




整理 | 屠敏
出品 | 优快云(ID:优快云news)
不是顶会论文,也没有发在 arXiv 上,甚至连“正式发表”都称不上——但就是这样的一篇纯博客文章,却让一名研究员成功拿到了 OpenAI 的 Offer,甚至据说这篇博客的技术还被用于 GPT-5 的训练工作。

听起来像是一个段子,但这位名叫 Keller Jordan 的研究员却真实地做到了。

Keller Jordan 的这篇博客叫做《Muon: An optimizer for hidden layers in neural networks》(https://kellerjordan.github.io/posts/muon/),其中提出了一种名为 Muon 的新优化器。
简单来看,这篇文章既不是论文格式,也没有同行评审,却因实测效果出色而意外走红。更出人意料的是,它还成了他叩开 OpenAI 大门的敲门砖。
这一消息最早由 Keller Jordan 的合作者、AI 云平台初创公司 Hyperbolic Labs 的联合创始人 Yuchen Jin 在 X 上公开。
Yuchen Jin 写道:
「很多博士(包括曾经的我)常常陷入一个误区:认为在顶级会议上发表论文就是最终目标。
但“发表”并不等于“影响力”。
Muon 只是篇博客文章,却帮 Keller 拿到了 OpenAI 的 offer——现在他可能正在用它训练 GPT-5。
我很感激他把我列为第二作者。我只是用 NanoGPT 跑了些实验,测试 Muon 在更大语言模型上的可扩展性,结果它彻底击败了 AdamW(曾经的优化器之王)!
这事教会我:无论是做研究,还是生活,追求的应该是影响力,而不是光鲜的头衔。」
AI 产品爆发,但你的痛点解决了吗?8.15-16 北京威斯汀·全球产品经理大 会 PM-Summit,3000+ AI 产品人社群已就位。
直面 AI 落地难题、拆解头部案例、对接精准资源!
扫码登记信息,添加小助手进群,抢占 AI 产品下一波红利:

进群后,您将有机会得到:
· 最新、最值得关注的 AI 产品资讯及大咖洞见
· 独家视频及文章解读 AGI 时代的产品方法论及实战经验
· 不定期赠送 AI 产品干货资料和秘籍

顶会论文≠有影响力
Yuchen Jin 的这番话一出,激起了不少的讨论。
毕竟,在学术圈,顶会论文几乎是衡量一个人研究水平和职业潜力的“硬通货”——特别是对博士来说,能否进入一流实验室、申请教职、争取经费,其背后有没有在 NeurIPS、ICLR、CVPR、ACL 这类会议上挂名还是很重要的。
而 Keller 却用一篇“非正式”的博客文章,直接实现弯道超车,颇有些颠覆常规的意味。
其实,Keller Jordan 早在今年 2 月就公开表达过自己对这一事的态度。他在 X 上写道,自己之所以没有为 Muon 写一篇正式的 arXiv 论文,是因为他压根不相信,“写出一篇数据漂亮、图表华丽的优化器论文”与“这个优化器实际有没有用”之间有什么必然联系。
他更看重真实训练中的表现,“我只相信实测跑分”。

在他看来,与其把大量时间投入在格式要求繁琐、评审周期冗长的论文撰写上,不如专注于实践落地与真实效果。毕竟,一个想法从成形到论文发表,往往需要耗费数月甚至更久的时间,而当它终于面世时,极有可能会“过时”,而即使发布了又可能会被淹没在顶会上一波又一波的投稿浪潮中,很少有人真正看、也很少有人真的用。
时下,在 AI 加快各领域迭代速度之际,这种观点并非罕见。
前谷歌研究员 Hieu Pham 对此事评论称:
“曾几何时,‘发表论文’就等于‘产生影响’。ResNet、Seq2Seq、Adam、Attention、Transformers、MoE……这些经典成果都是以论文形式出现的。但真正的问题,是我们没有意识到这个时代已经过去了。我自己也曾犯过类似的错误。好在,现在我们还有机会重新选择。”

他补充道,就优化器而言,“行业已经有成千上万篇关于优化器的论文发表了,但真正推动 SOTA(最优性能)前进的,也就只有一次——从 Adam 到 AdamW。其他所谓的进步,基本都是这两个的改进实现,比如 FSDP。因此,我们真的应该停止再写这类论文了。也不必引用 AdamW,大家都知道它是哪里来的。”

同是博士毕业的 Yuchen Jin 也感慨学术生态的局限:“这就是学术界令人唏嘘的地方。我曾有一位实验室同伴,没能在任何顶级的计算机系统会议上发表论文,这导致他很难拿到名校教职。但最终,他成了谷歌的副总裁。”


