






本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/TOtPXnKYnvzmiGahu-FOiQ

精简阅读版本
本文主要解决了什么问题
-
1. 视觉语言模型(VLMs)中存在的模态差异问题,即文本token数量有限而视觉token数量过多且冗余,导致现有的为大语言模型(LLMs)设计的后训练量化(PTQ)方法无法直接应用于VLMs。
-
2. 现有的基于Hessian的LLMs PTQ方法在量化过程中对所有token一视同仁,没有考虑不同token的重要性差异,导致在应用于VLMs时性能严重下降。
-
3. 在超低比特量化设置下(如INT2),现有PTQ方法会导致更严重的性能下降,限制了大型VLMs在资源受限环境中的部署。
本文的核心创新是什么
-
1. 提出了一种针对VLMs的新型重要性感知PTQ框架VLMQ,该框架优化了一个重要性感知目标,生成带有token级重要性因子的增强Hessian矩阵,解决了视觉token冗余问题。
-
2. 建立了块级损失扰动与token级量化误差之间的理论联系,提出了通过单次轻量级块状反向传播计算重要性因子的方法,确保了计算效率和效果。
-
3. VLMQ与现有的基于Hessian的PTQ框架完全兼容,能够继承Cholesky分解等高效技巧,同时支持高并行度。
结果相较于以前的方法有哪些提升
-
1. 在8个基准测试上对0.5B至32B的VLMs进行的广泛评估表明,VLMQ在低比特设置下达到了最先进(SOTA)的性能。例如,在2比特量化下,它在MME-RealWorld上实现了16.45%的显著提升。
-
2. 在INT3量化下,与基线方法相比,VLMQ表现出整体优越性,并实现了高达1.01%的平均精度提升。对于Qwen2.5-VL-7B-Instruct-INT3模型,VLMQ在大多数基准上优于通过GPTQ和GPTAQ量化的对应模型。
-
3. 在INT2g128超低比特量化设置下,VLMQ相比GPTQ有显著提升。例如,Qwen2.5-VL-7BInstruct-INT2g128在MME-RealWorld(中文)基准测试上准确率提升了16.45%。
局限性总结
论文的评估主要集中于图像-文本任务,尚未探索VLMQ在视频理解和纯语言任务中的应用,这些方向留待未来进一步探索。
深入阅读版本
导读
