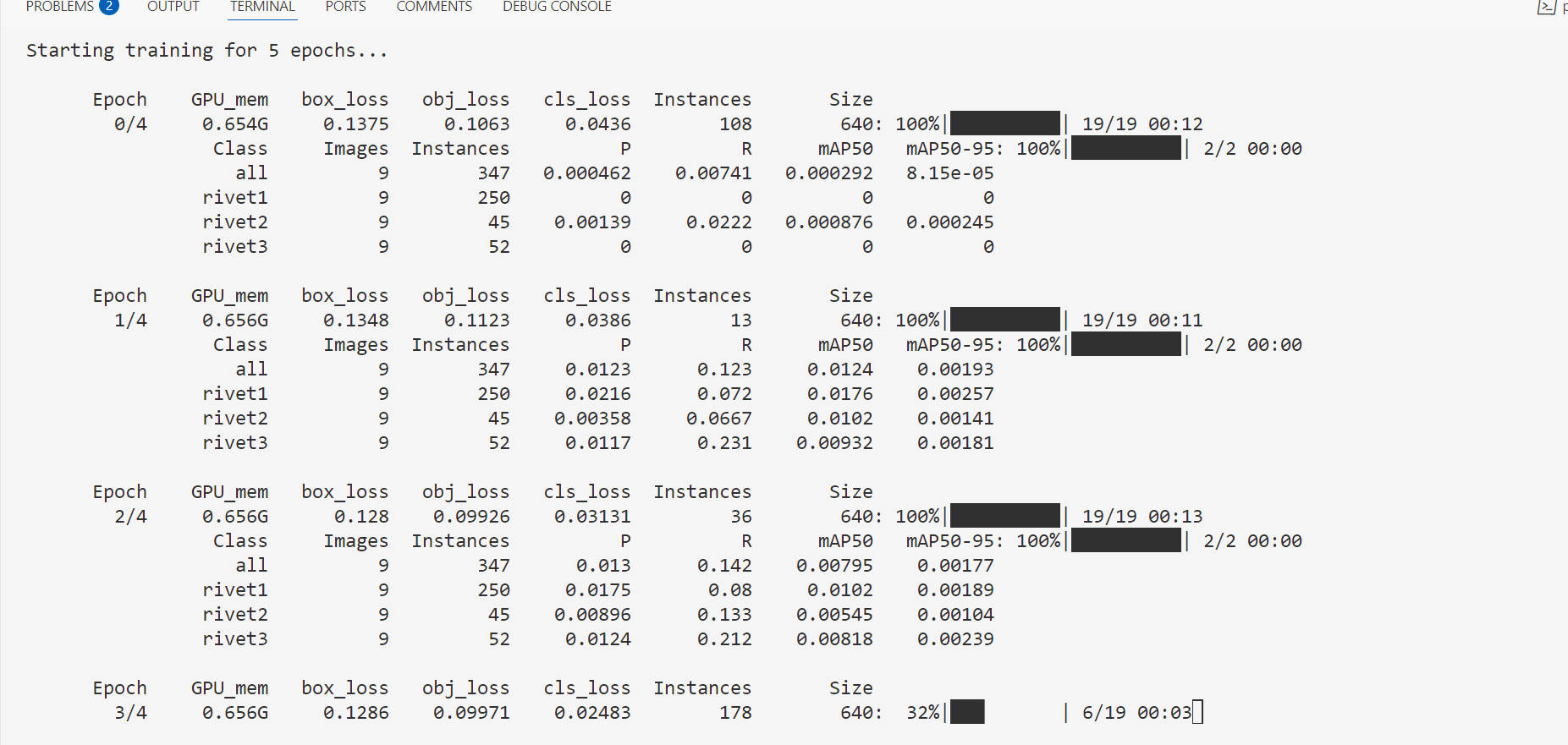
保存到文件
添加下面这个代码(缩进调整好)
# Compute metrics
stats = [torch.cat(x, 0).cpu().numpy() for x in zip(*stats)] # to numpy
if len(stats) and stats[0].any():
tp, fp, p, r, f1, ap, ap_class = ap_per_class(*stats, plot=plots, save_dir=save_dir, names=names)
ap50, ap = ap[:, 0], ap.mean(1) # AP@0.5, AP@0.5:0.95
mp, mr, map50, map = p.mean(), r.mean(), ap50.mean(), ap.mean()
nt = np.bincount(stats[3].astype(int), minlength=nc) # number of targets per class
放到 这段代码
# Print results
pf = "%22s" + "%11i" * 2 + "%11.3g" * 4 # print format
LOGGER.info(pf % ("all", seen, nt.sum(), mp, mr, map50, map))
if nt.sum() == 0:
LOGGER.warning(
f"WARNING ⚠️ no labels found in {task} set, can not compute metrics without labels"
)
后面
根据之前修改大家的反馈,我们将所有指标全部输出到文件,可以基于这些数据 进行 数据后处理等
# save each class metric
metric_keys = ["instances","tp", "fp", "p", "r", "f1", "ap", "ap50"] # map map50 参考输出总的 results.csv
n_key = len(metric_keys)
for i, c in enumerate(ap_class):
metric_values = [nt[c], tp[c], fp[c], p[c], r[c], f1[c], ap[c], ap50[c]]
save_path = os.path.join(save_dir, names[c] + "_resutls.csv")
# 无法直接拿到 epoch 为了减少修改代码影响 去除 epoch
s = '' if os.path.exists(save_path) else (('%23s,' * n_key % tuple(metric_keys)).rstrip(',') + '\n')
with open(save_path,"a") as f:
f.write(s+ ('%23.5g,' * n_key % tuple(metric_values)).rstrip(',') + '\n')
有问题,欢迎大家留言、进群讨论或私聊:【群号:392784757】,修改项目工程 群内提供
效果



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