非常规的“硬核学霸”
如今,Keller Jordan 的经历也给人们带来新的启发:原来,不写论文,也照样能闯进一流的顶尖实验室。
随着 Muon 受到越来越多研究者的关注,就在今日, Keller 继续重申自己的观点——「已经有上百篇关于优化器的论文发表了,但所谓的最优性能(SOTA)也就提升了几次而已。所以我们可以得出一个结论:几乎所有优化器的论文都是“假的”。如果你也打算再写一篇这样的“假优化器”论文,拜托别引用 Muon。我不需要你的引用。」

这番言论虽然犀利,却也反映出 Keller Jordan 对“实际效果大于学术装饰”的坚持,以及他鲜明的个性。
打开 Keller 的履历,他也的确是个不折不扣的“硬核学霸”。
从领英资料来看,Keller 曾就读于加州大学圣克鲁斯分校,主攻机器学习、数据科学等方向。而后在 UC 伯克利,主修操作系统、计算安全。而后于 2020 年以 3.94 的高绩点(满分 4)获得美国加州大学圣迭戈分校数学与计算机科学双学位。

毕业后,他进入 Hive 公司,担任机器学习工程师,随后又作为访问研究员(Visiting Researcher)加入维也纳复杂科学研究中心(Complexity Science Hub Vienna),继续深耕 AI 实践。
到了 2024 年 12 月,也就是发布 Muon 不久之后,Keller 成功入职 OpenAI,以一种几乎“逆学术常规”的方式,打破了人们对进入顶尖 AI 实验室的固有认知。
那么问题来了:他那篇非正式的博客文章,到底有何魔力?为什么没有顶会背书、没有论文格式,却能引发如此关注?
接下来,我们就来一起看看 Muon 的真实效果与特性。

对比其他优化器,Muon 有何吸引之处?
Muon 是一个专门为神经网络隐藏层设计的优化器。它目前刷新了 NanoGPT 和 CIFAR-10 等热门任务的训练速度记录。
首先从实测上来看,Muon 目前已经取得了非常不错的成绩:
-
在 CIFAR-10 上,从头训练到 94% 准确率的时间,从 3.3 A100 秒缩短到 2.6 A100 秒。
-
在 NanoGPT 的“精炼网页(FineWeb)”任务中,把验证损失达到 3.28 的速度提升了 1.35 倍。
-
在参数规模扩展到 774M 和 1.5B 时,训练速度依然保持优势。
-
用 Muon 训练一个 15 亿参数的 transformer,在 HellaSwag 任务中达到了 GPT-2 XL 的水平,只用了 10 小时(8 张 H100 组成的 GPU 集群)。而使用 AdamW 则需要 13.3 小时才能达到相同水平。
下图展示了在 NanoGPT 任务中,Muon 与其他优化器在样本效率和实际训练时间上的对比表现:
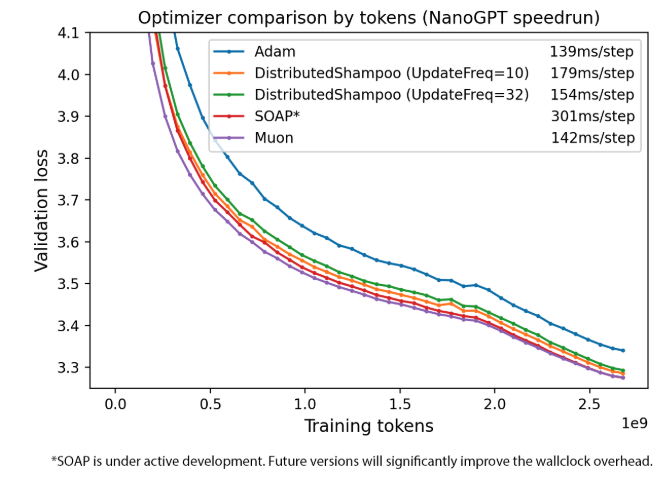
图 1 按样本效率比较优化器
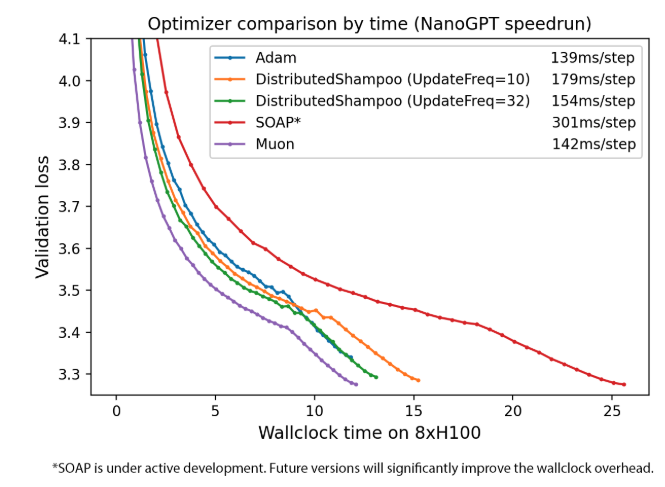
图 2 按挂钟时间比较优化器
以下是 Muon 和 AdamW 在训练 15 亿参数语言模型时的对比:
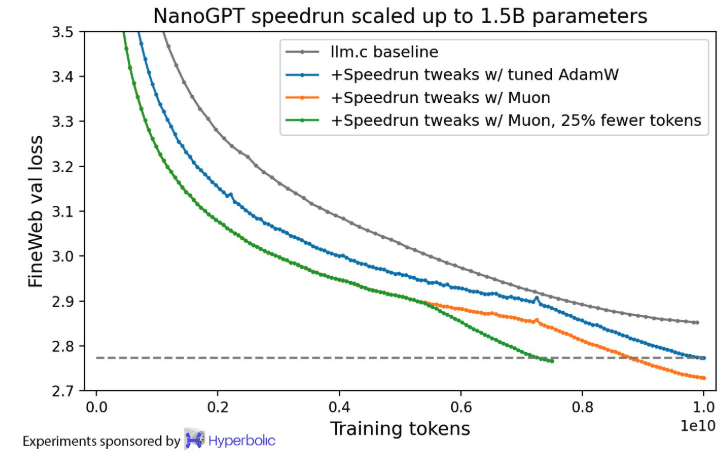
图 3 Muon 与 AdamW 在 15 亿参数短时间训练中的对比
从设计上来看,Muon 的核心原理是——先用带动量的 SGD(SGD-momentum)生成更新,再对每个更新矩阵进行一次 Newton-Schulz(NS)迭代处理,最后才将其应用到模型参数上。

