







2.1Transformer模型介绍
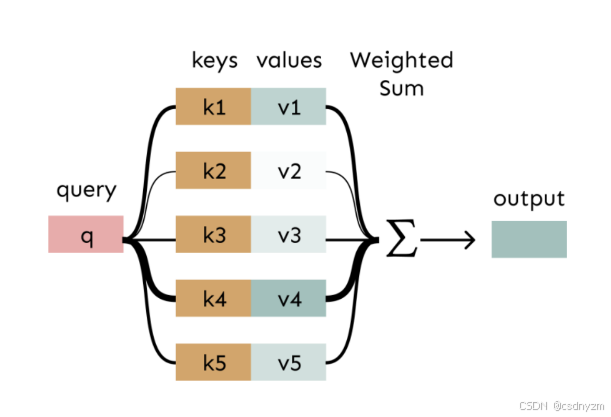
1注意力机制
- 1 2017年Google提出的Attention Is All You Need
- 2一种基于相似度的查表
- s1 计算query与key的相似度:eij=qiT kj
- s2 相似度归一化:αij=exp(eij)/Σj e(eij)
- s3 对value加权求和 oi = Σj αij vi
2 Transformer模型:编码器-解码器结构
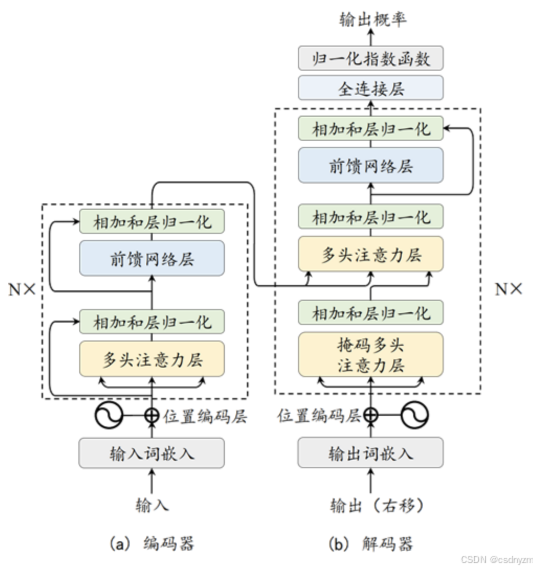
-
1 N层堆叠 编码器:将输入变换为隐藏层特征
-
多头注意力MHA:建模任意距离词元间的语义关系
- 单注意力头计算:Scaled Dot-Prouduct Attention
- Attention(Q,K,V)=softmax(QKT/√D)V
- 多注意力头拼接:Multi-Head Attention
- MHA=Concat(head1,…,headN)WO

- MHA=Concat(head1,…,headN)WO
- 单注意力头计算:Scaled Dot-Prouduct Attention
-
前馈网络FFN
- 线性变化:先升维,后降维
- 非线性:ReLU或GELU

