 解构HelloWorld:现代程序背后的抽象世界之旅
解构HelloWorld:现代程序背后的抽象世界之旅





【优快云 编者按】相信每位程序员都对“Hello World”程序非常熟悉,但你是否了解其背后的抽象世界呢?
原文链接:https://thecoder08.github.io/hello-world.html
未经允许,禁止转载!
作者 | Lennon McLean 责编 | 夏萌
译者 | 弯月
出品 | 优快云(ID:优快云news)
在本文中,我们来深入探讨现代Hello World程序背后的抽象世界。

背景介绍
本文主要探讨用C语言编写的Hello World程序。不考虑具体的编程语言在Hello World正式运行之前解释器/编译器/JIT等工作的话,C语言就是高级语言所能达到的最高层次了。
原本我写这篇文章的目的是让所有具备一些编程背景的人都能理解,但现在我认为具备一些C语言或汇编语言的知识会更有帮助。

Hello World代码
每个人都应该很熟悉Hello World程序。学习Python时,你编写的第一个程序可能像下面这样:

非常简单,就是在屏幕上输出文本“Hello World!”。
在本文中,我们来看一看用C语言编写的Hello World程序。你能看懂下面的代码吗?
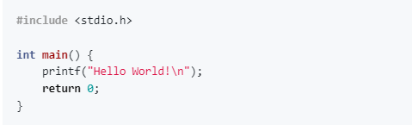
这个程序执行的操作与上述Python代码完全一样。但与Python不同,你不能直接调用解释器运行这个程序。你必须先运行编译器,将这段代码转换成机器代码,然后才能在计算机的处理器上直接运行。所有现代大型程序都是这样编写的。
因此,我们必须运行以下命令:

这个命令可以将文件hello.c中的C代码转换成机器代码,并生成一个名为hello的程序。然后,我们就可以通过如下命令运行程序了:

结果是:


我们的程序
那么,我们的程序是如何输出这个文本的呢?首先,我们来看看我们的程序,看看里面究竟是什么。

你不用担心看不懂,我会慢慢解释。重点是下面这几个字段:

这几个字段告诉我们,这个程序是x86_64指令集架构上的ELF可执行文件。什么意思?
ELF可执行文件是Linux文件,相当于Windows下的.exe文件,就是一种计算机可以运行的程序。其余信息告诉我们,这是一个在 64位 x86 处理器上运行的机器代码程序,64位 x86 处理器是自1981年以来IBM计算机一直在使用的CPU架构。当然,当时还不是64位的,但现代处理器也可以运行为IBM PC编写的代码。这又是另一个话题了。
我们的程序文件包含的是机器代码,一种语言,也是CPU能理解的唯一语言。那么,CPU从何处开始运行代码呢?
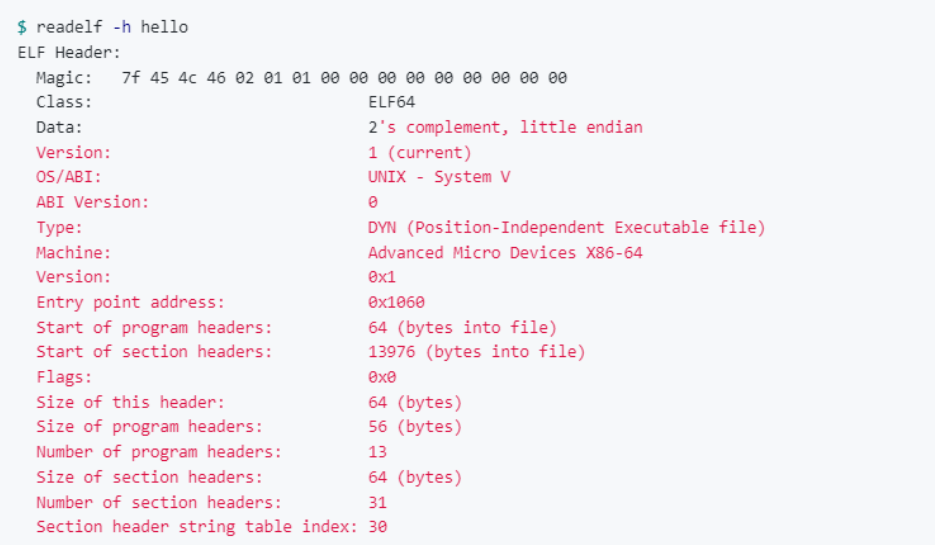
此处的重点是:Entry point address,其值为 0x1060。这是一个十六进制数字,代表了程序加载到计算机内存后,程序中的一个位置。那么,这个位置上究竟有什么呢?

