




 Ansor是一种针对深度学习的自动程序生成框架,旨在解决从高级声明式语言生成高性能张量程序的挑战。通过分层搜索空间,Ansor避免了手动模板开发和早期修剪的问题,实现了全面的搜索。它包括程序采样器、性能调试器和任务调度器,能为深度学习模型的各个子图生成和优化张量程序,从而在多种硬件平台上提供高性能的推理。在评估中,Ansor在单个算子、子图和端到端网络的基准测试中表现出优于现有方法的性能。
Ansor是一种针对深度学习的自动程序生成框架,旨在解决从高级声明式语言生成高性能张量程序的挑战。通过分层搜索空间,Ansor避免了手动模板开发和早期修剪的问题,实现了全面的搜索。它包括程序采样器、性能调试器和任务调度器,能为深度学习模型的各个子图生成和优化张量程序,从而在多种硬件平台上提供高性能的推理。在评估中,Ansor在单个算子、子图和端到端网络的基准测试中表现出优于现有方法的性能。
1、背景
深度神经网络(DNN)的低延迟推理在自动驾驶、增强现实、语言翻译等应用中起着至关重要的作用。为了获得高性能,现有的深度学习框架(如TensorFlow、PyTorch、MXNet)基于硬件厂商提供的内核库(如cuDNN、MKL-DNN)来实现DNN中的算子。然而,这些内核库针对于不同硬件和算子均需要大量的工作来开发特定的优化代码,严重限制了新算子的开发。
为了以高效的方式在各种硬件平台上部署这些算子时都保持高性能,已经引入了多种编译器技术(如TVM、Halide、Tensor Comprehensions)。用户使用高级声明式语言以类似于数学表达式的形式定义计算,编译器根据定义生成优化的张量程序。
然而,从高级定义中自动生成高性能张量程序是极其困难的。根据目标平台的架构,编译器需要在包含优化组合选择(如tile structure, tile size, vectorization, parallelization)的极其庞大和复杂的空间中进行搜索。寻找高性能程序需要搜索策略覆盖一个全面的空间并进行有效地探索。其中,两种最新且有效的搜索方法为模板引导搜索和基于序列结构的搜索。
在模板引导搜索中,搜索空间由手动模板定义。如图1a所示,编译器(例如,TVM)要求用户手动为计算定义编写模板。该模板使用一些可调参数(如tile size和unrolling factor)定义了张量程序的结构。然后编译器为特定的输入形状和硬件目标搜索这些参数的最佳值。该方法在常用的深度学习算子上取得了很好的效果。但是,开发模板需要大量的工作,并且构造一个高质量的模板需要张量算子和硬件方面的专业知识。此外,手动模板仅涵盖有限的程序结构,因为手动枚举所有算子的所有优化选择是几乎不可能的。
基于序列结构的搜索通过将程序结构分解为一系列固定的决策来定义搜索空间。然后,编译器使用诸如beam search之类的算法来搜索好的决策(如Halide auto-scheduler)。在这种方法中,编译器通过依次展开计算图中的所有节点来构造张量程序。对于每个节点,编译器会对如何将其转换为低级张量程序做出一些决策(如computation location, storage location, tile size)。当所有节点展开时,构造一个完整的张量程序。这种方法为每个节点使用一组通用的展开规则,因此它可以自动搜索而不需要手动模板。由于每个决策的可能选择数较大,为了使序贯过程可行,该方法在每个决策后只保留前k个候选方案。编译器基于一个可学习的cost model评估和比较候选程序的性能,以选择前k个候选程序。在搜索过程中,候选程序是不完整的,因为只展开了部分计算图或做出了部分决策。图1b显示了这个过程。但是,在完整程序上训练的cost model不能准确地预测不完整程序的最终性能,并且顺序决策的固定顺序限制了搜索空间的设计。
