




 YOLOv8是ultralytics在2023年开源的更新,提供SOTA目标检测技术。它引入了C2F和SPPF模块,采用Anchor-Free,动态正样本分配策略TaskAlignedAssigner,并使用Distribution Focal Loss。文章详细探讨了这些创新点及其在网络结构、损失函数和正样本匹配策略上的应用。
YOLOv8是ultralytics在2023年开源的更新,提供SOTA目标检测技术。它引入了C2F和SPPF模块,采用Anchor-Free,动态正样本分配策略TaskAlignedAssigner,并使用Distribution Focal Loss。文章详细探讨了这些创新点及其在网络结构、损失函数和正样本匹配策略上的应用。
文章目录
1.前言
YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本。是一款强大、灵活的目标检测和图像分割工具,它提供了最新的 SOTA 技术。
Github: yolov8
2.创新点及工作
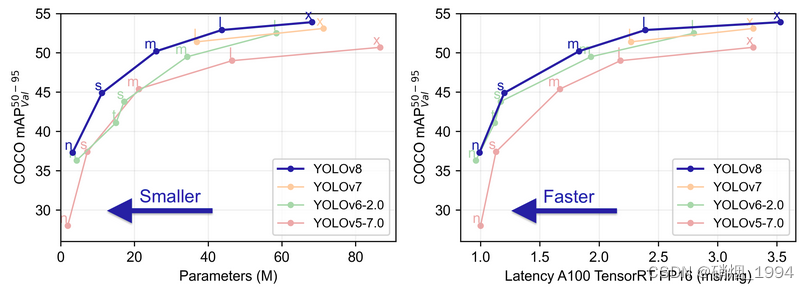
- 提供了一个全新的SOTA模型。基于缩放系数也提供了N/S/M/L/X不同尺度的模型,以满足不同部署平台和应用场景的需求;
- 网络结构上引入C2F和SPPF模块,并对不同尺度的模型进行了精心微调,提升网络特征提取能力及模型性能的同时,平衡模型的推理速度;
- 采用Anchor-Free代替Anchor-Based,对网络输出头进行解耦,分离类别预测和目标框的回归,同时去掉置信度分支;
- 采用TaskAlignedAssigner 动态正样本分配策略,提高样本的生成质量
- 引入了 Distribution Focal Loss用于目标框的回归。
3. 网络结构
3.1 BackBone
3.1.1 C2F