代码

这条命令完整的输出太长了,此处就不贴了。下面是截取的一部分,请注意 1060: 开头的一行:

什么意思?冒号前面的数字是后面的字节的地址,也就是它们在文件中的位置。后面的数字是程序文件中的数据字节,此处表示机器代码。后面的文本是机器代码的反汇编。汇编语言是人类可读的机器代码的表示。请注意,即便左侧的字节不表示代码,反汇编器仍会尝试对它们进行反汇编。由此会产生一些垃圾和毫无意义的汇编代码。
如上,我们找到了一些代码!但不是我们编写的代码。这些代码是编译器(严格来说是链接器)自动添加到程序中的。本质上,这些代码会执行一些初始化,然后运行一个重要的指令:

这条指令告诉计算机去执行其他地方的一些代码,此处即为地址0x2f53,当动态链接器加载我们的程序时,这个地址会被改为0x3fd8。关于这一点,此处不做详细探讨。
但无论你怎么努力寻找,我们的文件中都找不到这两个地址。准确来说,0x3fd8在全局偏移表中,同样相关内容也超出了本文的范围,但此刻它是空的。这是因为这段代码不是在我们的程序中定义的,而是在其他地方。

C 库
那么究竟在哪里?
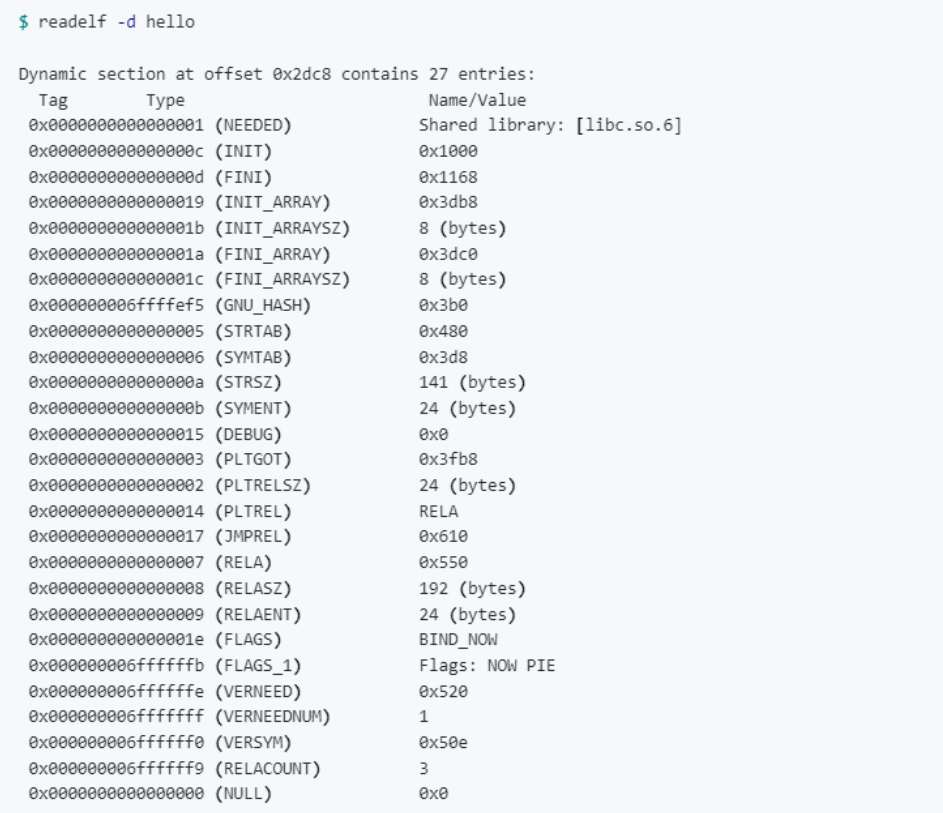
我们的代码依赖的库有很多,上面只是其中一部分。我们可以看到下面这行:

