




Zhang M, Liu D, Sun Q, et al. Augmented transformer network for MRI brain tumor segmentation[J]. Journal of King Saud University-Computer and Information Sciences, 2024: 101917. [开源]
IF 6.9 SCIE JCI 1.58 Q1 计算机科学2区
【核心思想】
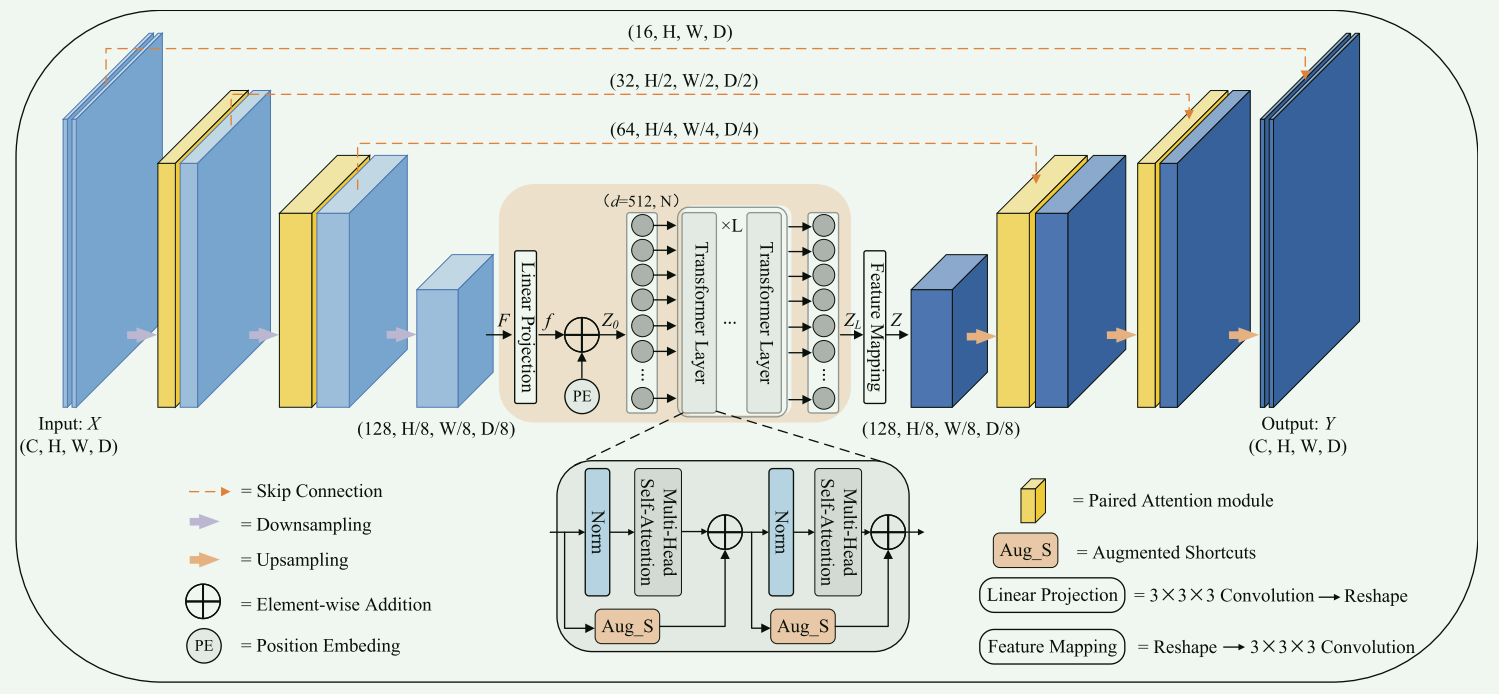
本文提出了一种新型的MRI脑肿瘤分割方法,称为增强型transformer 网络(AugTransU-Net),旨在解决现有transformer 相关的U-Net模型在捕获长程依赖和全局背景方面的局限性。本文的创新之处在于构建了改进的增强型transformer 模块,这些模块结合了标准transformer 块中的增强短路(Augmented Shortcuts),被策略性地放置在分割网络的瓶颈处,以保持特征多样性并增强特征交互和多样性。
【方法】
-
架构设计:AugTransU-Net利用层次化的3D U-Net作为骨干网络,引入了配对注意力模块(paired attention modules)到编码器和解码器层,同时利用改进的transformer 层通过增强短路(Augmented Shortcuts)在瓶颈处。
-
特征增强:通过增强短路(Augmented Shortcuts),可以在多头自注意力块中增加额外的分支,以保持特征多样性和增强特征表示。传统的Shortcuts连接只是将输入特征复制到输出,这限制了其增强特征多样性的能力。具有增强Shortcuts方式的 Transformer 模型已被用来避免特征崩溃并产生更多样化的特征。增强短路的公式为:
Aug − S = ∑ i = 1 T T l i ( Z l ; θ l i ) , l ∈ [ 1 , 2 , … , L ] \operatorname{Aug}_{-} S=\sum_{i=1}^{T} T_{l i}\left(Z_{l} ; \theta_{l i}\right), l \in[1,2, \ldots, L] Aug−S=∑i=1TTli(Zl;θ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4854
4854




 到【灌水乐园】发言
到【灌水乐园】发言







