




 本文简要介绍了Spark的运行流程,从构建Spark Application环境到SparkContext申请Executor资源,再到DAG图的分解和Task的执行。同时,讨论了Spark分区的概念,包括文件分块、partition分区和shuffle分组。最后,阐述了SparkContext的角色,它是Spark应用的核心,负责创建RDD、累加器等,并与Spark执行环境建立连接。
本文简要介绍了Spark的运行流程,从构建Spark Application环境到SparkContext申请Executor资源,再到DAG图的分解和Task的执行。同时,讨论了Spark分区的概念,包括文件分块、partition分区和shuffle分组。最后,阐述了SparkContext的角色,它是Spark应用的核心,负责创建RDD、累加器等,并与Spark执行环境建立连接。
1.简述Spark运行流程:
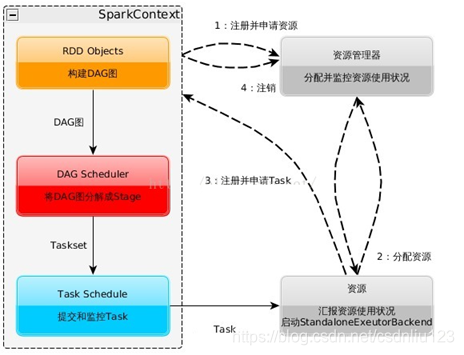
1.构建Spark Application的运行环境,启动SparkContext
2. SparkContext向资源管理器(可以是Standalone, Mesos, Yarm)申请运行Executor资源, 并启动
StandaloneExecutorbackend
3. Executor向SparkContext申请Task
4. SparkContext将应用程序分发给Executor
5. SparkContext构建成DAG图,将DAG图分解成Stage、将Taskset发送给Task Scheduler,最后由Task Scheduler将Task发送
给Executor运行
6. Task在Executor上运行,运行完释放所有资源
2.简述Spark分区:
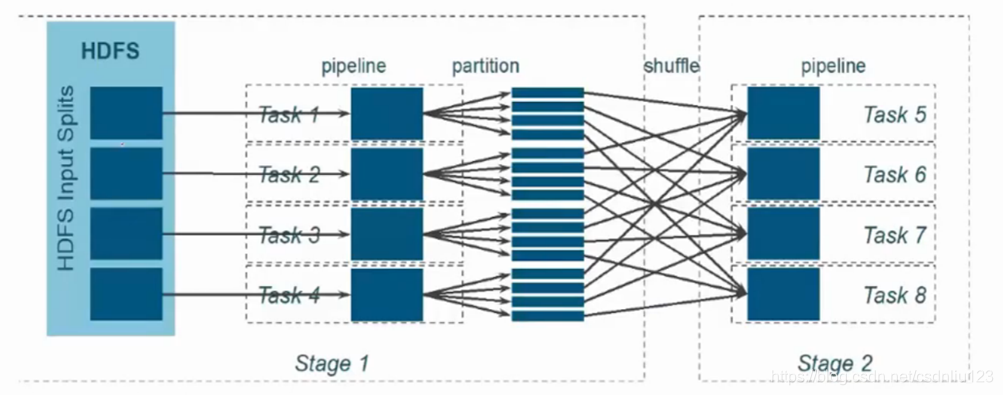
Spark分区分为两个阶段:
在分布式文件系统上文件是分块存储的,将文件块发送给task,将文件进行partition分区,经过shuffle分组,shuffle分组发送给下一个Task进行运算。默认情况下,每个核心一次执行一个任务,每个分区一个任务,每次分割一个分区。
3.简述sparkContext:
s
parkContext是Spark的入口,相当于应用程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