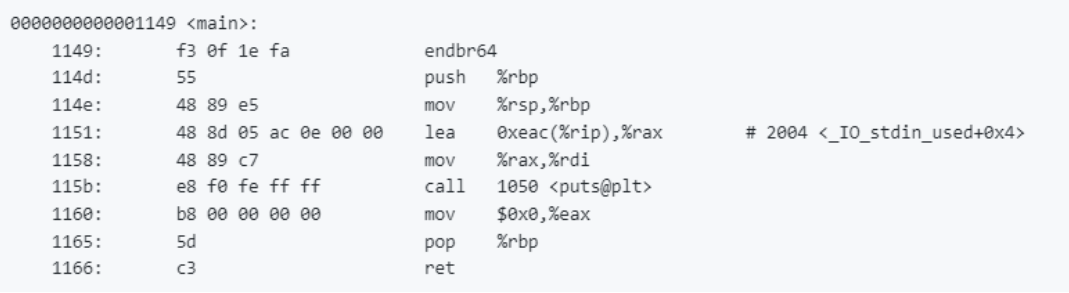
设置了一个栈帧。
设置了我们的函数调用的参数。
调用了我们的Hello World函数。
清理了栈帧。
从函数中返回,退出代码为0。
这就是我们在源代码中看到的内容。但什么是栈帧呢?它是计算机内存的一部分,我们的程序用栈帧来存储局部变量,即在main函数内声明的变量。幸运的是,我们没有声明任何变量,所以不需要在意。重点是下面这部分:

具体操作为:
设置 Hello World 字符串的内存地址,将其作为函数调用的第一个参数(间接调用)。
调用 puts() 函数。
等等,puts()?我们调用的不是 printf() 吗?
没错。但是,编译器进行了一种优化。printf 函数很复杂,因为它能够打印“格式化输出”,这意味着我们可以在输出中嵌入变量。这个函数负责将它们转换为字符串并输出,但我们没有用到这些功能。因此,编译器将 printf() 替换为更为简单的 puts(),后者仅负责打印一串未经格式化的文本。那么,我们的文本在哪里?

