






本文来源公众号“刘聪NLP”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/ksokCduU_xfnl6dR7P67_g
大家好,我是刘聪NLP。
前天,分享了DeepSeek-OCR的相关细节,确实有被DS的高立意所折服,
我还在苦苦利用OCR解析文档做落地的时候,DeepSeek在考虑用图像压缩文本信息!
昨天一天的发酵,也是各种文本已死,视觉当立,我也是醉了,
我这人呢,挺没意思的,所以抛出几个观点大家一起讨论,
第一个,
文本Token数量压缩到视觉Token数量的10倍以内时,解码精度可达97%,
但是这里会有一个问题,解码的精度是字符的准确率,但是不代表文本信息重要性,
我举个例子,就是100个字里,你错了3个字,如果要是关键人名,或者数值等内容识别错了,
就会很影响后面内容的使用或者传递~
纯文字不形象的话,想想表格就更清晰了,如果表格单元格位置错乱,会十分影响后面使用,
所以压缩率,对应的应该是信息精度,
但我也不知道如何去评价信息精度,只不过觉得单纯看解码精度,太过草率,
第二个,
长上下文坍塌现象,我们都知道,LLM处理长文会出现越往后面,LLM的精度会出现一定的下降,
但是我在思考,假如正常LLM的坍塌在128K之后,
那么经过压缩的视觉Token,在处理的时候,会不会在12K的时候出现坍塌,
模型到底能不能处理的了高密度信息Token,现在还在用MLP对齐,
起码,目前VLM在处理视频的时候,每帧Token数和帧数都会影响模型最终效果
第三个,
文本Token压缩成视觉Token时,高压缩率丢失的内容,真的比Summary丢失的要少吗?
直观感觉会少一些,但是20倍压缩60%的OCR准确率,
是丢失信息、还是错误信息,是否依然保证原始信息的流畅,
我的直觉,summary起码信息是流畅的,但是图像的信息压缩,也许是断续的。
上面只是一些思考,没有否定DeepSeek-OCR的信息压缩论,
因为我第一眼也是觉得醍醐灌顶,欢迎大家评论区讨论,有相关paper欢迎丢出来。
顺着信息压缩这个思路往下走,那么就是提高极度压缩下的精度,
上篇我也是立个Flag,说DeepSeek-OCR与PaddleOCR-VL对比一些,
这次真马来了~

PS:趋势榜前三名都是OCR模型,前五都能做OCR的事情,所以OCR是真好起来了,哈哈哈哈~
下面从纯机文OCR识别、手写体识别、形近字、数学公式、表格解析、竖版内容等多个角度来进行对比。
懒人不爱看版:
-
单论OCR能力,我只能说PaddleOCR-VL全面领先
-
针对机打纯文DeepSeekOCR跟PaddleOCR-VL差不多
-
表格解析、竖版内容上,DeepSeekOCR存在一些不足
-
测试了不少图片,下面例子是部分
-
DeepSeek党,求别喷,只是对比测试
测试链接:
https://huggingface.co/spaces/PaddlePaddle/PaddleOCR-VL_Online_Demo
https://huggingface.co/spaces/axiilay/DeepSeek-OCR-Demo
注意:DeepSeek-OCR选择的精度均为Large
机打纯文
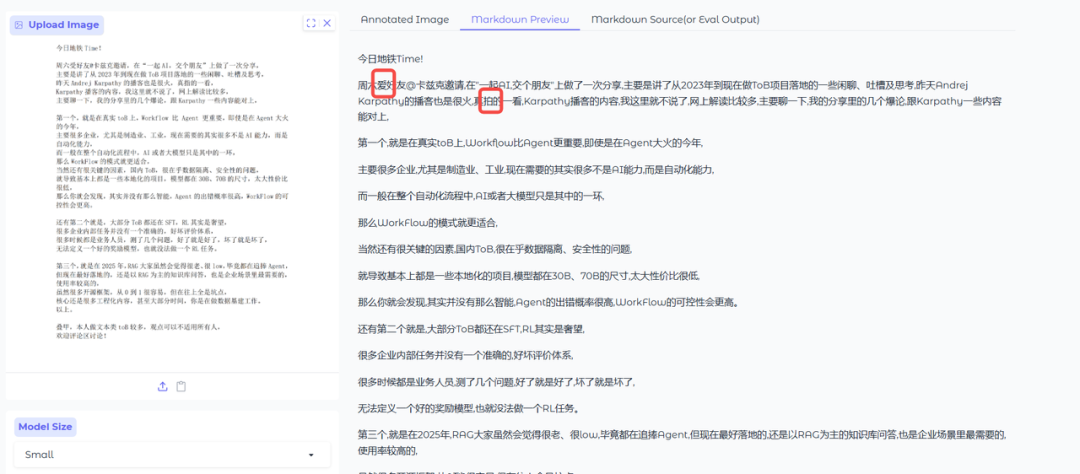
纯看模型的OCR能力,是否能将内容还原,最朴素的需求,直接解析我昨天发的文章。