Ansor是基于分层搜索空间构建的,如图1c所示,该空间将高级结构和低级细节解耦。Ansor自动构造计算图的搜索空间,无需手动开发模板。Ansor从空间中采样完整的程序,并对完整的程序进行微调,避免了对不完整程序的粗略估计。图1显示了Ansor方法和现有方法之间的主要区别。
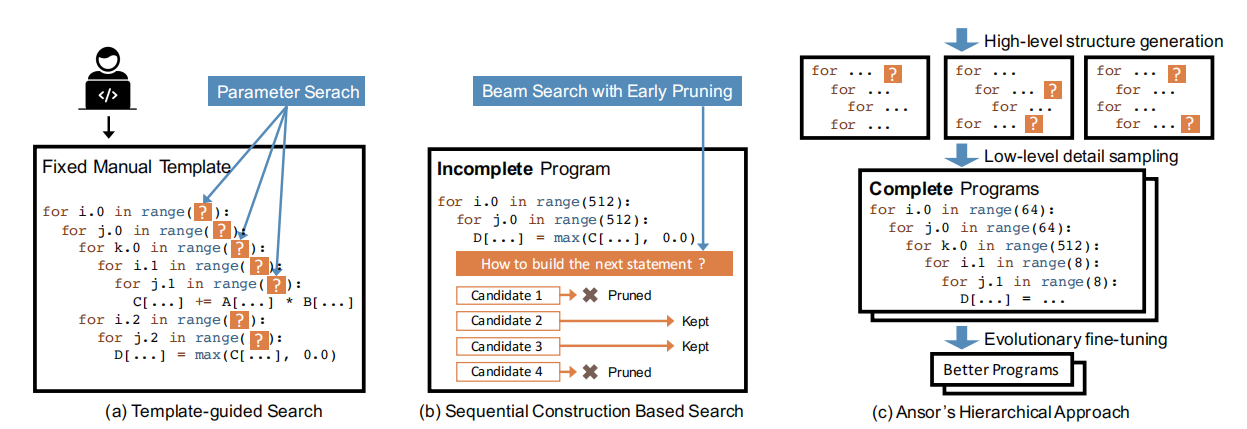
图1 搜索策略比较
2、设计概述
Ansor是一个自动生成张量程序的框架。图2显示了Ansor的总体架构。Ansor的输入是一组待优化的DNN模型。Ansor使用Relay的算子融合算法将DNN从流行的模型格式(如ONNX,TensorFlow PB)转换为小的子图。然后,Ansor为这些子图生成张量程序。Ansor有三个主要组成部分:(1)程序采样器,它构造了一个大的搜索空间并从中抽取不同的程序;(2)性能调试器,用于微调所采样程序的性能;(3)任务调度器,为优化DNN中的多个子图分配时间资源。

图2 Ansor总体架构
3、架构详解
3.1 Program Sampler
算法探索的搜索空间决定了它可以找到的最佳程序。现有方法中考虑的搜索空间受到以下因素的限制:(1)手动枚举(如TVM)。通过模板手动枚举所有可能的选择是不切实际的,因此现有的手动模板只能启发式地覆盖有限的搜索空间。(2)过度早期修剪(如Halide auto-scheduler)。基于评估不完整程序的过度早期修剪阻止了算法探索空间中的某些区域。
为了解决上述问题,Ansor通过递归地应用一组灵活的推导规则来自动扩展搜索空间,并在搜索空间中随机采样完整的程序。由于随机采样为每个要采样的点提供了均等的机会,因此搜索算法可以潜在地探索所考虑空间中的每个程序。不依赖随机采样来找到最佳程序,因为每个采样程序后还会进行微调。
为了采样可以覆盖大搜索空间的程序,Ansor定义了一个具有两个级别的分层搜索空间:sketch和annotation。将程序的高级结构定义为sketches,并将数十亿个低级选择(如tile size、unroll annotations)作为annotations。在顶层,通过递归应用一些推导规则来生成sketch,在底层,随机注释这些sketch以获得完整的程序。这种表示从数十亿个低级选择中总结了一些基本结构,实现了高级结构的灵活枚举和低级细节的有效采样。
3.1.1 草图生成
Ansor提出了一种基于推导的枚举方法,通过递归地应用几个基本规则来生成所有可能的sketches。此过程将DAG作为输入并返回草图列表。定义状态函数σ = (S,i),其中S是DAG当前部分生成的草图,i 是当前工作节点的索引。DAG中的节点按从输出到输入的拓扑顺序排序。推导从初始naive程序和最后一个节点开始,将所有推导规则递归地应用于状态。对于每个规则,如果当前状态满足应用条件,将规则应用到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1635
1635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









