







大语言模型LLMBook
1.2大模型技术基础
1定义:具有超大规模的预训练语言模型
2架构:主要为transformer解码器架构
3训练:pre-training(预训练),post-training(后训练)
-
1pre-training(base model)
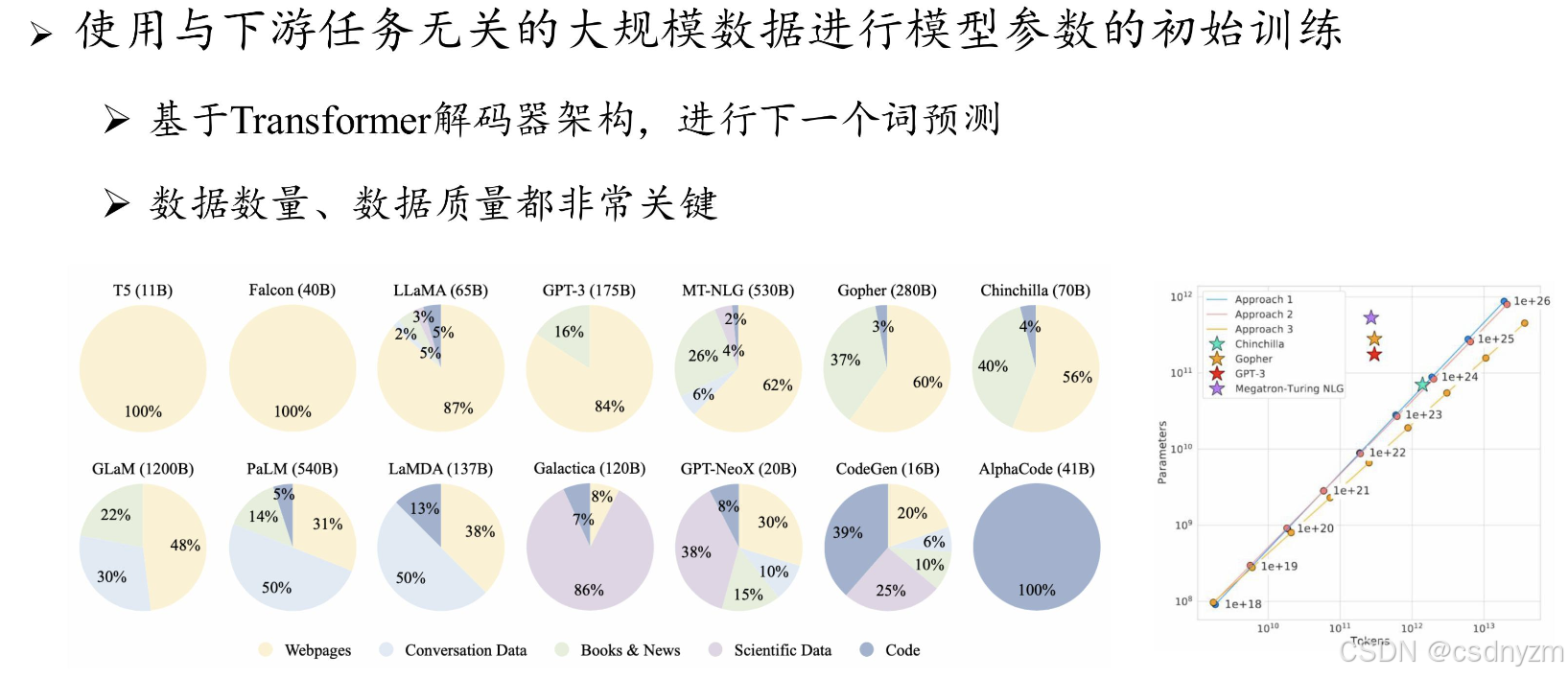
- 目标:建立模型基础能力
- 数据:万亿词元
- 算力:百卡~万卡数月
- 使用:few-shot提示
-
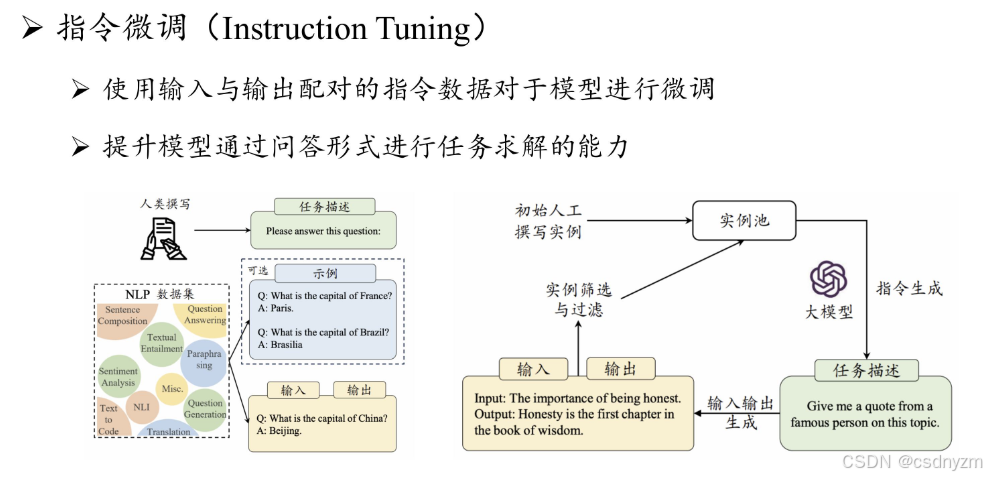
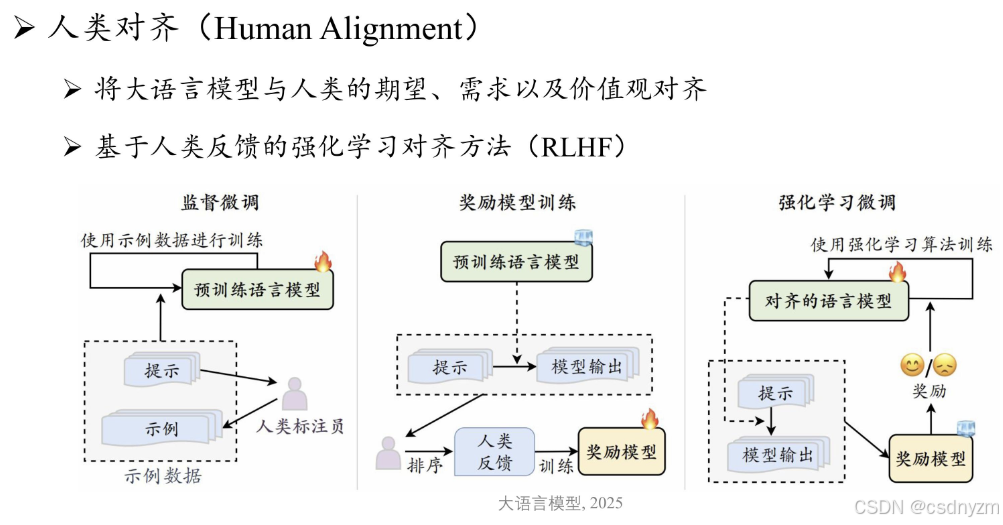
2post-training(instruct model):指令微调,人类对其
- 目标:将基座模型适配到具体应用场景
- 数据:十万~千万指令数据
- 算力:十卡~百卡数天
- 使用:可直接zero-shot
-
3特别规律
- 1扩展定律
-
定义:扩展参数、数据和算力,大模型能力会出现明显提升
-
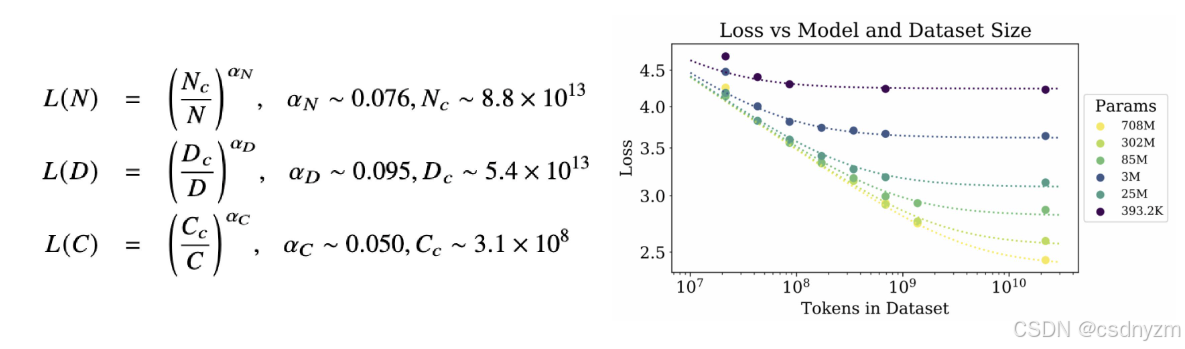