PaddleOCR-VL效果:不看格式,内容完全正确,一字不差。
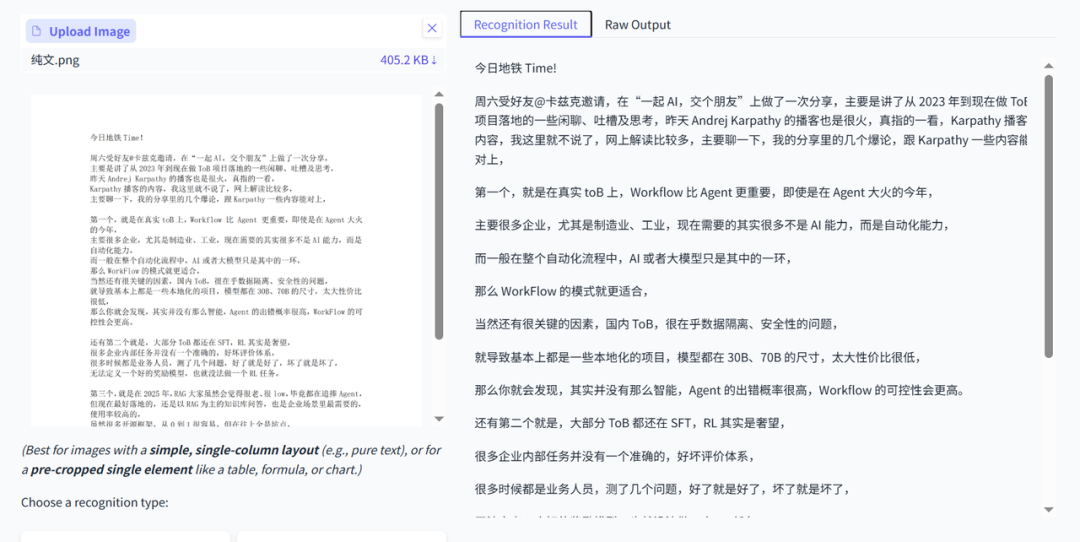
DeepSeekOCR效果:不看格式,内容完全正确,一字不差。

这种机打的纯文本,对于现在大多数VLM模型还是没啥难度的。
但调整small确实会出现错误,所以如果是高压缩,还要看信息丢失程度
手写文本
考察模型对手写内容的识别准确率,能否直接处理压缩手写内容