预训练后量化(PTQ)已成为一种有效的压缩大型模型并加速其推理的方法,而无需重新训练。尽管PTQ在大语言模型(LLMs)的背景下已被广泛研究,但其对视觉语言模型(VLMs)的适用性仍未被充分探索。在本文中,作者识别出VLMs存在模态差异(即文本token数量有限而视觉token数量过多且冗余)。然而,现有的基于Hessian的LLMs PTQ方法在量化过程中对所有token一视同仁,导致在应用于VLMs时性能严重下降。基于这一观察,作者提出了一种针对VLMs的新型重要性感知PTQ框架,称为VLMQ。具体而言,为解决视觉token冗余问题,VLMQ 1)优化了一个重要性感知目标,该目标生成带有token级重要性因子的增强Hessian,同时保持与并行化权重更新的兼容性;2)通过单次轻量级块状反向传播计算这些因子,并借助与token级扰动的理论联系确保效率和效果。在8个基准测试上对0.5B至32B的VLMs进行的广泛评估表明,作者的VLMQ在低比特设置下达到了最先进(SOTA)的性能。例如,在2比特量化下,它在MME-RealWorld上实现了16.45%的显著提升。
1 引言
大语言模型(LLMs)(Bubeck等人2023;Touvron等人2023a,b;DeepSeek-AI 2025;Jiang等人2023)在多种自然语言处理任务中展现了卓越的进步,推动了视觉语言模型(VLMs)(Wang等人2024b;Bai等人2025;Li等人2024b;Chen等人2024d)的发展,这些模型能够处理包括文本、图像和视频在内的多模态输入。尽管它们具备令人印象深刻的能力,但模型规模的空前扩展使得它们在实际资源受限环境中的部署变得复杂。量化方法通过将全精度权重和激活(例如FP16/BF16)转换为低精度格式(例如INT8/INT4),提供了一种有效的解决方案,从而显著降低了内存占用和计算复杂度,代价是轻微的性能下降。
PTQ(PTQ)已成为部署大规模模型的一种普遍方法,这得益于其极低的计算开销以及能够绕过昂贵的微调或重新训练过程。大量研究工作致力于设计针对大语言模型(LLMs)的先进PTQ方法。此类方法通常旨在通过多种策略来优化权重和激活值的分布,包括等价变换(Lin等人,2023;Xiao等人,2023)、基于Hessian的误差补偿(Frantar和Alistarh,2022;Li等人,2025b)以及非一致性处理(Ashkboos等人,2024;Hu等人,2025)。尽管在将PTQ应用于LLMs方面取得了显著进展,但其扩展到视觉语言模型(VLMs)的研究尚不充分。近期开创性研究工作,如MBQ(Li等人,2025a)、MQuant(Yu等人,2025)和QSLAW(Xie等人,2024),强调了模态不平衡问题,并提出了专门的重要性感知策略来提升量化VLMs的性能。然而,这些方法要么需要昂贵的参数微调(Xie等人,2024),要么需要在推理时进行特殊操作(Yu等人,2025),要么依赖于次优的网格搜索(Li等人,2025a),未能为校准和推理提供高效且有效的解决方案。
