




 文章介绍了一种新的深度学习方法,通过联合学习机制从完整模态中转移信息以处理脑肿瘤分割中的缺失模态。方法利用特征重建和增强共享特征表示,通过KL散度对齐缺失和完整模态,在BraTS2018和BraTS2020数据集上展示了优越性能。尽管结构复杂,但通过端到端训练和轻量级注意力机制提高效率。
文章介绍了一种新的深度学习方法,通过联合学习机制从完整模态中转移信息以处理脑肿瘤分割中的缺失模态。方法利用特征重建和增强共享特征表示,通过KL散度对齐缺失和完整模态,在BraTS2018和BraTS2020数据集上展示了优越性能。尽管结构复杂,但通过端到端训练和轻量级注意力机制提高效率。
Diao Y, Li F, Li Z. Joint learning-based feature reconstruction and enhanced network for incomplete multi-modal brain tumor segmentation[J]. Computers in Biology and Medicine, 2023, 163: 107234.
方法概述:
-
本芹利用信息学习机制从完整模态到单一模态的信息转移,获取完整的脑肿瘤信息。
-
包含重建缺失模态特征的模块,利用可用模态的信息恢复缺失模态的融合特征。
-
特征增强机制改善共享特征表示,利用重建的缺失模态的信息。
-
在BraTS2018数据集上评估性能,并与其他深度学习算法进行比较,显示该方法在缺失模态情况下的优势。
文章特点总结
1.端到端的训练,借鉴mmformer dropout机制,使得训练时也能考虑缺失模态。
2.生成缺失模态时候没有用GAN,训练更容易
3.多次采用KL散度强制对齐缺失模态和完整模态,特征信息不全更好。
4.多次交替使用轻量级的交叉注意力和自注意力,而不是直接使用Transformer,计算效率更高。
缺点:架构太复杂,多次使用KL散度,训练稳定性不足。
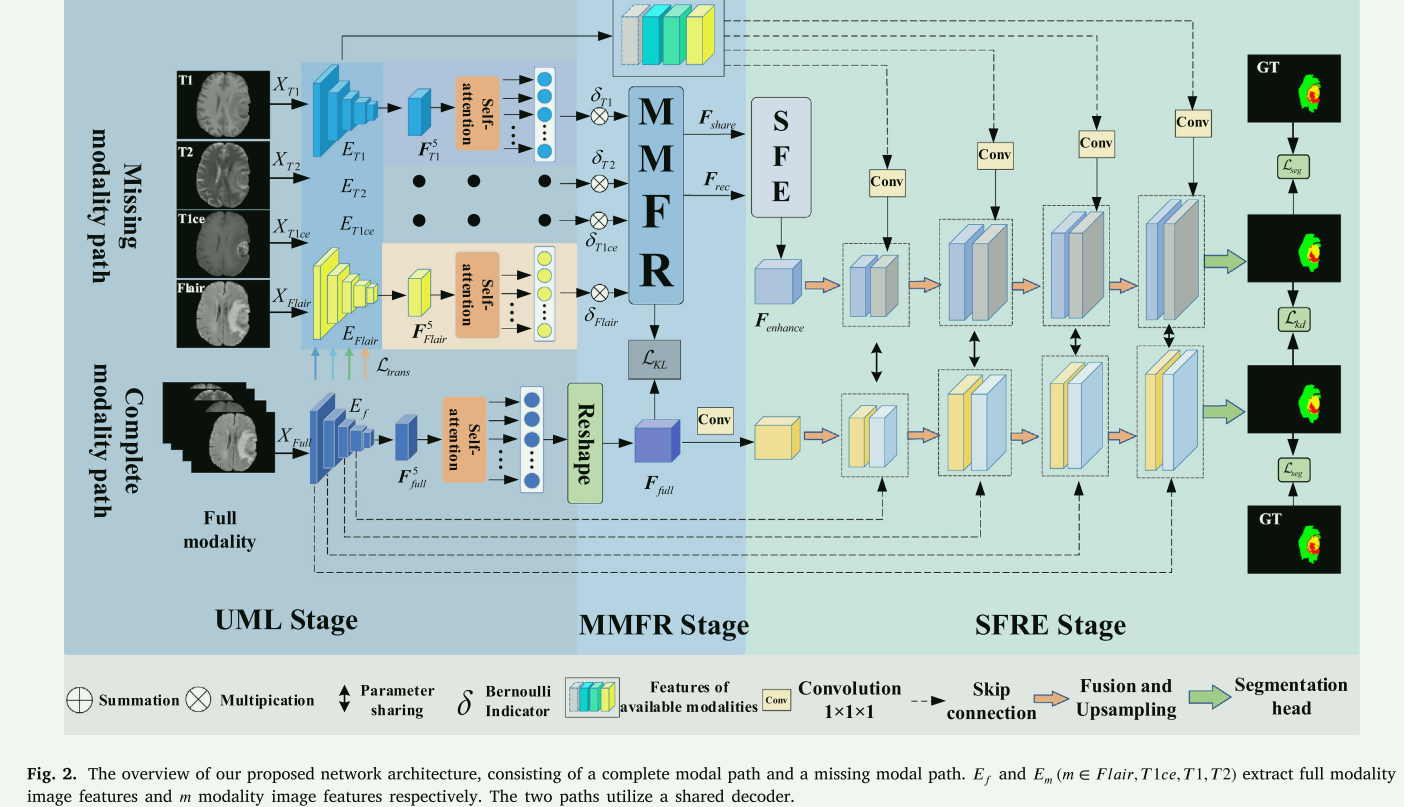
该方法分为三个阶段,单模态信息学习,缺失模态特征重建,脑瘤共享特征表征增强。在UML阶段,完整模态被用来作为监督来指导每个模态学习完整模态中呈现的脑肿瘤信息。在MMFR阶段,我们使用共享特征表示来重建缺失模态的特征并恢复其信息。SERE阶段利用重建的缺失模态特征增强脑肿瘤的共享特征表征,获得更全面的肿瘤信息。此外,为了确保共享特征表示与全模态一致,缺失模态和全模态路径都使用一个共享的卷积解码器。提高了特征表示能力,保证了共享特征表示的一致性。
- Unimodal information learning:提出了一种具有两种独立学习路径的联合学习方法:第一种学习路径使用所有可用的模式作为输入,而第二种学习路径使用完整的模式。目标是将完整模态路径中的丰富特征信息转移到缺失模态路径中,同时鼓励缺失模态路径对缺失信息进行重构。与以往的蒸馏提取方法不同,该方法不需要针对每个缺失的模态情况训练一个单独的模型,而是利用完整的模态信息对每个模态进行引导,以缓解特征提取阶段的跨模态依赖问题。通过L1损失和KL散度来指导每个模式的特征提取器学习多模态的完整肿瘤特征。
Ltrans =14∑i=4l(∥Ffi−Fmi∥1+Lkl(Ffi,Fmi))\mathcal{L}_{\text {trans }}=\frac{1}{4} \sum_{i=4}^{l}\left(\left\|F_{f}^{i}-F_{m}^{i}\right\|_{1}+\mathcal{L}_{k l}\left(F_{f}^{i}, F_{m}^{i}\right)\right)Ltrans =41
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