PaddleOCR-VL效果:正确
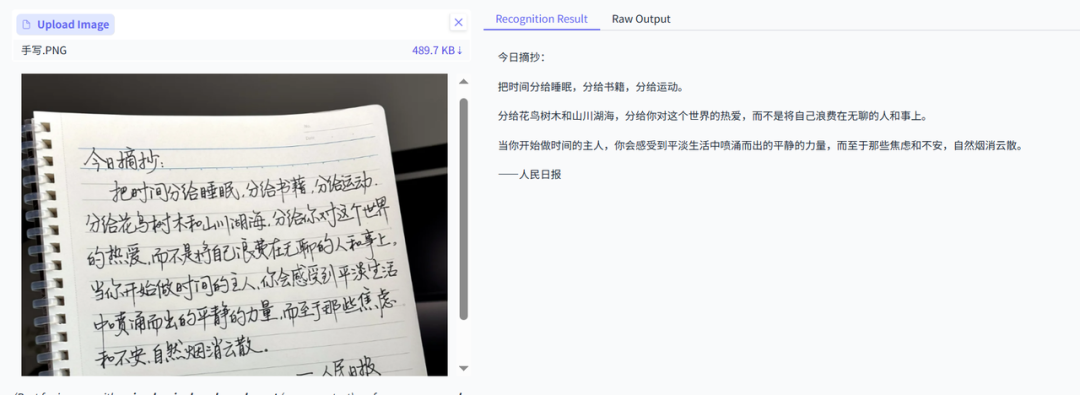
DeepSeekOCR效果:错了一个字
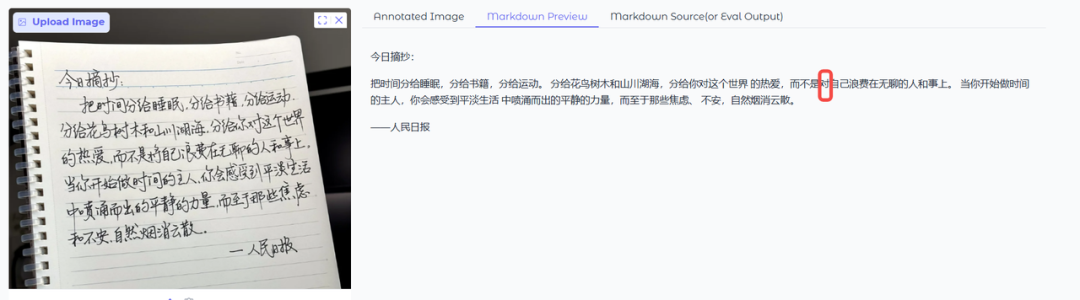
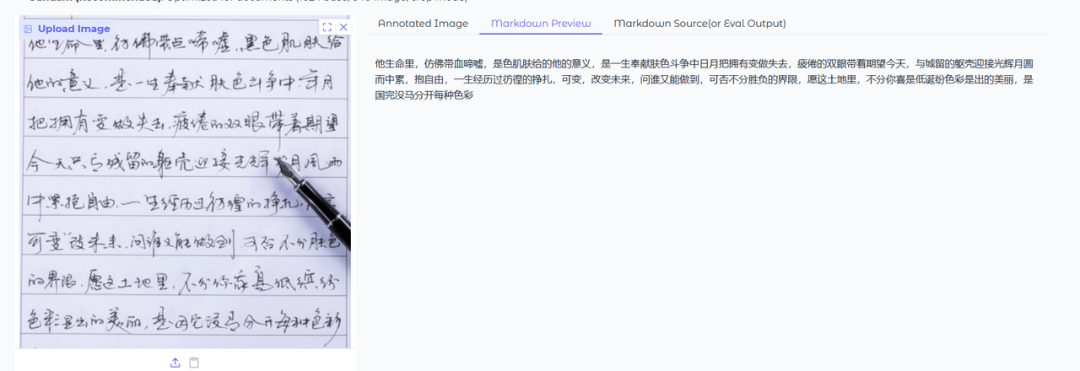
增亿点难度,说实话,下面这个例子我都有的不认识,哈哈哈