字符串
根据反汇编器的显示,我们的字符串位于地址 0x0eac,加载后会转换为地址 0x2004。那么,字符串里面是什么呢?
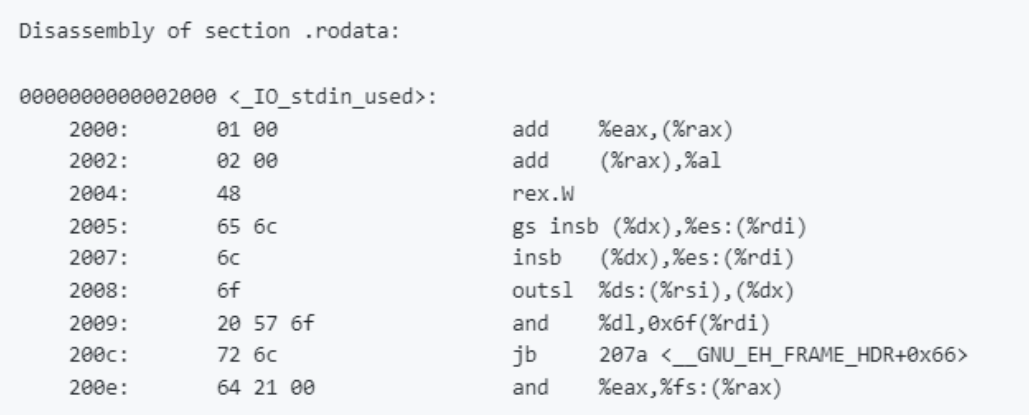
前面,我说过即使不是代码,反汇编器也会尝试进行反汇编,这就是一个很好的例子。忽略上面这些汇编语言,因为它们毫无意义。我们来看看 0x2004,后面是一串十六进制字节 48 65 6c 6c 6f 20 57 6f 72 6c 64 21 00,翻译过来就是字符串“Hello World!”,最后是一个NULL终止符。
但是我们的字符串中不是还包含一个换行符 \n 吗,不是应该被翻译为 ASCII 0x0a 吗?没错,但这也是编译器优化后的结果。puts() 函数会在字符串后面添加换行符,而 printf() 不会。因此,我们的换行符被移除了,这样输出就只包含一个换行符。
我们还看到了一个NULL字节 0x00,又称作NULL终止符。所有 C 字符串的末尾都有这个字节。在 C 中,字符串不包含任何长度信息。因此,接受任何长度的字符串作为参数的函数会逐字节地对其进行操作,直到遇到NULL终止符。如果内存中有多个字符串,并且它们之间没有NULL终止符,那么 C 函数将一次性操作所有字符串。最终,函数将来到字符串末尾,并开始读取不允许读取的内存,而你的程序将崩溃并显示“Segmentation Fault”错误。

puts()
puts()的地址是0x1050。

又一次调用标准库(严格来说是全局偏移表,但最终是标准库)。
此处,我们还是不想阅读标准库的反汇编代码,但幸运的是 Glibc(我们的 C 标准库)是开源的。我们能从中发现什么呢?
在标准库中,puts() 的别名为 _IO_puts。
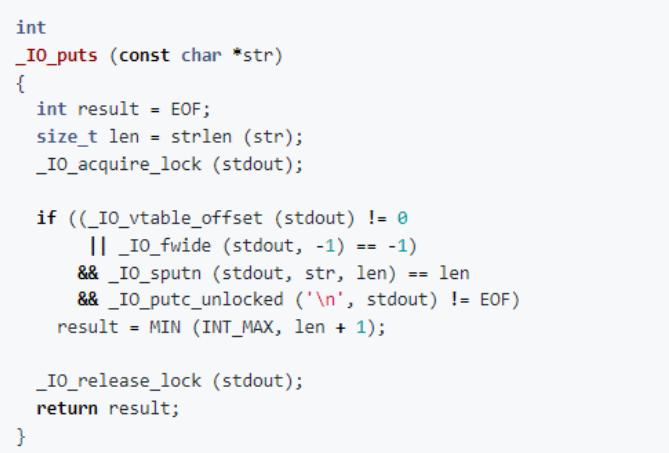
可以看到,这个函数获取了字符串的长度,获得了输出流锁,进行了一些检查,并调用了 _IO_sputn。然后,释放锁,并返回打印字符的数量。
我搜索了一下这个函数,但没有找到。很明显,它通过一个名为 _IO_file_jumps 的函数执行了一些操作,并调用了 _IO_new_file_xsputn。

好长的一段代码,我可不打算去分析这段代码究竟在干什么。我知道使用 Glibc 来解释这段代码会很麻烦。因此,此处我决定查看 musl libc,我知道它应该很小。

musl
在 musl 中,puts() 定义如下:
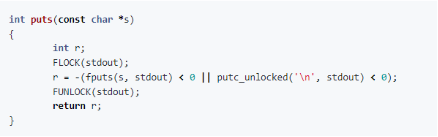
首先,获取输出流锁;然后,调用fputs;最后,释放输出流锁。
那么,fputs又是怎样定义的呢?

