






本文来源公众号“阿旭算法与机器学习”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/0l2pMYWmgkpoyn8KoTBvKg
引言
本文将详细介绍Ultralytics YOLO系列目标检测器的演进历程、性能基准、部署应用及未来挑战,重点聚焦YOLOv5(2020)、YOLOv8(2023)、YOLO11(2024)和YOLO26(2025) 四大标志性版本。
-
核心主题:综述Ultralytics YOLO家族目标检测器的架构演进、性能基准、部署视角及未来挑战,重点分析4个里程碑版本,并对比非Ultralytics模型。
-
YOLO系列价值:自2016年首次发布以来,以“单阶段检测”设计平衡高精度与实时推理速度,成为计算机视觉(自动驾驶、机器人、医疗影像等)领域最具影响力的模型之一。
-
关键时间线:从早期Darknet框架的YOLOv1-YOLOv4,到Ultralytics主导的PyTorch化演进(YOLOv5→YOLOv8→YOLO11→YOLO26),最终实现多任务(检测、分割、分类等)原生统一。
Ultralytics YOLO四大核心版本详解
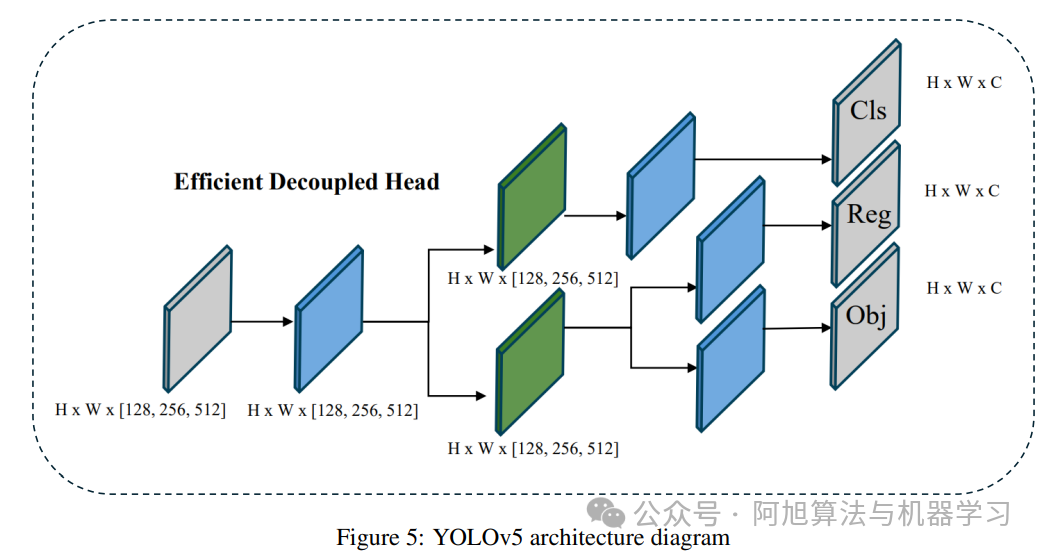
1. YOLOv5(2020)
在这里插入图片描述
-
关键架构创新:作为Ultralytics首个PyTorch原生实现的YOLO模型,它替代了传统Darknet框架;引入SiLU激活函数以缓解深层网络梯度消失问题,搭配PANet风格颈部增强多尺度特征聚合效果;采用模块化设计,骨干块、颈部层、检测头及损失函数等组件可灵活替换或扩展,无需大量重构代码。
-
支持任务:主要支持目标检测,后续通过社区扩展实现了有限的实例分割功能。
-
框架:PyTorch
-
核心性能亮点:在MS COCO验证集(640px输入,CPU/ONNX推理)中,nano变体(YOLOv5u-n)mAP约34.3%,推理延迟约73.6ms;small变体(YOLOv5u-s)mAP约43.0%,推理延迟约120.7ms,为后续版本提供了实用性能基准。
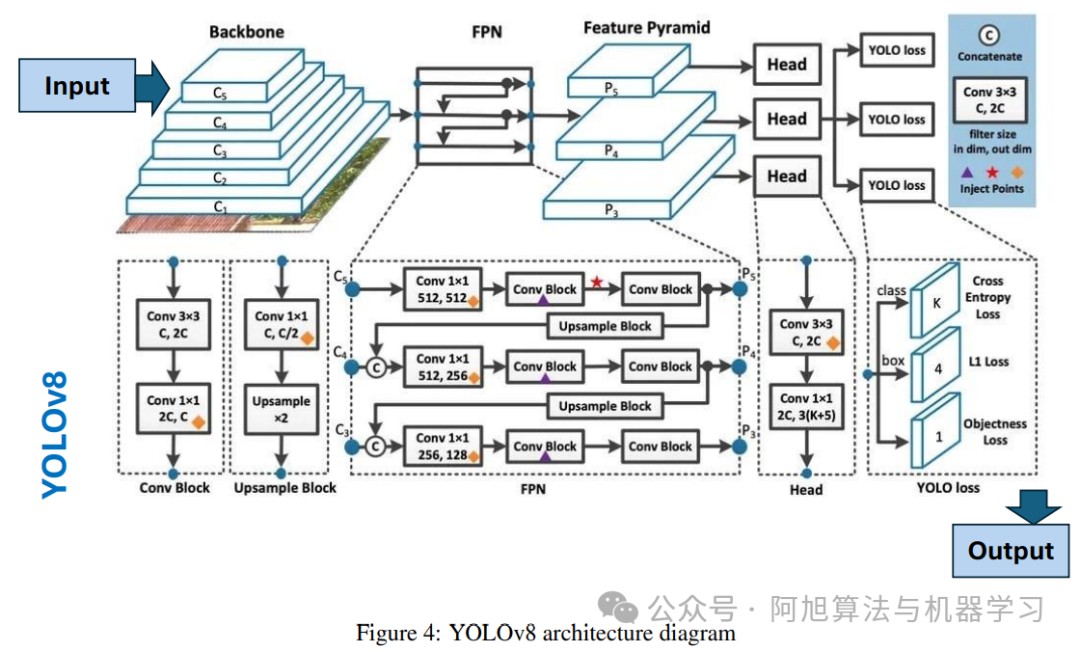
2. YOLOv8(2023)
在这里插入图片描述
-