PaddleOCR-VL效果:存在识别错误,但整体字符准确率要比DeepSeek-OCR高。
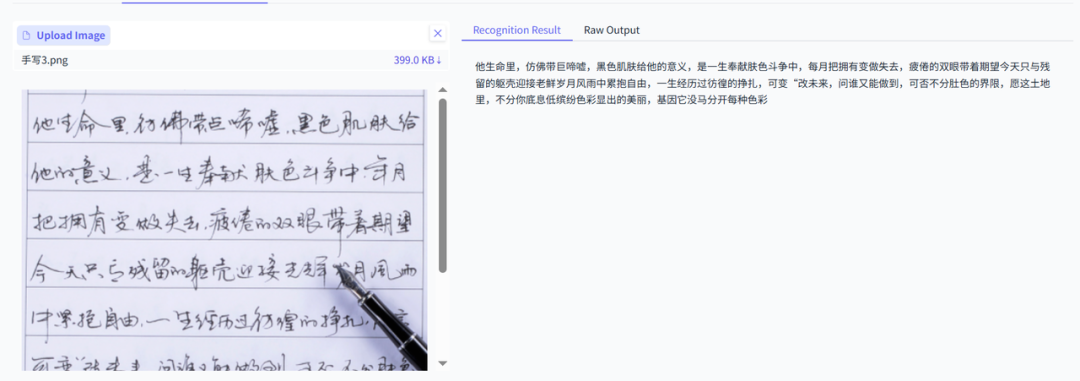
DeepSeekOCR效果:
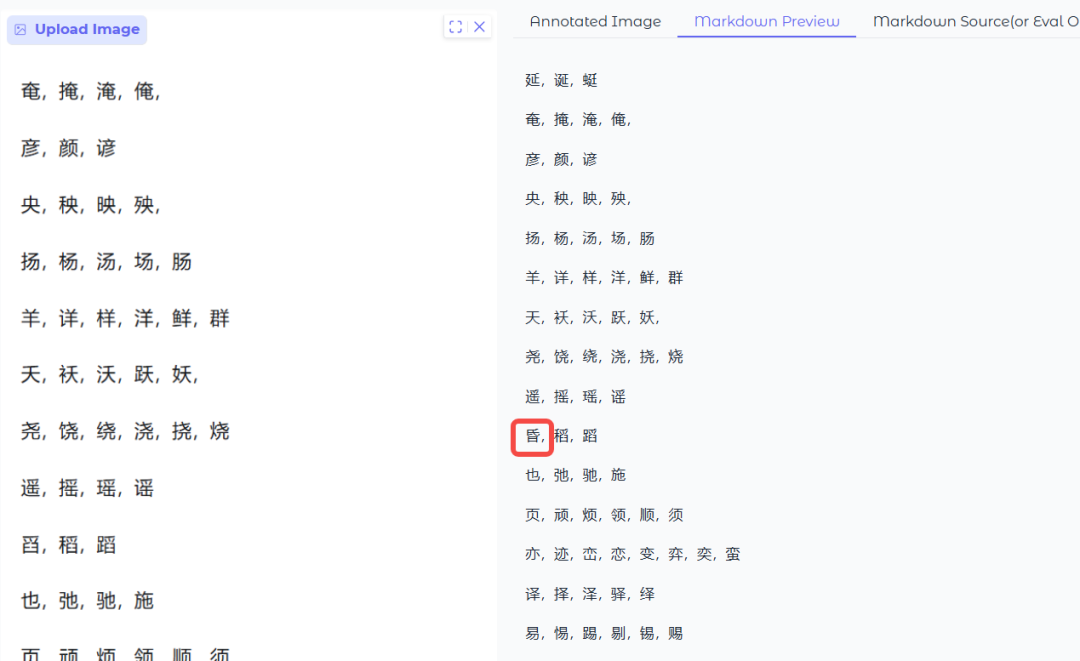
形近字
考察模型是否可以准确识别形近字