获取字符串的长度,然后调用fwrite(),参数为输出流、字符串及其长度。
那么,fwrite()的定义又是什么呢?
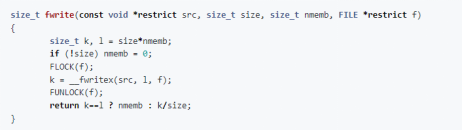
获取另一个输出流锁,然后调用__fwritex(),然后释放输出流锁。
那么,__fwritex()的定义又是什么呢?
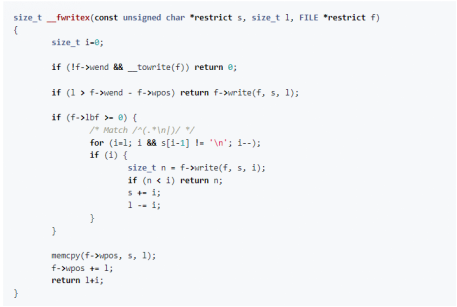
这段代码有点多,但主要操作是使用输出流的FILE对象调用write()。我们的流被定义为标准输出(stdout),这又是在哪里定义的呢?
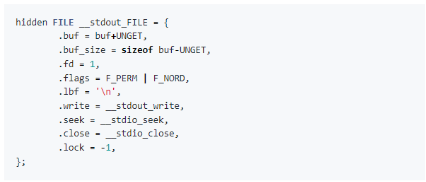
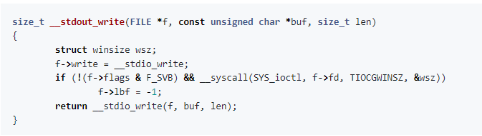
针对我们的输出流执行了一次 TIOCGWINSZ ioctl,然后又调用了 __stdio_write(),那么后者的定义又是什么呢?

我们距离终点已经很近了。这个函数执行了很多操作,调用了 syscall(),第一个参数为 SYS_writev。那么,syscall() 是如何定义的呢?
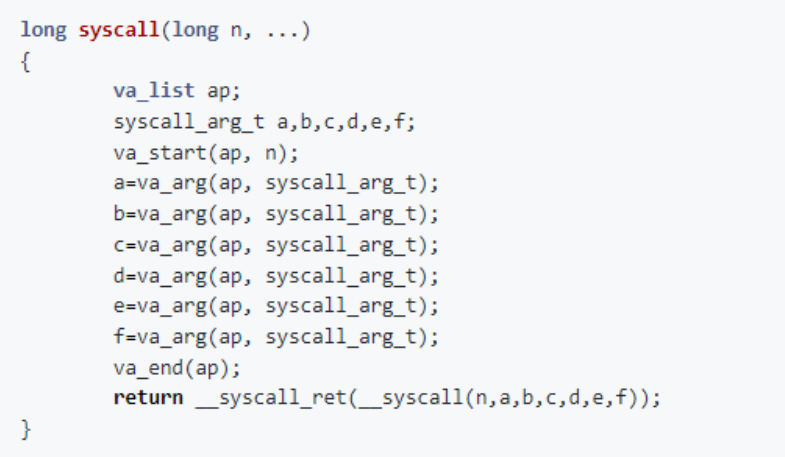
syscall()的第一个参数为系统调用编号,还接受数量可变的额外参数。va_arg()调用将这些参数读入变量a、b、c、d、e和f中。然后,我们使用这些参数调用__syscall(),并将结果放入__syscall_ret()。
不幸的是,我找不到__syscall()的定义。但我觉得这是因为这部分属于平台范畴。Musl是一个多架构的C库,因此从这个深度开始运行的代码取决于我们使用的是什么架构。在深入研究之前,我看了一眼__syscall_ret():
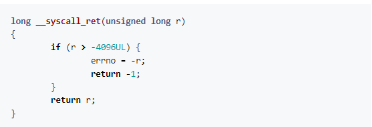
检查__syscall()的返回值是否有效,如果无效,则系统调用失败,因此返回-1。

