




 BOLT是基于TVM框架的优化工具,通过深度融合和性能分析器提升GPU上卷积神经网络的推理速度,将速度提升2.5倍,减少搜索时间。BOLT结合NVIDIA CUTLASS,实现Persistent kernel和Perf profiler,以优化图和算子级别,提升实际部署中的性能。
BOLT是基于TVM框架的优化工具,通过深度融合和性能分析器提升GPU上卷积神经网络的推理速度,将速度提升2.5倍,减少搜索时间。BOLT结合NVIDIA CUTLASS,实现Persistent kernel和Perf profiler,以优化图和算子级别,提升实际部署中的性能。
本文介绍的BOLT基于TVM框架,在GPU平台上进行了进一步的图优化和算子优化,最终将常见的卷积神经网络模型的推理速度提升了2.5倍,搜索时间大大缩减,可以实现20分钟内完成自动搜索调优。下面对BOLT的主要技术细节进行介绍。
1 背景
NVIDIA CUTLASS 是一个开源项目,是 CUDA C++ 模板抽象的集合,用于在 CUDA 内部实现高性能矩阵乘法和卷积运算。它定义了一系列高度优化的算子组件,开发人员可以通过组合这些组件,开发出性能和 CUDNN、CUBLAS 相当的线性代数算子。CUTLASS 通过将计算拆分为 thread block tiles、warp tiles 和 thread tiles,高效地实现了GPU 中的矩阵乘法。如图 1 所示,可以看到数据从全局内存移动到共享内存,从共享内存移动到寄存器,从寄存器移动到 SM CUDA Cores 进行计算。

图1 CUTLASS 中 GEMM 计算的拆分过程
目前,在GPU平台上,TVM使用自动搜索得到的性能与 CUTLASS 算子库的性能存在很大的差距。TVM 需要一个 tophub 数据库来存储各种shape的调优调度,当给定一个以前没有搜索过的shape时,将会花费几个小时去搜索或者转到性能很差的默认调度;此外,针对不同数据类型,TVM auto scheduler 不能良好支持NVIDIA Tensor Core 指令。这些问题阻碍了 TVM 在真实的推理部署场景中落地应用,针对以上情况,BOLT提出将 CUTLASS 引入到 TVM Codegen 中,并利用其算子融合能力,大幅提升模型性能。据论文作者所述,BOLT 已经部署在真实生产环境中,并且代码已经合入到TVM项目中。
2 BOLT设计
图 2 显示了 BOLT 的整体架构。BOLT基于TVM框架,采用BYOC(Bring Your Own Codegen)方法,将CUTLASS引入到TVM。主要创新点有两个,一是图级优化——Deeper fusion,深度学习模型导入TVM,转化为relay IR后,进行更深层次的算子融合;二是算子级优化——Perf profiler,单纯的使用BYOC引入CUTLASS并不会直接得到最好结果,通过设计一个性能分析器来搜索最优参数,从而得到最优性能。
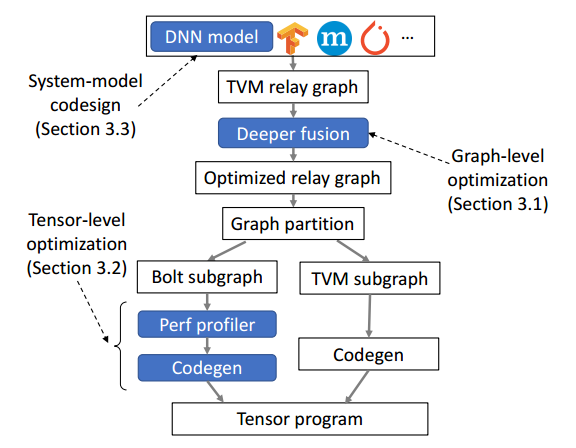
图2 Bolt 的工作流程(蓝框是创新点)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