PaddleOCR-VL效果:全部正确
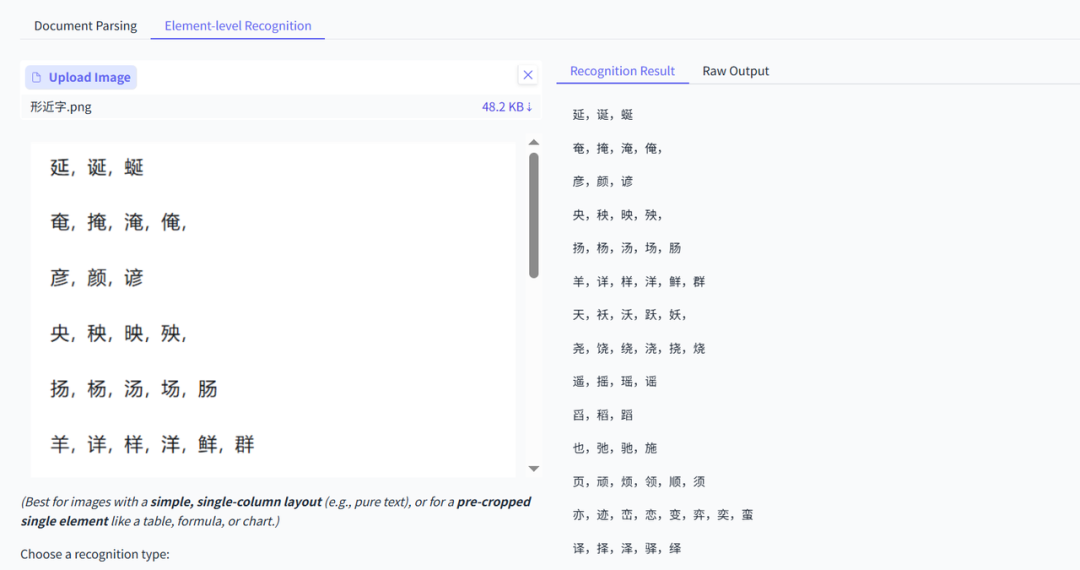
DeepSeekOCR效果:错了一个字,有点奇怪,昏和舀感觉差好多,不知道为啥错了
数学公式
考察模型对数学公式解析的能力,是否可以将公式还原,
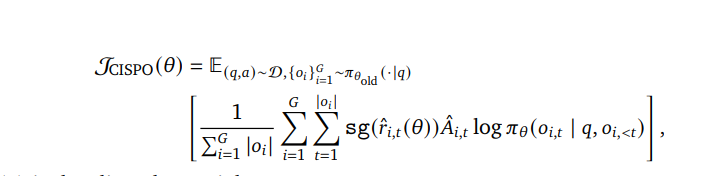
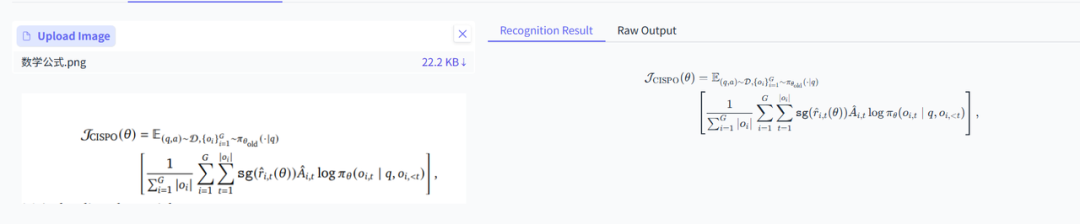
PaddleOCR-VL效果:解析正确
DeepSeekOCR效果:错了一点

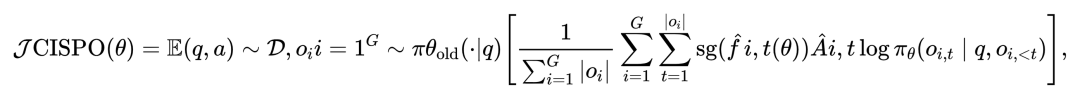
表格识别
考察模型的表格解析能力,能否将文本内容和表格结构均识别正确。
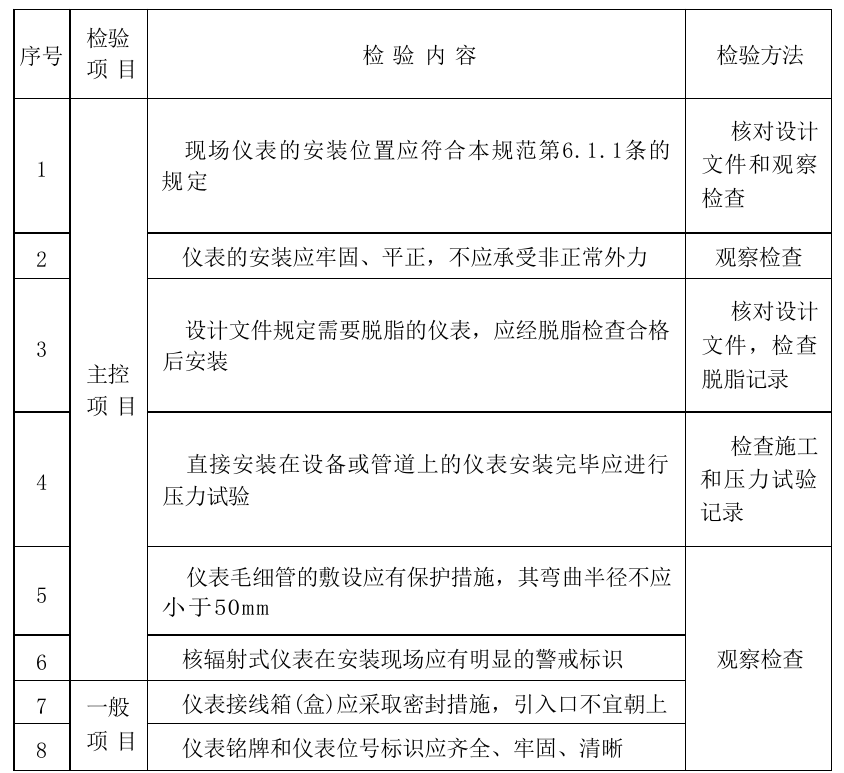
PaddleOCR-VL效果:识别正确