在本工作中,作者识别出视觉语言模型(VLMs)中存在一种模态比例失衡问题,即文本token数量有限而视觉token数量过多且冗余(Chen等人2024c;Xing等人2024;Alvar等人2025)。作者将这种冗余现象称为视觉过度表征。现有的基于Hessian的量化感知训练(PTQ)方法,如GPTQ(Frantar等人2022),通过平等对待所有token来优化逐层重建损失。在这些方法中,作为权重量化关键指导的Hessian矩阵通过统一聚合token贡献来估计,而忽略其信息量或重要性。这种与token无关的公式化表达本质上使Hessian矩阵倾向于主导但冗余的视觉特征,导致权重更新次优。因此,直接将这些方法应用于VLMs会导致严重性能下降。
为缓解视觉信息过度表示的副作用,作者提出了VLMQ,一种重要性感知校准框架,该框架优化了精细化目标。如图1所示,VLMQ通过赋予显著 Token 更高的重要性,赋予冗余 Token 更低的重要性,将标准Hessian修改为增强型变体。它通过增广Hessian捕获 Token 级重要性,同时提供封闭形式的权重更新。VLMQ与现有的基于Hessian的PTQ框架完全兼容,并能轻松继承Cholesky分解等高效技巧。为推导有效的重要性因子,作者首先建立了块级损失扰动与 Token 级量化误差之间的理论联系。基于这一见解,作者提出采用单次轻量级块级反向传播方法,高效地推导出层级梯度驱动的重要性因子。
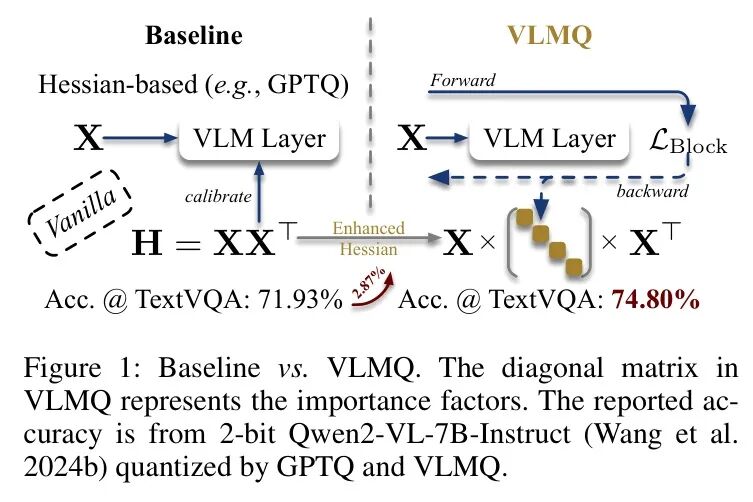
核心贡献总结如下:
-
• 作者识别出视觉冗余在视觉语言模型(VLMs)与现有基于Hessian的量化感知训练(PTQ)方法在目标 Token 无关性上的关键不匹配,后者在量化过程中对所有 Token 一视同仁。作者认为这一被忽视的视觉冗余扭曲了Hessian估计,从而解释了先前针对VLMs的LLM PTQ方法表现不佳的原因。
-
• 作者提出了一种利用基于重要性感知目标导出的增强Hessian的量化训练方案,该方案明确考虑了视觉 Token 之间的冗余性,并支持高并行度。
-
• 作者从理论上将分块损失扰动与一阶token级激活误差联系起来,这为使用单个轻量级分块反向传播来推导梯度驱动的关键因素提供了依据。该设计在捕捉token重要性方面同时实现了高效性和有效性。
-