它的实现也较为简单:
# Pytorch codedef newtonschulz5(G, steps=5, eps=1e-7): assert G.ndim == 2 a, b, c = (3.4445, -4.7750, 2.0315) X = G.bfloat16() X /= (X.norm() + eps) if G.size(0) > G.size(1): X = X.T for _ in range(steps): A = X @ X.T B = b * A + c * A @ A X = a * X + B @ X if G.size(0) > G.size(1): X = X.T return X
Newton-Schulz 迭代的作用是对更新矩阵进行近似正交化,也就是说,它会执行如下操作:
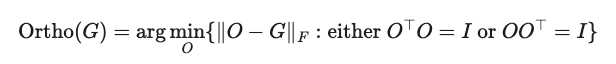
换句话说,NS 迭代的实际效果是:把原本由 SGD-momentum 得出的更新矩阵,替换成与之最接近的“半正交矩阵”。
感兴趣的小伙伴也可以通过 GitHub 地址快速找到 Muon 的 PyTorch 实现:https://github.com/KellerJordan/Muon

写在最后
Keller 的经历并不是在否定学术的价值,而是在提醒我们:在 AI 快速演进的当下,影响力的来源正在悄然改变。
一篇实测效果出色的博客文章,可能比一篇格式完美却难落地的论文更具说服力。
这也让我们联想到 DeepSeek,这支队伍同样是走出了一条“技术效果优先”的成名路径:没有高调预热,没有复杂包装,靠着实打实的性能和稳定表现,在激烈的大模型竞赛中杀出重围,迅速赢得社区认可。
对当下的 AI 研究者来说,也许是时候重新思考:什么才是真正值得投入时间的事?是一篇“看起来很强”的论文,还是一个“跑得足够快”的模型?Keller 和 Muon 的爆红,或许只是这一转变的开始。
参考:
Muon 博客原文:https://kellerjordan.github.io/posts/muon/
https://x.com/Yuchenj_UW/status/1934291648542126580
https://x.com/hyhieu226/status/1934290217516793947
https://x.com/kellerjordan0/status/1934138033240146313
📢 2025 全球产品经理大会
8 月 15–16 日
北京·威斯汀酒店
2025 全球产品经理大会将汇聚互联网大厂、AI 创业公司、ToB/ToC 实战一线的产品人,围绕产品设计、用户体验、增长运营、智能落地等核心议题,展开 12 大专题分享,洞察趋势、拆解路径、对话未来。
更多详情与报名,请扫码下方二维码。




















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