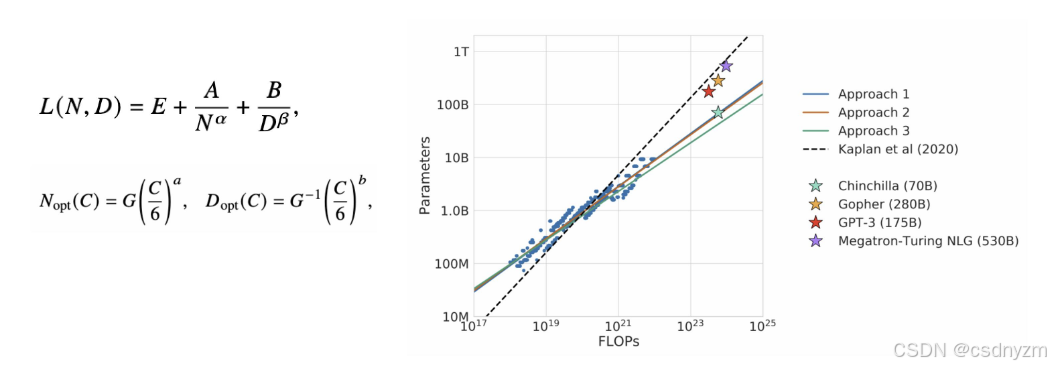
KM定律:模型性能与N、D、C的幂律规律
-
Chinchilla定律:旨在知道大模型充分利用给定算力去优化训练
-
深入探讨
- 大模型可能会存在边界效应递减
- 通过小模型可预测预估大模型
-
- 2涌现能力:代表性能力
- 定义:模型扩展到一定规模,特定任务性能显著提升,远超随机水平
- 指令遵循
- 上下文学习
- 逐步推理
- 深入探讨
- 涌现能力可能部分归因于评测设置
- 3规模效应
- 扩展定律:理解为一种较为平滑的多任务损失平均 LM Loss
- 涌现能力:理解为非平滑的、某种特定能力或任务的性能跃升 Task Loss
- 1扩展定律
-
4总结
- 1规模扩展:奠定了大模型早起的技术路线
- 2数据工程: 数据数量、质量对大模型至关重要
- 3高效预训练:需要建立可预测、可扩展的大模型训练框架
- 4能力激发:微调、对齐、提示工程等能进一步激发基座模型能力
- 5人类对齐:减少大模型使用风险,进一步激发能力
- 6工具使用:调用外部工具加强模型弱点,扩展能力范围


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