关键架构创新:采用C2f轻量级骨干网络,在保持感受野丰富度的同时降低内存带宽压力;设计解耦检测头,分离分类与回归分支以减少梯度干扰,提升收敛平滑性;正式确立全无锚框预测策略,无需锚点聚类,增强对不同数据集目标长宽比的泛化能力;优化多尺度特征融合,注重stride对齐与 aliasing minimization,保留小目标关键空间信息。
-
支持任务:目标检测、实例分割、全景分割、关键点估计。
-
框架:PyTorch
-
核心性能亮点:MS COCO验证集(640px输入,CPU/ONNX推理)下,nano变体(YOLOv8n)mAP约37.3%,延迟约80.4ms;small变体(YOLOv8s)mAP约44.9%,延迟约128.4ms;medium变体(YOLOv8m)mAP约50.5%,延迟约197.5ms,精度与效率平衡较YOLOv5显著提升。
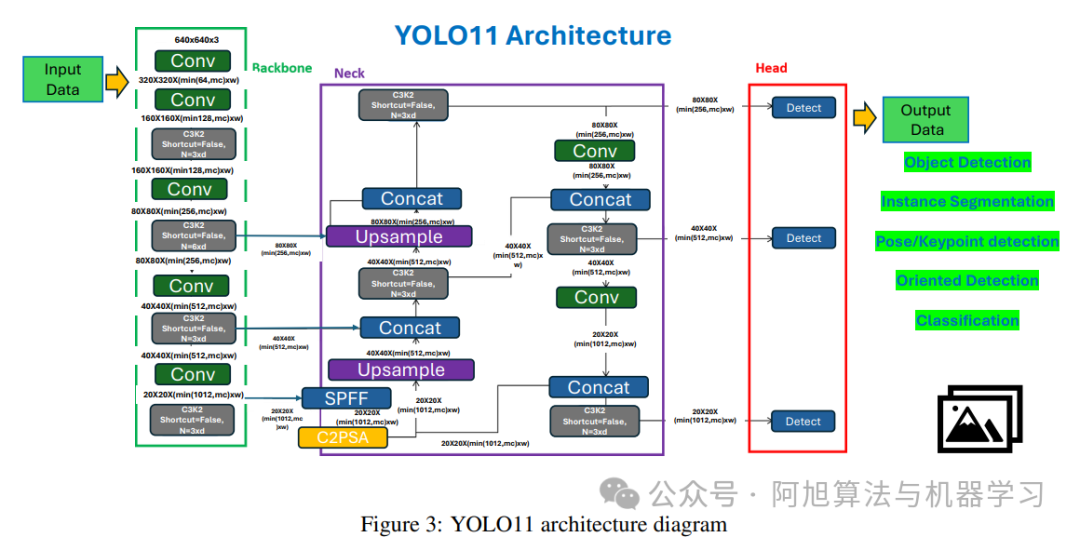
3. YOLO11(2024)
在这里插入图片描述
-
关键架构创新:引入C3k2 CSP瓶颈结构(小核CSP块),搭配C2PSA模块(CSP+空间注意力),提升特征复用效率与关键特征聚焦能力,优化FLOPs-to-mAP比值;采用混合任务感知分配策略,联合优化分类、定位及辅助任务的标签分配与损失权重,增强批量大小变化鲁棒性;颈部设计进一步优化多尺度融合,提升小目标定位精度。
-
支持任务:目标检测、实例分割、姿态估计、定向检测。
-
框架:PyTorch
-
核心性能亮点:MS COCO验证集(640px输入,CPU/ONNX推理)中,nano变体(YOLO11n)mAP约39.5%,延迟约56.1ms,较YOLOv5u-n精度提升且延迟降低;small变体(YOLO11s)mAP约47.0%,延迟约90.0ms;medium变体(YOLO11m)mAP约50.3%,延迟约171.0ms,小目标检测性能与效率优势突出。
4. YOLO26(2025)
在这里插入图片描述
-
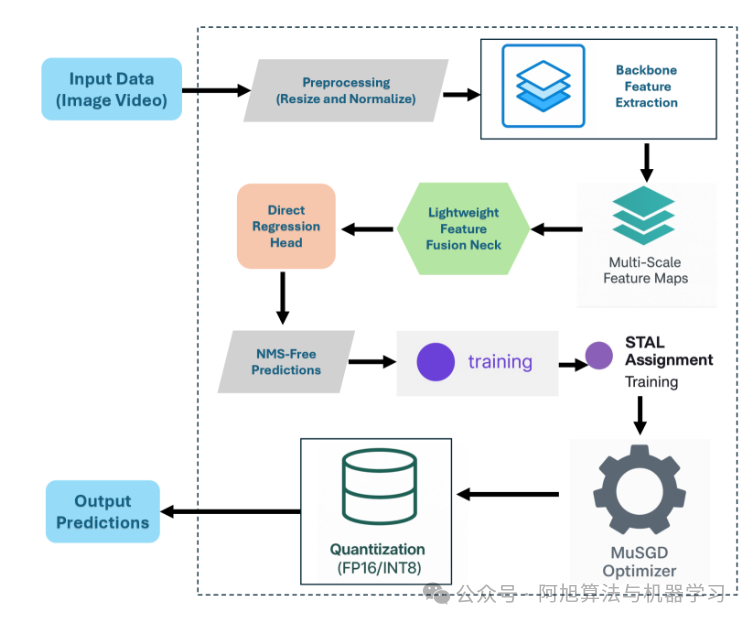
关键架构创新:移除DFL(分布焦点损失)与原生支持NMS-free端到端推理,简化计算图并消除后处理延迟与阈值调优需求;引入ProgLoss(渐进式损失平衡)、STAL(小目标感知标签分配)与MuSGD优化器,分别提升收敛稳定性、小目标召回率及训练效率;优化算子设计,增强量化兼容性与硬件适配性。
