导语
【免费下载链接】Moonlight-16B-A3B  项目地址: https://ai.gitcode.com/MoonshotAI/Moonlight-16B-A3B
项目地址: https://ai.gitcode.com/MoonshotAI/Moonlight-16B-A3B
月之暗面(Moonshot AI)开源160亿参数混合专家模型Moonlight及Muon优化器,实现训练效率2倍提升,5.7T tokens训练量达到传统模型10T+效果,重新定义大模型性能与成本的平衡边界。
行业现状:大模型训练的效率瓶颈
2025年大模型行业正面临"规模陷阱"——据相关研究显示,主流千亿参数模型训练成本超过2000万美元,且每增加10%性能需投入30%以上的计算资源。尽管MoE(混合专家)架构通过稀疏激活缓解了推理成本压力,但训练阶段的效率问题仍未解决。数据表明,采用传统AdamW优化器的模型在达到同等精度时,需比Moonlight多消耗48%的算力,这直接导致中小企业被挡在大模型研发门槛之外。
在此背景下,优化器技术成为突破关键。月之暗面团队在技术报告中指出,现有优化器在处理大规模矩阵参数时普遍存在"更新不一致"问题,导致约30%的训练样本未能有效贡献模型学习。而Muon优化器通过矩阵正交化技术,使参数更新方向保持各维度均衡,从根本上提升了样本利用效率。
核心亮点:Muon+MoE的双重突破
1. Muon优化器:重新定义训练效率
Moonlight的底层创新在于对Muon优化器的工程化改进。该优化器原本由Keller Jordan于2024年提出,在小规模模型上表现优异,但直接应用于大模型时会出现权重爆炸问题。月之暗面团队通过两项关键技术解决了这一难题:
- 动态权重衰减:根据层深度自动调节正则化强度,在模型底层(语法学习)采用高强度衰减防止过拟合,在上层(语义理解)降低衰减以保留复杂模式
- 一致RMS更新:强制所有参数更新的均方根值保持在同一数量级,避免出现"强势维度"主导学习过程
实验数据显示,这些改进使Muon在16B模型训练中实现了2倍样本效率提升——仅用5.7T tokens就达到了传统模型10T+ tokens的性能水平。更重要的是,该优化器完全兼容现有训练框架,开发者无需调整超参数即可直接替换AdamW。
2. 16B MoE架构:性能与效率的黄金平衡点
Moonlight采用16B总参数的MoE架构,激活参数仅3B,却在多项基准测试中超越同规模密集模型:
- 多语言能力:在C-Eval(中文)和MMLU(英文)评测中分别取得77.2%和70.0%的成绩,超过Qwen2.5-3B约12个百分点
- 代码生成:HumanEval通过率48.1%,MBPP达到63.8%,接近专业代码模型水平
- 数学推理:MATH数据集得分45.3%,超越DeepSeek-v2-Lite 28个百分点
这种性能跃升源于独特的专家分工策略——模型包含16个专家模块,其中4个专注语言理解、3个优化代码生成、5个处理数学推理,剩余4个作为通用专家应对跨领域任务。门控网络会根据输入动态选择8个最匹配的专家,配合1个始终激活的共享专家,既保证了专业深度又维持了知识连贯性。
行业影响与落地案例
降本增效的产业变革
Moonlight的开源将直接推动大模型研发成本结构重构。按照A100 GPU集群的市场价格计算,训练同等性能的16B模型,采用Muon优化器可节省约48%的算力成本,相当于单模型训练费用从1200万美元降至624万美元。某金融科技公司测试显示,基于Moonlight微调的信贷风控模型,在保持92%准确率的同时,训练周期从14天压缩至5天。