系统调用
我们的Hello World调用的最后几个阶段涉及到了系统调用。什么是系统调用?无论我们的C库有多大,都无法完成底层的一些工作。其中之一就是与硬件通信。这部分工作预留给了内核,是操作系统的一部分,负责控制并共享IO设备、内存和CPU的访问。在这个例子中,这部分工作由Linux内核负责。在Windows中是ntoskrnl.exe,也就是任务管理器显示的System。
这意味着,向操作系统传达了后面的工作后,puts()调用就功成身退了。在这个例子中,我们要求操作系统向输出流写入一些文本。写入流的工作是系统调用write完成的。Musl使用了一个类似的系统调用,叫做writev,它可以在数组中写入多个缓冲区。下面,我们来看看musl如何进行系统调用。

我们已经追踪到最底层了。在x86_64平台上,musl可以使用7个不同的函数进行系统调用。每个函数接受不同数量的参数。
每个函数都有一个__asm__指令,它可以将内联汇编代码嵌入到编译器的机器语言输出中。我们在向操作系统发出系统调用时设置了一些CPU寄存器并执行了syscall指令。然后,控制权转移到了内核,由后者读取我们的参数并执行系统调用。

内核
接下来,由Linux内核执行系统调用请求的操作。系统调用write告诉内核写入文件系统中的一个已打开的文件,或者写入一个流,而此处我们的操作属于后者。
系统调用write有3个参数:文件描述符、写入的缓冲区以及写入的字节数。musl使用的系统调用write略有不同,但此处我们只讨论write。
那么,我们到底写入到哪里呢?
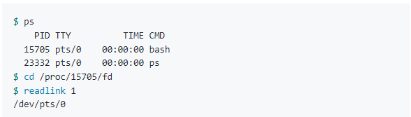
视具体情况而定。
在这个例子中,我在GNOME终端模拟器中运行了hello程序。这款模拟器是一个图形应用程序,对于内核来说,它是一个伪终端(pty)。所以,内核将我们的消息Hello World保存在缓冲区中,模拟器运行时,读取缓冲区,然后再显示。终于讲完了。
当然,整个旅程还没有完全结束。模拟器必须将文本渲染成一帧(可以使用GPU来渲染),将此帧发送到X服务器/合成器,然后由后者将其与其他正在运行的应用程序组合在一起(也使用GPU),例如我当前用来撰写这篇文章的文本编辑器,然后将其发送回内核,最后显示出来。
长呼一口气。我略过了很多不太重要的细节,而且你的环境可能完全不同。比如你选择远程登录,那么内核会将的文本发送到sshd,然后将通过互联网发送的数据包(加密)发送回内核。或者,你使用的是物理终端,连接到串口转USB适配器,那么内核必须将文本放入USB数据包,并将其发送到下一级。再或者,你使用了帧缓冲控制台,这是在没有安装GUI的情况下与操作系统交互的默认方式。在这种情况下,内核必须将文本渲染成一帧,并将其输出到显示器。
重点在于,接下来的操作有很多可能性,而且具体的细节并不重要。因为你的Hello World消息只是一个系统调用,来自一个程序,此时此刻你的计算机上有数百万个系统调用和成千上万个程序在运行,而Hello World只是其中最微不足道的一个。

总结
现如今,硬件上的现代软件系统是如此错综复杂,想方设法完整地理解计算机上的一个小操作完全没有意义。显然,为了解释这个小程序所做的一切操作,我略过了很多内容。我没有提到所有边缘情况、附加信息以及计算机执行的其他任务。我也没有解释内核是如何工作的。
问:那么,Hello World 程序究竟是如何工作的呢?
答:一言难尽……
推荐阅读:
▶突爆惊雷!美国拟全面禁止「竞业协议」:“一场科技行业的就业大地震要来了”
▶26 岁面壁智能 CTO 曾国洋:“卷”参数没意义,不提升模型效率,参数越大浪费越多 | AGI 技术 50 人



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