-
支持任务:目标检测、实例分割、姿态估计、定向检测、分类。
-
框架:PyTorch
-
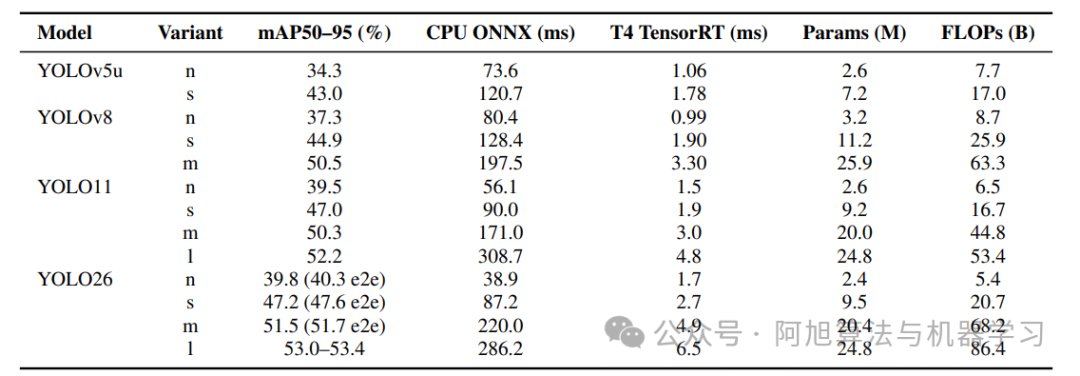
核心性能亮点:MS COCO验证集(640px输入,CPU/ONNX推理)下,nano变体(YOLO26n)mAP约39.8%(端到端模式约40.3%),延迟约38.9ms,较YOLO11n速度显著提升;small变体(YOLO26s)mAP约47.2%,延迟约87.2ms;medium变体(YOLO26m)mAP约51.5%,延迟约220.0ms;large变体(YOLO26l)mAP约53.0-53.4%,延迟约286.2ms,CPU推理速度较前代最高提升43%。
非Ultralytics YOLO模型对比
| 模型(发布年) | 关键创新 | 任务 | 框架 | 核心局限 |
|---|---|---|---|---|
| YOLOv1(2015) | 首个单阶段检测器,单前向传播预测框与类别 | 目标检测、分类 | Darknet | 精度低,小目标检测差 |
| YOLOv4(2020) | CSPDarknet-53骨干,Mish激活,马赛克增强 | 目标检测、跟踪 | Darknet | 依赖GPU,边缘部署差 |
| YOLOv6(2022) | EfficientRep骨干,工业级部署优化 | 目标检测、实例分割 | PyTorch | 未摆脱NMS, latency较高 |
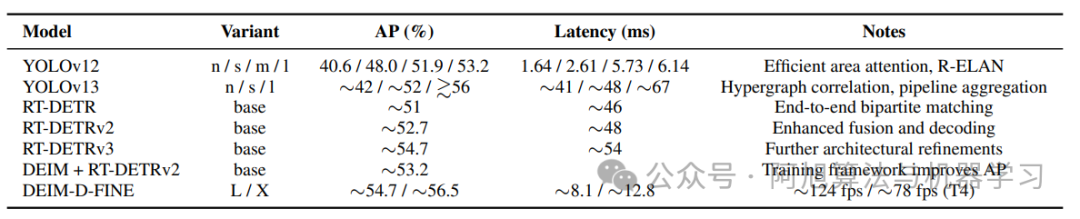
| YOLOv12(2025) | 高效区域注意力,R-ELAN块 | 目标检测 | PyTorch | 保留DFL,低功耗设备兼容性差 |
| YOLOv13(2025) | HyperACE(超图关联增强),全管道聚合 | 目标检测 | PyTorch | 计算复杂度高,CPU推理慢 |
性能对比分析
(评估结果基于MS COCO数据集)
-
核心评估指标:
-
mAP(mean Average Precision):跨IoU阈值(0.50-0.95)与类别计算,衡量综合精度;
-
推理速度:CPU(ONNX)、GPU(TensorRT)延迟(毫秒/帧);
-
精度/召回率/F1分数:平衡假阳性与假阴性。
-
-
关键结论:
-