• 通过大量实验,作者证明了VLMQ在视觉语言模型(VLMs)上的优越性能,尤其是在超低比特量化设置下。例如,VLMQ取得了最先进(SOTA)的结果,并实现了高达 的精度提升。
2 初步

3 相关工作
视觉语言模型(VLMs)的量化感知训练(PTQ)。由于文本和视觉模态之间存在特征和分布的差异,PTQ对于VLMs来说变得具有挑战性,并且该领域仍处于探索阶段。MQuant(Yu等人,2025)提出了模态特定的静态量化和注意力不变的灵活切换,以解决模态差距和视觉异常值问题。MBQ(Li等人,2025a)观察到文本和视觉 Token 之间的误差敏感性存在差异,并构建了相应的偏差目标来确定最优的通道级均衡尺度。QSLAW(Xie等人,2024)通过基于学习方法确定量化步长,并提出重要性感知的预热策略来缓解过拟合问题。与这些专注于模态差异的方法不同,Q-VLM(Wang等人,2024a)捕获了VLMs中的跨层依赖关系,并根据熵值对模块进行划分。

4 动机
视觉过度表征
视觉过度表示问题是在视觉语言模型(VLMs)中广泛认可的问题(Chen等人 Xing等人2024; Alvar等人2025),近期研究探索了通过减少视觉token来加速推理,同时保持性能。然而,现有的基于Hessian的PTQ方法,如GPTQ(Frantar等人2022),未能利用这种冗余。它们通过均匀聚合所有从标准优化目标中推导出的token贡献来构建Hessian。因此,这些与token无关的方法在应用于VLMs时往往难以处理,因为在VLMs中冗余的视觉token主导了激活空间。这一局限性促使作者需要重要性感知的量化策略,这些策略明确区分信息量大的视觉token和冗余的token。
初步研究
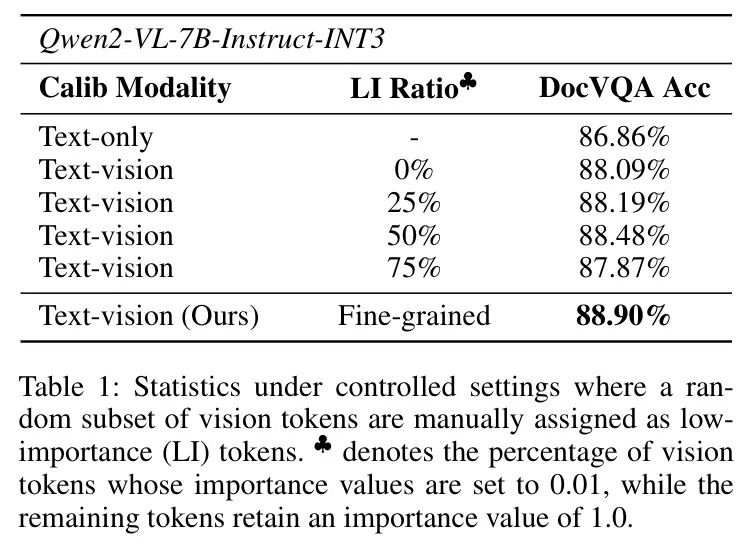
量化中的视觉角色初步研究。为进一步探究视觉 Token 在量化性能中的作用,作者进行了一项初步研究,揭示了视觉 Token 如何影响Hessian估计和模型精度。作者观察到1)对于视觉语言模型VLMs的有效量化,引入视觉 Token 至关重要,然而2)过多的冗余视觉 Token 可能导致性能下降。通过为低重要性 Token 分配冗余 Token ,可以缓解由此产生的性能下降。为验证这一见解,作者在DocVQA(Mathew, Karatzas, and Jawahar 2021)上对INT3量化的LLMs进行基准测试,通过使用低重要性因子随机降低部分视觉 Token 的权重。如表1所示,当50%的视觉 Token 被 Token 为低重要性(LI)时,模型性能达到峰值,这表明视觉输入的平衡水平对于最优量化至关重要。