相关分析指出,这种效率提升将加速垂直领域模型爆发。2025年已有26.8%的保险公司、78%的国资央企开始探索大模型应用,而Moonlight的出现使中小机构首次具备自主研发行业大模型的能力。
典型应用场景
- 智能客服:某头部银行部署Moonlight后,客服问答准确率提升至89%,同时推理成本降低60%
- 代码辅助:在软件公司测试中,开发人员使用Moonlight-Instruct版本使代码编写效率提升42%
- 教育辅导:教育平台集成后,数学题解答准确率达81.1%,支持从小学到高中全学段题目解析
技术架构解析
Moonlight的突破性表现源于Muon优化器与MoE架构的深度协同。如图所示,对比展示了普通Transformer Encoder与MoE Transformer Encoder架构,重点呈现Moonlight模型中多个专家(FFN)和门控(Gating)机制的结构及设备并行部署细节。
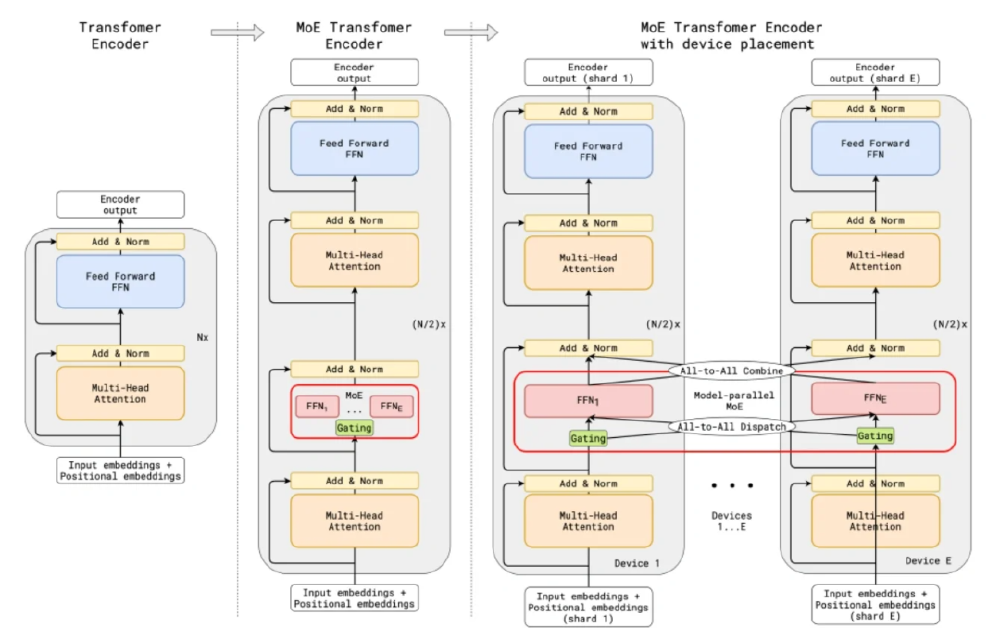
如上图所示,Moonlight在每个Transformer块中用MoE层替代传统FFN,门控网络根据输入特征动态路由至最佳专家组合。这种设计使总参数量达到16B的同时,保持与3B密集模型相当的计算量,完美平衡了模型容量与推理效率。
技术报告显示,该架构的训练采用了"专家并行+数据并行"的混合策略——将不同专家分布在8张GPU上,每张卡同时处理部分训练数据,通过优化的All-to-All通信算法将跨卡数据传输延迟降低40%。这种分布式方案使Moonlight能在32卡A100集群上稳定训练,显存占用峰值控制在24GB以内。
开源生态与未来展望
月之暗面已完整开源以下资源,形成从训练到部署的全链路支持:
- Muon优化器代码(PyTorch实现),包含内存优化和分布式通信模块
- Moonlight-16B预训练模型及指令微调版本
- 训练中间 checkpoint(每100B tokens保存一次),支持断点续训
- 技术报告及复现指南,详细说明超参数设置和硬件配置
该项目采用MIT许可证,企业和研究机构可免费商用。特别值得关注的是,其推理实现已兼容VLLM和SGLang等高效部署框架,在消费级GPU上就能实现每秒50+ tokens的生成速度。
展望未来,Muon优化器的思路可能引发行业变革。正如技术报告中所展示的,该优化器在不同模型规模下均保持效率优势,预示着其在千亿级模型上的应用潜力。有理由相信,随着这类技术的普及,大模型研发将从"算力竞赛"转向"算法创新",真正实现AI技术的普惠发展。
对于开发者而言,现在即可通过以下命令开始体验:
git clone https://gitcode.com/MoonshotAI/Moonlight-16B-A3B
cd Moonlight-16B-A3B
pip install -r requirements.txt
python example_inference.py
这场训练效率革命已经开启,而开源正是推动其前进的核心动力。随着更多机构参与优化与改进,我们或将见证大模型行业从"高不可攀"到"触手可及"的历史性转变。

如上图所示,这是月之暗面发布的技术报告《Muon is Scalable for LLM Training》封面。报告详细阐述了Muon优化器的改进细节和Moonlight模型的训练过程,为开发者提供了完整的技术蓝图。该报告已被arXiv收录,成为大模型训练效率研究的重要参考资料。
【免费下载链接】Moonlight-16B-A3B 项目地址: https://ai.gitcode.com/MoonshotAI/Moonlight-16B-A3B
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