网络结构优化的一种方法:替换基本组件;
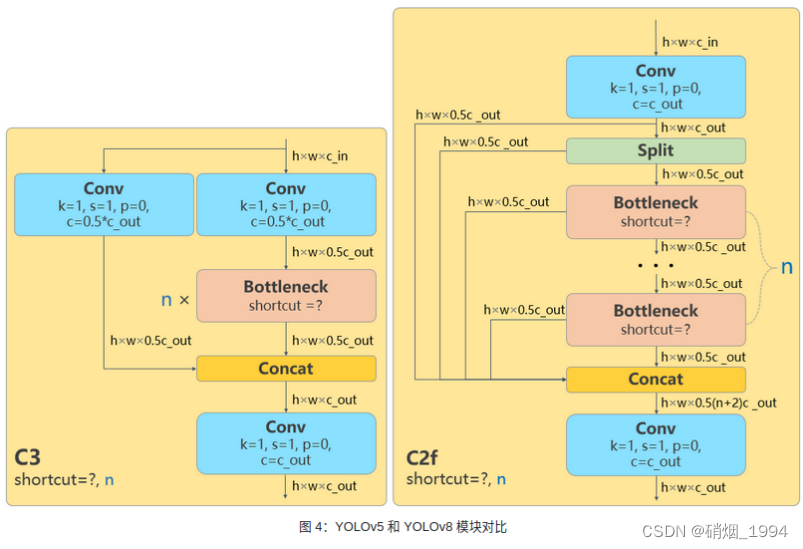
- 参考了YOLOv5的C3模块以及YOLOv7的ELAN的模块进行的设计,让YOLOv8可以在保证轻量化的同时,通过引入更多的分支跨层连接可以获得更加丰富的梯度流信息。
- 相较于YOLOv7的ELAN模块的设计,C2F模块在输入/输出通道上没有做什么额外工作,在一定程度并不太符合ShuffleNet的一些设计准则:要想使卷积推理速度达到最快,输入通道应与输出通道保持一致。
- C2F模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
3.1.2 结构微调
对不同尺度模型调整了通道数和模型的深度,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,综合考虑模型的精度和推理速度

- Yolov5中C3模块的堆叠遵循着3/6/9/3的配置,而在YOLOv8中,C2F的配置则是3/6/6/3的配置,其中的9被减小到了6,以压缩模型的规模
- 对于较轻量的YOLOv8-N和YOLOv8-S,基本通道数遵循128->256->512->1024的变化规律,即乘以各自的width参数即可。 但是,对于较大的M/L/X,最后的1024则分别变成了768,512和512,如上图红框所示,C5尺度的通道数是有变化的。相当于加入一个参数ratio,简记r,基础通道数为512,那么从YOLOv8-N到YOLOv8-X,就一共有width(w)、depth(d)和ratio® 三组可调控的参数:
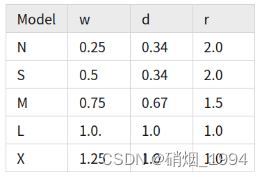
- 这种人为调控参数的目的在于提升模型精度的同时,控制计算量的大小,以实现和其它算法相比,达到SOTA效果;但这种强行调整的方式,人为雕琢的痕迹过重,网络结构的调整没有那么”优雅”。