对初步研究的解释。作者将观察到的性能波动归因于Hessian特征偏移,如图2所示。最左侧的子图显示,仅文本 Token 在主导分量空间中呈现出紧凑且集中的分布。引入视觉 Token ,如图第二个子图所示,使校准分布多样化,并有助于减少量化推理差距。
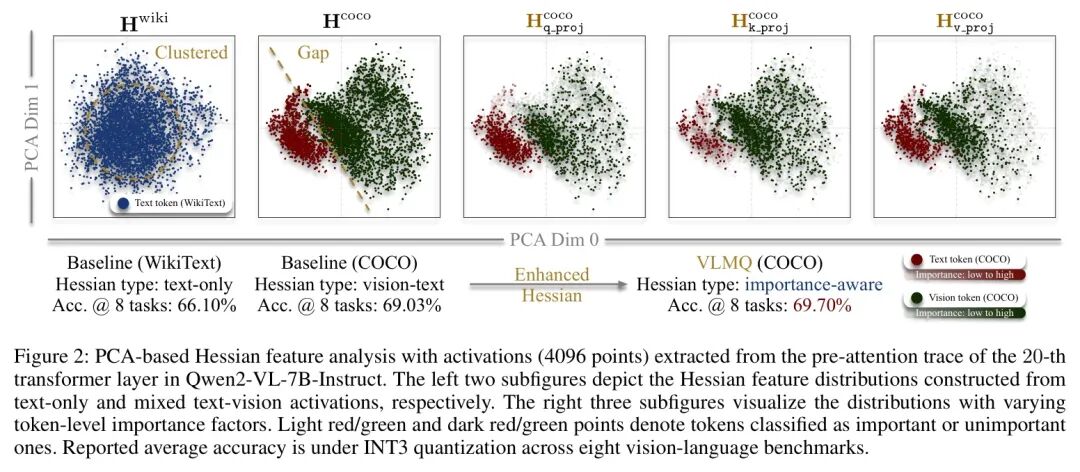
然而,由于视觉特征的过度表示,过多的包含引入了Hessian偏差至冗余视觉特征的风险。
作者进一步根据其重要性因子 (定义见后)对 Token 点进行颜色编码,如右侧三个子图所示。跨模态的重要性密度明显失衡,这导致Hessian矩阵倾向于冗余的视觉边缘,而非集中于更具信息量的中心区域。这些发现凸显了细粒度重要性感知量化对抗冗余诱导偏差的必要性。
总的来说,作者的初步研究表明,加入视觉输入是必要的,而过度输入则会损害量化质量。通过适度降低视觉 Token 的权重所观察到的性能峰值验证了平衡视觉输入的重要性。这些见解促使作者需要一种细粒度、重要性感知的量化策略,该策略能够选择性地强调显著的视觉 Token ,同时减轻冗余 Token 的副作用。
5 VLMQ
为解决不同token间重要性差异的问题,作者提出了一种针对VLMs的精确PTQ方法,通过优化一个称为VLMQ的重要性感知目标函数。具体而言,1)为了捕捉token间的重要性差异,作者将量化目标函数改进为重要性感知形式,从而得到增强的Hessian矩阵。然后,2)作者建立了块状损失扰动与层状输出误差之间的理论联系,通过单次块状反向传播高效计算梯度驱动的重要性分数。
5.1 基于重要性的目标

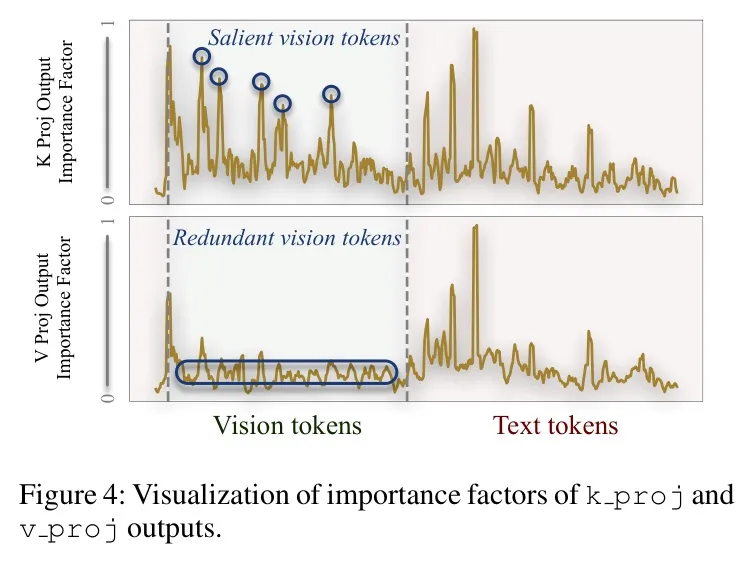
5.2 基于梯度的重要性因子


6 实验实现细节
模型。作者在开源的SOTA视觉语言模型上进行了实验,包括LLaVA-OneVision-O.5B/7B、Qwen2.5-VL-2B/7B/32B-Instruct和Qwen2-VL-7B-Instruct。对于LLaVA-OneVision系列,作者选择了采用Qwen2作为语言模型主干,并使用SigLIP-400M(Zhai等人,2023)作为其视觉编码器的版本。
校准。遵循MBQ(Li等人,2025a),作者选择由ShareGPT4V(Chen等人,2024b)引入的改进版COCO Caption数据集。作者随机采样512个文本-图像对作为校准集。除非另有说明,作者使用默认的阻尼比,并在所有实验中启用act_order。其他细节可参见附录D。