Ultralytics系列呈 “精度提升+效率优化” 趋势:YOLO26在相同精度下,CPU latency比YOLOv5降低50%以上;
-
非Ultralytics模型(如YOLOv13)虽精度高(≈56% mAP),但 latency达~67ms(T4 GPU),边缘部署性弱于YOLO26;
-
小模型变体(nano)适合边缘设备(如机器人、UAV),大模型(large)适合服务器端(如视频监控分析)。
-
部署与应用场景
-
部署技术细节:
-
FP16:GPU上内存减半,吞吐量翻倍,精度损失<2%;
-
INT8:CPU/NPU上提速30%-50%,YOLO26 INT8与FP32精度差距<1%,适配Jetson Orin、骁龙AI加速器。
-
导出格式:支持ONNX(跨框架)、TensorRT(GPU加速)、CoreML(iOS)、TFLite(Android/微控制器)等,YOLO26因移除DFL/NMS,格式转换无自定义算子依赖;
-
量化策略:
-
-
典型应用领域:
-
机器人:YOLO26无NMS推理(<20ms延迟)支持避障、抓取规划;
-
农业:YOLO11/26的小目标检测(STAL)可识别作物病虫害、小果实;
-
监控:YOLOv8/11的姿态估计用于行为分析,YOLO26量化版适配网络录像机(NVR);
-
制造业:YOLOv8/11的定向检测用于PCB缺陷识别,YOLO26端到端推理满足生产线实时性(>30fps)。
-
挑战与未来方向
-
现存挑战:
-
密集场景检测:重叠目标易漏检,NMS/无锚框策略仍需优化;
-
域适应: curated数据集训练的模型在新场景(如低光、不同传感器)泛化差,易出现“灾难性遗忘”。
-
-
未来研究方向:
-
混合CNN-Transformer架构:结合CNN局部特征捕捉与Transformer长距离依赖建模;
-
开放词汇检测:融合CLIP等视觉-语言模型,实现“零样本/少样本”新类别检测;
-
边缘感知训练:硬件在环(HIL)优化,动态调整模型精度/速度以适配边缘设备资源(如电池、算力)。
-
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 2493
2493

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









