



 MNN是一个由阿里巴巴开发的轻量级深度神经网络推理引擎,用于在移动端实现高效的模型推理。它支持多种训练框架,如Tensorflow Lite、Caffe和ONNX,并在多款阿里系App中广泛应用。MNN的工作流程包括模型转换和端上推理,其中端上推理涉及Pre-inference、算子优化和Backend Abstraction等步骤。Pre-inference阶段,MNN通过代价评估选择最优计算方案,内核优化中应用Winograd算法和Strassen算法提高性能,同时提供Backend Abstraction以适配不同硬件平台。
MNN是一个由阿里巴巴开发的轻量级深度神经网络推理引擎,用于在移动端实现高效的模型推理。它支持多种训练框架,如Tensorflow Lite、Caffe和ONNX,并在多款阿里系App中广泛应用。MNN的工作流程包括模型转换和端上推理,其中端上推理涉及Pre-inference、算子优化和Backend Abstraction等步骤。Pre-inference阶段,MNN通过代价评估选择最优计算方案,内核优化中应用Winograd算法和Strassen算法提高性能,同时提供Backend Abstraction以适配不同硬件平台。
1.MNN介绍
随着手机算力的不断提升,以及深度学习的快速发展,特别是小网络模型不断成熟,原本在云端执行的推理预测就可以转移到端上来做。端智能即在端侧部署运行AI算法,相比服务端智能,端智能具有低延时、兼顾数据隐私、节省云端资源等优势。
MNN(Mobile Neural Network)一个轻量级的深度神经网络推理引擎,在端侧加载深度神经网络模型进行推理预测。目前,MNN已经在阿里巴巴的手机淘宝、手机天猫、优酷等20多个App中使用,覆盖直播、短视频、搜索推荐、商品图像搜索、互动营销、权益发放、安全风控等场景。此外,IoT等场景下也有若干应用。

图 1:MNN概述图
2.MNN整体方案

图 2:MNN框架
由上图所示,MNN基本的工作流由两部分组成,即Offline Conversion和On-device Inference。
Converter由Frontends和Graph Optimize构成。前者负责支持不同的训练框架,MNN当前支持Tensorflow(Lite)、Caffe和ONNX(PyTorch/MXNet的模型可先转为ONNX模型再转到MNN),最终全部转换为MNN自定义的模型格式(.mnn);后者通过算子融合、算子替代、模型压缩、布局调整等方式对图进行基本的优化操作。
On-device Inference由三部分组成,分别是:Pre-inference、算子级优化和Backend Abstraction。在Pre-inference模块中引入了一种对可选计算方案的代价评估机理,在已知输入大小和内核形状的前提下,从多种方案中选择一种最优的方案;算子级优化主要包括在卷积和反卷积中应用Winograd算法、在矩阵乘法中应用Strassen算法、低精度计算、手写汇编、多线程优化、内存复用等;Backend Abstraction主要是提供了一套统一的接口来隐藏后端的差异,支持多种硬件架构,支持OpenCL,OpenGL,Vulkan和Metal等,可以方便地进行扩展,比如TPU、FPGA等。
3. Pre-inference

图 3:加速方案选择
在移动应用中,计算速度和轻量化是主要考虑的因素,为了实现轻量化,就不能使用OpenBLAS和Eigen等加速库,所以有一些推理引擎框架中使用手工搜索的方式,不依赖于任何外部库,使用汇编指令case by case地实现算子,这种方式可以使推理引擎变得轻量化和高效,但是case by case的优化是非常耗时的,而且很难覆盖所有算子。这种推理引擎的代表如NCNN (Tencent, 2017),MACE (Xiaomi, 2018)和Anakin (Baidu, 2018)。
与手工搜索形成强烈对比的是全自动搜索,其典型代表是TVM,它不仅解决了多余依赖的问题,同时为模型和后端提供了图级和算子级的优化,所以TVM在模型和设备多样性方面的支持非常好,但是这也是有代价的,TVM生成的运行时是模型特例化的,换句话说,当需要更新模型时,就需要TVM重新生成运行时库,这对于移动应用来说是不可接受的。MNN采用的是一种半自动搜索的方式,在通用性和高性能上都实现了增强。
3.1 计算方案选择
MNN实现了一种代价评估机理,充分考虑了算法实现和后端特性,从多种实现方案中找到最优的方案,如下是代价计算公式:

为了使总的代价最小,那么就需要在算法和后端上分别选择最快的方式,针对算法部分的代价,以卷积为例,目前最快的实现算法有两种选择Sliding window和Winograd,针对各种各样的卷积配置,动态地选择计算代价最小的算法,选择方式是:
- 如果kernel size为1,就是一个矩阵乘,那么使用Strassen算法是最合适的。
- 如果kernel size大于1,使用Winograd 将卷积操作转换为矩阵乘,理论上卷积的代价用如下公式表示:
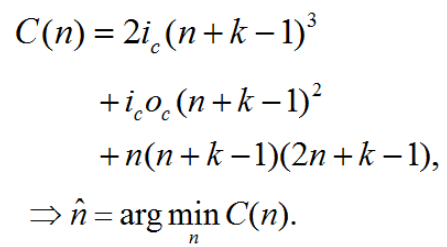
基于这个公式,可以选择最优的输出大小来最小化cost。所以对于卷积的代价评估如下:
第二个问题就是怎么计算后端的代价,最小化后端代价,其实就是针对每个算子,选择最佳的后端,这样可以保证全局是代价最小的:

3.2 准备—执行解耦
在程序执行期间,正常情况下计算是伴随着内存的申请和释放的,对于移动应用来说,在内存管理上的开销是不可忽视的。考虑到输入大小已经确定,引擎可以将所有的算子虚拟执行一遍,得到确切的内存需求。这样的话,可以在Pre-Inference阶段预先将需要的内存分配出来,并在在执行阶段重复利用,原理如图4所示:
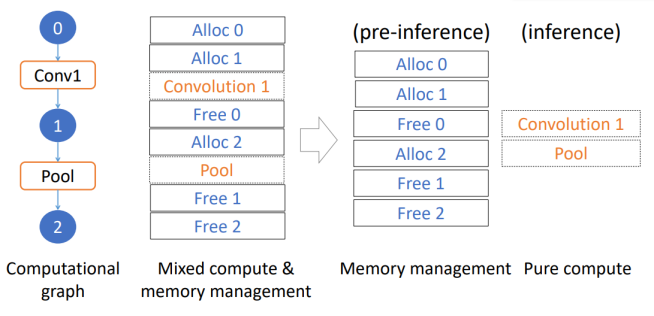
图 4:内存分配和计算解耦
MNN宣称采用准备—执行解耦,在CPU上有7%~8%的提升,在GPU上50%~75%的提升,GPU上提升明显,是因为GPU上需要设置命令Buffer和与之相关的命令描述等,这些工作对于GPU来说也是非常耗时的,将其放在准备阶段,能有非常大的性能提升。
4. 内核优化
内核指的是一个算子的详细实现。这块的优化主要来源于两个方面:算法和调度,即选择具有最低复杂度的算法和对硬件资源进行充分利用。
4.1 Winograd 优化
Winograd快速卷积算法已经被很多推理框架所广泛采用,定义如下:
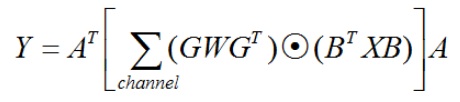
其中内核W(大小为[k,k]),输入为X(大小为[n+k-1,n+k-1]),输出Y(大小为[n,n]),G,B,A分别为对应的转换矩阵。
4.1.1 块划分和Pipelining
在Winograd卷积算法中,X只是整个输入的一小部分,问题是怎么进行块划分,划分多少个块?从输出看,假如输出的大小为[],用T表示每次并行计算的Blocks数,则T为:
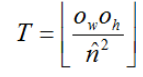
其中![]() 为Pre-Inference阶段提到过的最优的输出大小。
为Pre-Inference阶段提到过的最优的输出大小。
当Blocks被并行执行时,必须尽力避免管道停滞以隐藏延迟,MNN中使用汇编指令实现了Pipelining技术。
4.1.2 Hadamard product 优化
在Winograd卷积中Hadamard product是一个基本的步骤,但是有一个问题,就是内存访问比较耗时,影响了整体的性能。
如果将Hadamard product转换为Dot product,多个Dot product转换为矩阵乘,这为并行化提供了有利条件,并且有利于降低内存访问的开销。使用data layout re-ordering技术可以实现将Hadamard product转换为矩阵乘。
MNN中使用的数据布局方式是NC4HW4,引入了一个新的维度,在这个维度上,每4个元素在内存中的存储是连续的,这样可以充分利用CPU的向量寄存器,实现在一条指令中计算4个元素(例如SIMD),原理如图5所示。
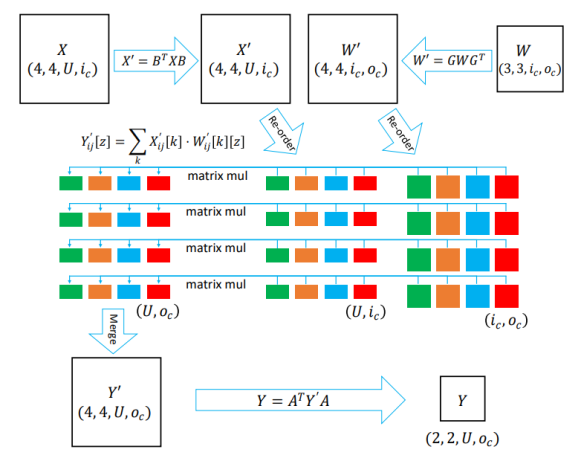
图 5:哈达玛乘积优化
4.1.3 Winograd generator
很多推理框架使用Winograd都是硬编码,即对应于内核和输入大小的A,B,G三个矩阵都是确定的,这样在面对新的情形时,扩展性相对差点,为此,MNN使用了Winograd generator,使得Winograd能够适应任意的内核和输入大小。
4.2 大矩阵乘优化
对于kernel大小为1的卷积操作,实际上就是一个矩阵乘,在MNN中使用了Strassen算法来对矩阵乘进行优化,MNN是第一个采用Strassen算法优化大矩阵乘的移动推理引擎。
Strassen是将若干乘操作用加法操作进行替代,一般来说,处理器执行加法操作要比乘法操作快很多,从而有了提速的效果,这种加速效果当使用递归调用时可以最大化,需要决定递归结束的条件。
对于一个[n,k]×[k,m]的矩阵乘,包含的乘法操作有mnk,但是使用Strassen算法可以将乘法操作减少到![]() ,但同时引入了4个大小为
,但同时引入了4个大小为![]() 的加法,4个大小为
的加法,4个大小为![]() 的加法和7个大小为
的加法和7个大小为![]() 的加法,所以Strassen递归结束的条件就是引入的加法操作小于减少的乘法操作的代价,如下:
的加法,所以Strassen递归结束的条件就是引入的加法操作小于减少的乘法操作的代价,如下:
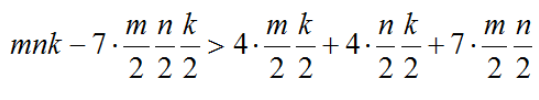
使用Strassen优化大矩阵乘的效果如下表所示:

5. Backend Abstraction
MNN支持多种硬件平台(GPU,CPU,TPU等)和软件计算库(OpenCL,OpenGL,Vulkan等),为了隐藏底层的差异,MNN封装了一个Backend类,提供了统一的抽象接口,如图6所示,onAcquireBuffer负责申请内存,onReleaseBuffer负责释放内存,onCreate 用来为每个OP创建一个执行示例。

图 6:MNN的backend类
这样做的好处有:
- 降低复杂性
通过后端抽象,可以将一个任务分成两个独立的部分,前端部分开发者主要负责OP的高效实现,而不用关心后端细节,后端开发者致力于开发不同的后端规范并提供更方便的API。任务的这种分离在实践中非常有意义,而且在开源项目中很受欢迎,因为这样设计降低了贡献的障碍。
- 启用混合调度
异构计算主要的问题是后端选择和在不同的后端之间传输数据,如果有多种后端可供选择,在Pre-Inference阶段已经预先评估出最优的后端配置。MNN支持在同一个Session内部混合使用不同的后端进行OP的执行。
- 便于轻量化
每个后端的实现可以作为独立的组件工作,同时保持在MNN中有统一接口,但是有些后端在某些设备上是不支持的,那么这个后端对应的所有组件可以从框架中移除,比如安卓平台是不支持Metal的,那么可以把Metal的实现全部移除。这种OP实现和后端分离的设计非常便于实现轻量化,这对于移动应用来说非常重要。
6. 总结
与近几年推出的NCNN/MACE/TF-Lite等推理引擎相比,MNN用一句话来概况:后发优势明显,对硬件支持完善,速度基本全面超越。MNN自2019年5 月宣布开源以来,经历两次淘宝双十一的洗礼,并在手淘、UC、飞猪、千牛等20多个集团App中使用,覆盖了直播、短视频、搜索推荐等多种应用场景,随着业务需求也在不断迭代和优化,已经相对成熟和完善。
7. 参考文献
[1] https://arxiv.org/abs/2002.12418
[2] https://www.yuque.com/mnn/cn/about
[3] https://github.com/alibaba/MNN
[4] https://www.mnn.zone/


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