-
残差连接和层归一化LayerNorm
- 残差连接
- 层归一化
-
RMS均方根层归一化

-
层前归一化、层后归一化、夹心归一化
-
-
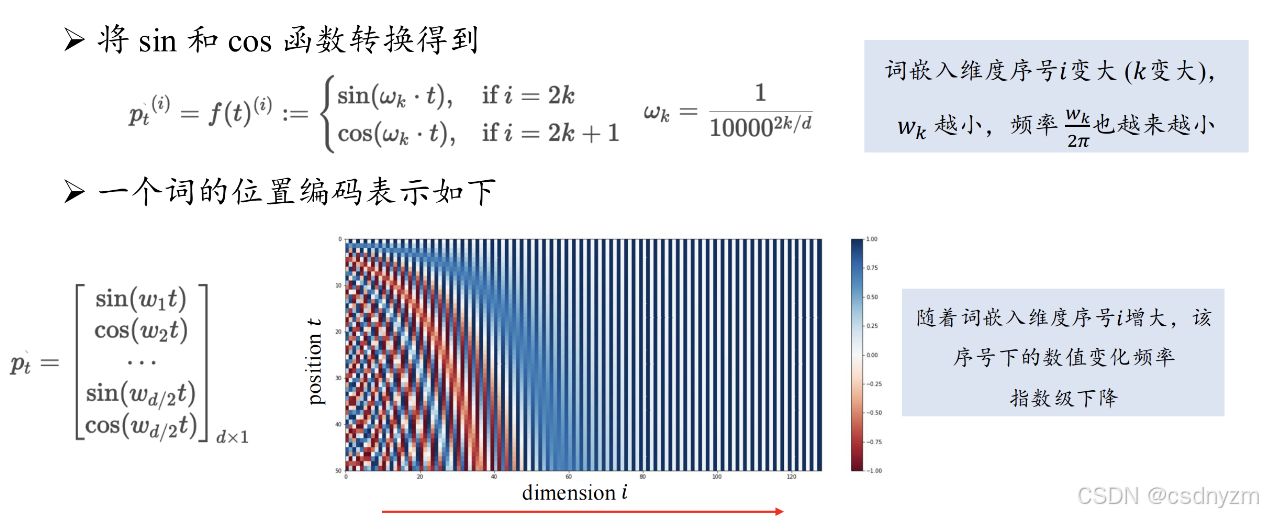
输入编码:xt=vt+pt
- vt:词嵌入(语义信息)
- pt:位置编码(位置信息)
- 绝对位置编码
- 相对位置编码:RoPE旋转位置编码;ALiBi位置编码
-
-
2 N层堆叠 解码器:将隐藏层特征变换为自然语言序列
- (掩码)多头注意力 MaskedMHA
- 前馈网络FFN
- 残差连接和层归一化LayerNorm
- 输出层:生成词元概率分布
- 全连接层
- 归一化指数函数softmax
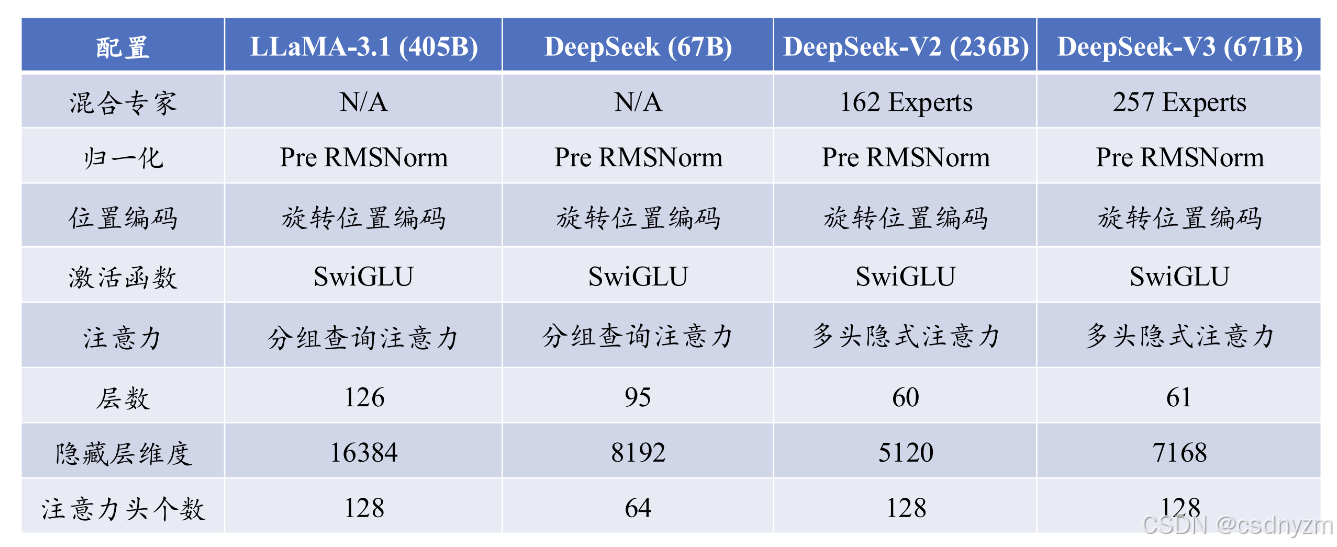
3 LLaMA与DeepSeek模型配置对比


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