DeepSeekOCR效果:结构存在错误,就是如果表格内容,结构不对,对后面信息理解是巨大的伤害!
再来一个,
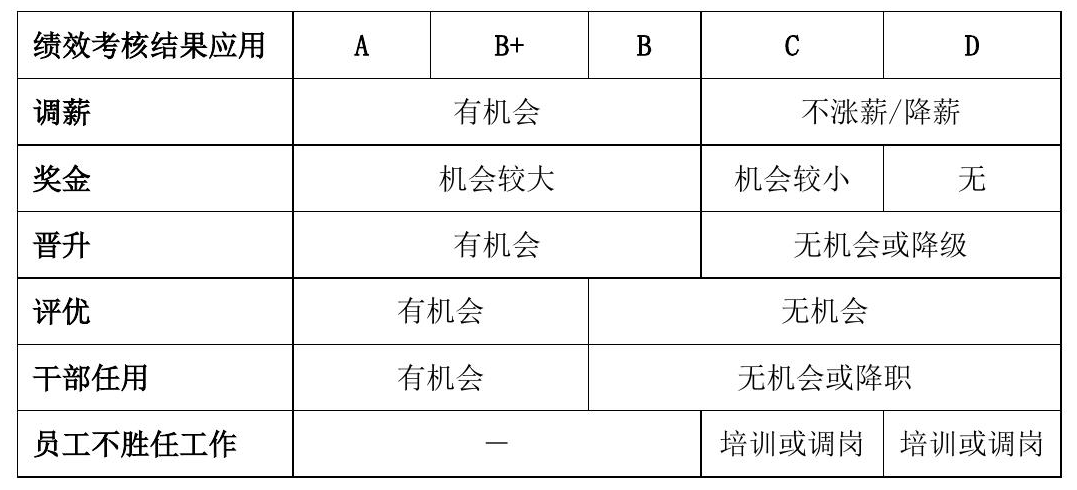
PaddleOCR-VL效果:识别正确,