3.1.2 SPPF
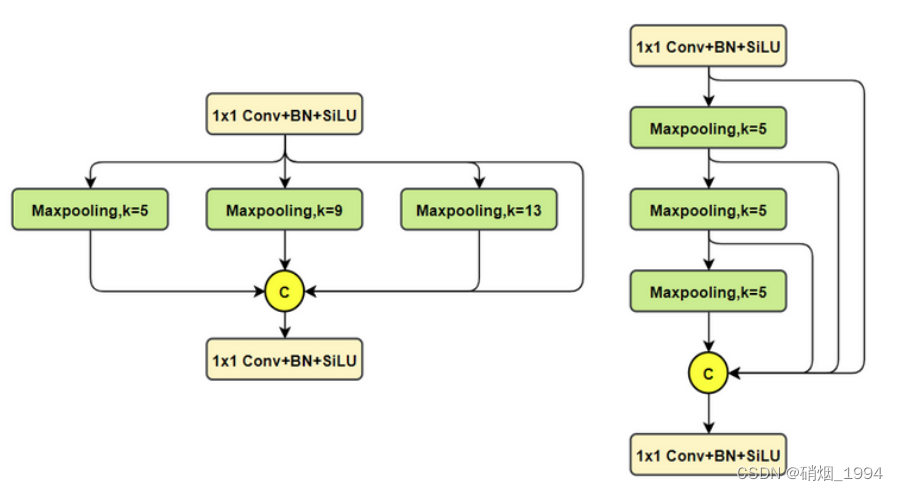
对比spp,将简单的并行max pooling 改为串行+并行的方式。对比如下(左边是SPP,右边是SPPF)
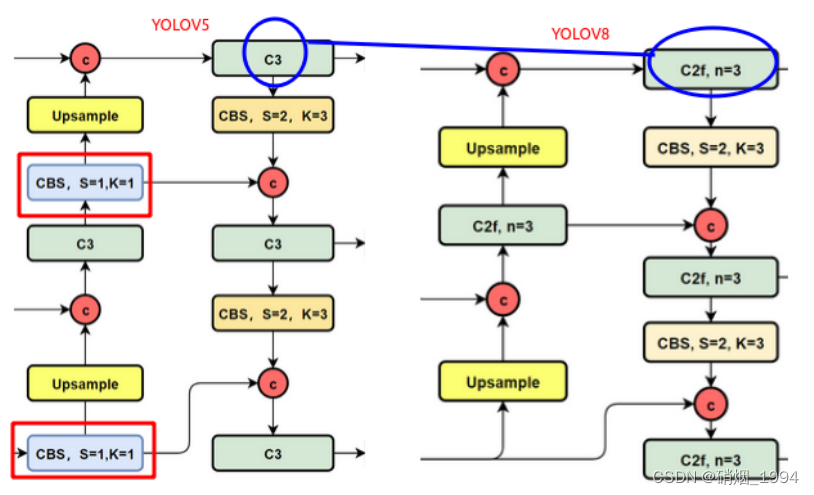
3.2 Neck
NECK部分和yolov5结构基本一致,区别主要有两点
- C3模块更换为C2F模块
- 去掉了上采样前用于降维的 1×1 卷积。
3.3 Head
- Anchor_base 调整为 Anchor_free
- 个人认为anchor box在一定程度上能够起到先验的作用,但其尺寸一般基于数据集统计分析得到,在一定程度上依赖于数据集本身的分布;
- 同时anchor的引入会带来额外的参数量,整体来说anchor_free还是较为简单明了;
- 参考yolox操作,对预测结果进行解耦 :单独分支预测分类和定位
- 去掉了置信度分支
- 回归的内容是ltrb四个值(距离匹配到的anchor点的距离值),这里的regmax在后面进行解释
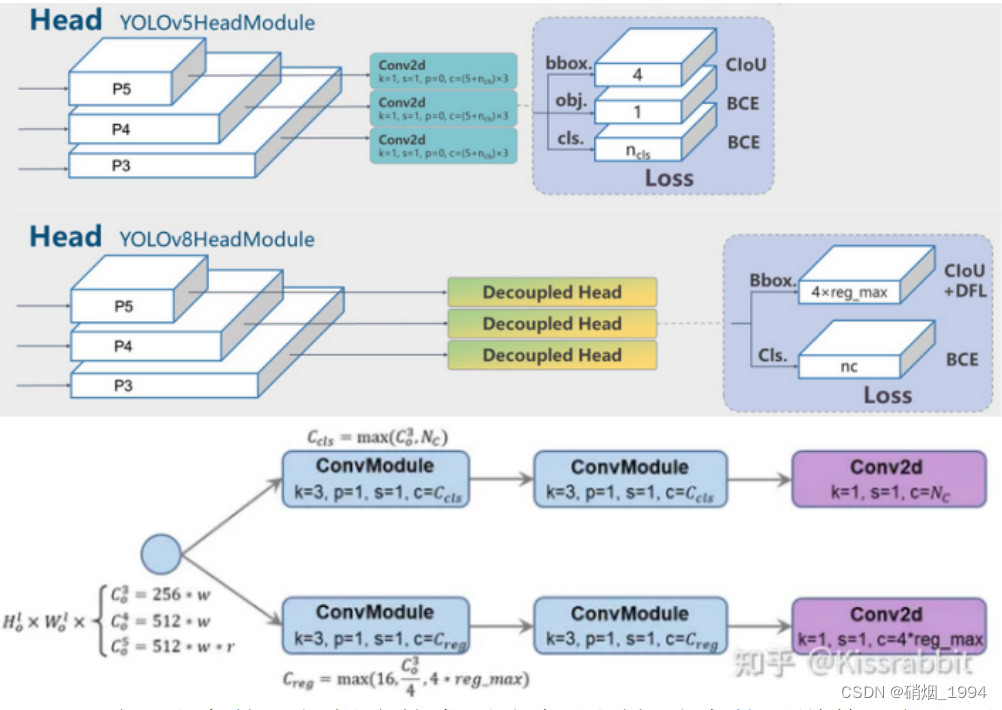
- 需要注意的是解耦头的类别分支和回归分支的通道数可能是不相等的,YOLOv8认为二者表征了两种不同的特征,应该不一样。因此,对于类别分支,YOLOv8将其通道数设置为 c c l s = m a x ( c 0 3 , N C ) c_{cls} = max(c_0^3,N_C) ccls
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3586
3586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









