




 本文介绍了SparkSQL中分析函数的语法,包括sum、max、min、count、avg等聚合函数以及lead、lag、rank等排名函数。重点解析了over关键字、partition by、order by和rows/range子句的功能。并通过rank()排名函数、lag()和lead()比较函数以及range()和rows()窗口函数的案例进行了深入讲解。
本文介绍了SparkSQL中分析函数的语法,包括sum、max、min、count、avg等聚合函数以及lead、lag、rank等排名函数。重点解析了over关键字、partition by、order by和rows/range子句的功能。并通过rank()排名函数、lag()和lead()比较函数以及range()和rows()窗口函数的案例进行了深入讲解。
1分析函数的语法:
分析函数名(参数) over(partition by子句order by子句rows/range子句)
1.1分析函数名:
sum、max、 min、 count、 avg等聚合函数
lead、 lag等比较函数
rank等排名函数
1.2over关键字
表示前面的函数是分析函数,不是普通的聚合函数
1.3分析子句: over关键字后面括号内的内容为分析子句,包含以下三部分内容.
partition by :分组子句,表示分析函数的计算范围,各组之间互不相干
order by:排序子句,表示分组后,组内的排序方式
rows/range: 窗口子句,是在分组(partition by)后,表示组内的子分组(也即窗口),是分析函数的计算范围窗口
2案例:
2.1 rank()排名函数案例:
package sparkSql
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
object sparkSql_fenxi {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder().master("local[2]")
.appName("Spark SQL analytic function example")
.getOrCreate()
spark.sqlContext.sparkContext.setLogLevel("WARN")
import spark.implicits._
val connectionProperties = new Properties() ;
connectionProperties.put("user", "root")
connectionProperties.put("password", "123")
val jdbcDF: DataFrame = spark.read.jdbc("jdbc:mysql://spark1:3306/sparktest", "score", connectionProperties)
//jdbcDF.show()
jdbcDF.createOrReplaceTempView("student_score")
//row_number()
//dense_rank()
val result: DataFrame = spark.sql("select id,name,class,score,row_number() over(partition by class order by score desc) as topn from student_score")
result.show()
println("______________________________________________________")
val result1: DataFrame = spark.sql("select id,name,class,score,dense_rank() over(partition by class order by score desc) as topn from student_score")
result1.show()
println("______________________________________________________")
val result2: DataFrame = spark.sql("select id,name,class,score,rank() over(partition by class order by score desc) as topn from student_score")
result2.show()
}
}
raw_number(): dense_rank(): rank():
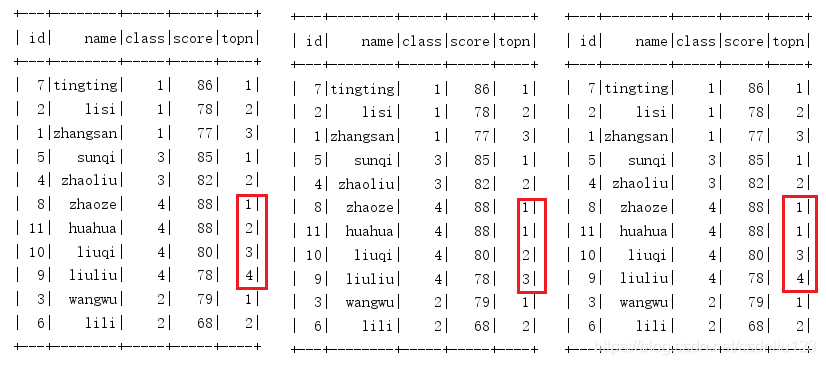
2.2lag() ,lead() 函数使用及案例:
lag ,lead 分别是向前,向后;
lag 和lead 有三个参数,第一个参数是列名,第二个参数是偏移的offset,第三个参数是 超出记录窗口时的默认值)
package sparkSql
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
object sparkSql_avg_score {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder().master("local[2]")
.appName("Spark SQL analytic function example")
.getOrCreate()
spark.sqlContext.sparkContext.setLogLevel("WARN")
import spark.implicits._
val connectionProperties = new Properties() ;
connectionProperties.put("user", "root")
connectionProperties.put("password", "123")
val jdbcDF: DataFrame = spark.read.jdbc("jdbc:mysql://spark1:3306/sparktest", "score", connectionProperties)
//jdbcDF.show()
jdbcDF.createOrReplaceTempView("student_score")
val test=spark.sql("select id,class,score,lag(score,1) over (partition by class order by score desc ) as top_value ,lead(score,1) over (partition by class order by score desc) as last_value from student_score ")
test.show()
println()
val result1 = spark.sql("select class,score from (select id,class,score,lag(score,1) over (partition by class order by score desc ) as top_value ,lead(score,1) over (partition by class order by score desc) as last_value from student_score) t where t.top_value is null or t.last_value is null ")
result1.show()
println()
val result2 = spark.sql("select class,avg(score) from (select id,class,score,lag(score,1) over (partition by class order by score desc ) as top_value ,lead(score,1) over (partition by class order by score desc) as last_value from student_score) t where t.top_value is null or t.last_value is null group by class ")
result2.show()
}
}

4.3range()和rows()的使用及案例:
package sparkSql
import java.util.Properties
import org.apache.spark.sql.{DataFrame, SparkSession}
object range_rows {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder().master("local[2]")
.appName("Spark SQL analytic function example")
.getOrCreate()
spark.sqlContext.sparkContext.setLogLevel("WARN")
import spark.implicits._
val connectionProperties = new Properties() ;
connectionProperties.put("user", "root")
connectionProperties.put("password", "123")
val jdbcDF: DataFrame = spark.read.jdbc("jdbc:mysql://spark1:3306/sparktest", "score", connectionProperties)
jdbcDF.createOrReplaceTempView("student_score")
val result_range = spark.sql(" select class,score,sum(score) over(partition by class order by score desc range between 1 preceding and 2 following) as sum_value from student_score")
result_range.show()
println()
val result_rows = spark.sql(" select class,score,sum(score) over(partition by class order by score rows between 1 preceding and 2 following) as sum_value from student_score")
result_rows.show()
spark.close()
}
}



















 22
22

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