DeepSeekOCR效果:结构存在问题
竖版内容识别
考察模型对竖版内容理解的能力,是否知道图像为竖版内容,排序是否准确。

PaddleOCR-VL效果:正确,不仅内容识别全对,顺序也没有问题。

DeepSeekOCR效果:内容识别多出一句话,同时竖版内容理解也不对。

最后,在简单过一下PaddleOCR的细节,由PP-DocLayoutV2和PaddleOCR-VL-0.9B两部分组成,
PP-DocLayoutV2是用于识别文档的结构信息,过滤图片中无效视觉部分,如空白,这本身也算是一种“压缩”吧。
PaddleOCR-VL-0.9B接受batch块图像进行识别,最终输出结构化输出。
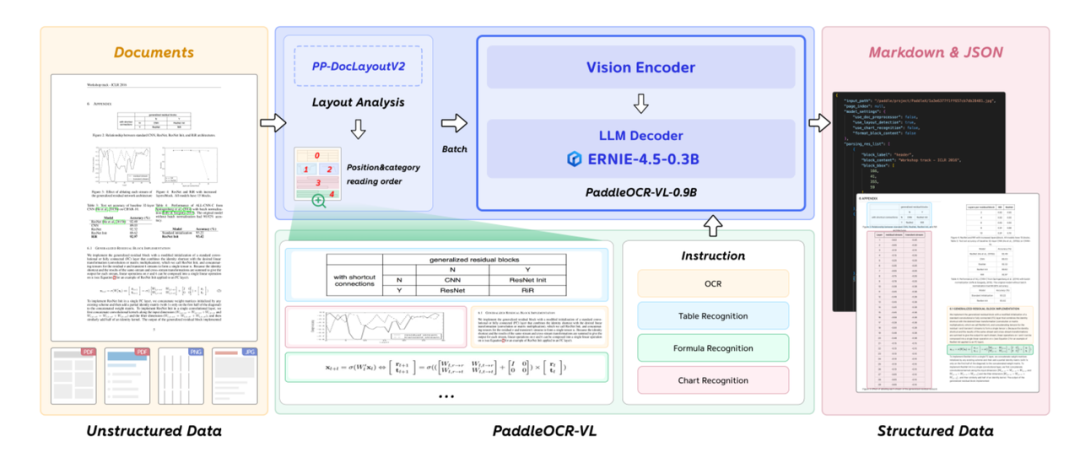
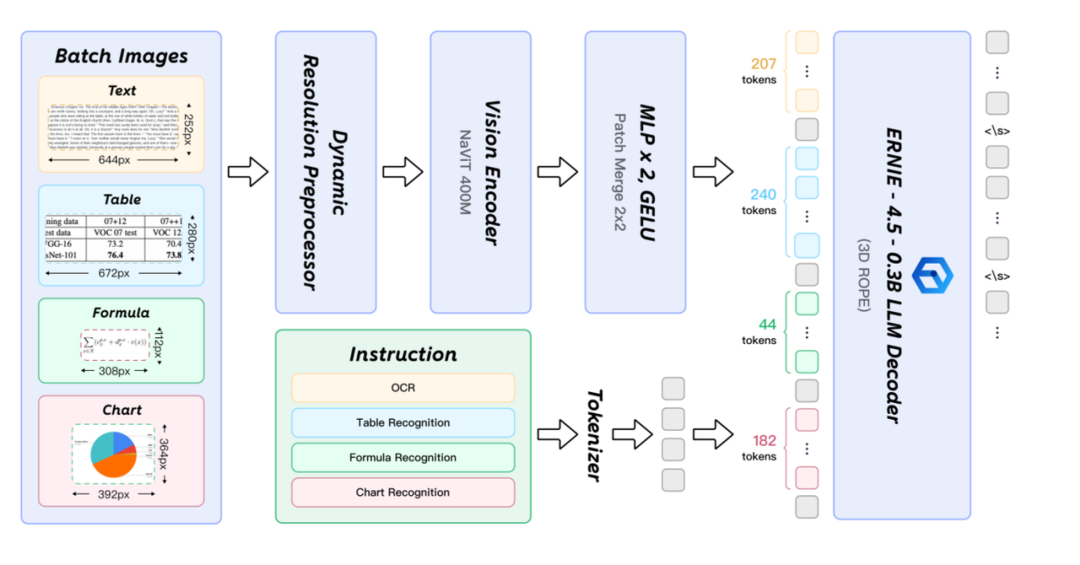
其中,PaddleOCR-VL-0.9B依旧是经典三结构,图像编码器采用NaViT,MLP映射器,文本解码器采用ERNIE4.5-0.3B模型,如下。
最后想说,
图像二维压缩是个很好的方向,但也确实存在一些问题,
在OCR这一块,PaddleOCR确实是鼻祖级别,真别质疑百度的技术,哈哈哈
VLM没出来之前,PaddleOCR是必备,不过之前都是小模型,
现在更新了0.9B版本,我已经准备换PDF解析工具了,
国产开源大模型,依旧遥遥领先~
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1468
1468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