评估。作者基于LMMs-Eval框架(Zhang等人2024a)采用多项具有挑战性的视觉语言任务对量化视觉语言模型(VLMs)进行广泛评估。具体而言,作者采用了代表性任务,包括ChartQA(Masry等人2022)、DocVQA(Mathew、Karatzas和Jawahar 2021)、MME-RealWorld(Zhang等人2024b)、OCRBench(Liu等人2024)、ScienceQA(Lu等人2022)、SeedBench 2 Plus(Li等人2024a)和TextVQA(Singh等人2019),从而全面衡量量化模型的文本识别、视觉感知和视觉推理能力。所有实验均启用Flash Attention(Dao等人2022),并使用默认配置。
6.1 主要结果
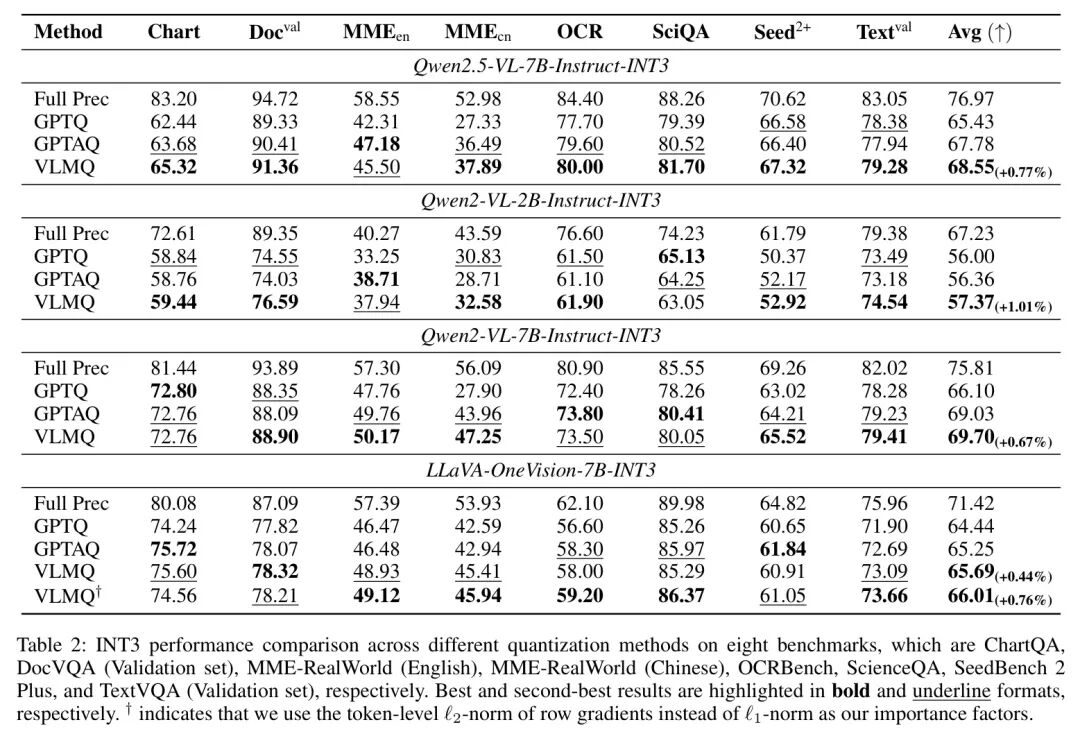
INT3量化。作者在表2中评估了INT3量化模型在八个视觉语言基准上的零样本性能。与 Baseline 方法相比,VLMQ表现出整体优越性,并实现了高达1.01%的平均精度提升。对于Qwen2.5-VL-7B-Instruct-INT3模型,所提出的VLMQ在除MME-RealWorld(英语)以外的所有基准上均优于通过GPTQ和GPTAQ量化的对应模型。值得注意的是,它在ChartQA、MME-RealWorld(中文)和ScienceQA上分别实现了1.64%、1.40%和1.18%的精度提升。对于LLaVA-OneVision-7B-INT3模型,作者采用token Level 的范数,而不是其他实验中采用的范数,因为作者通过经验发现这有利于性能提升。
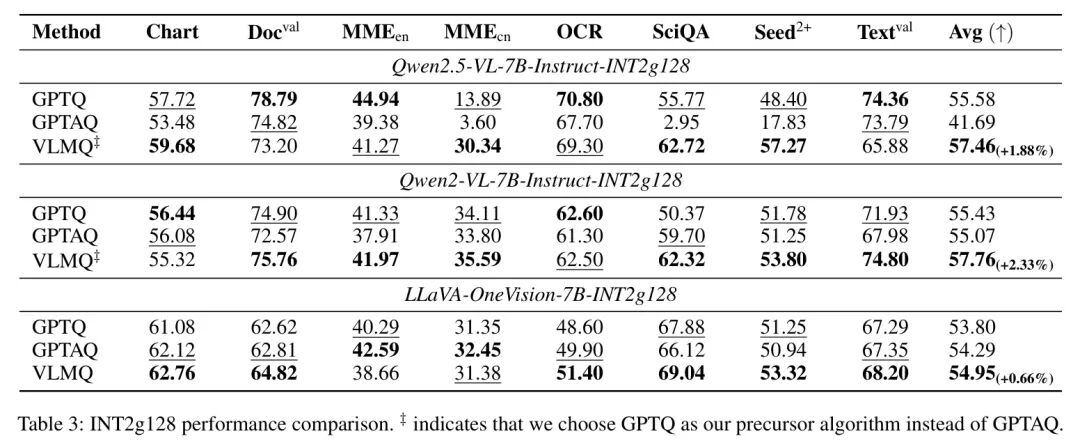
INT2g128量化。作者进一步评估了以组内量化INT2g128(group_si )配置的模型的性能,如表3所示。虽然GPTAQ作为作者的前置算法在INT3量化下通常能获得令人满意的结果,但将其应用于INT2g128会导致严重的性能下降。特别是,在超低比特设置下,GPTAQ的表现甚至不如GPTQ。以Qwen2- VL-7B-Instruct-INT2g128为例,GPTAQ仅达到41.69%的准确率,显著低于GPTQ的55.58%。此外,Qwen2.5-VL-7BInstruct-INT2g128在MME-RealWorld(中文)和ScienceQA基准测试上均表现不佳,准确率分别仅为36.0%和29.5%。一个合理的解释是,在极低比特量化下,GPTAQ中从先前量化层传播的残差误差可能会持续累积并被显著放大。这种累积的噪声严重干扰了主导权重更新项,从而损害了不理想的量化质量。为了缓解这一问题,作者选择GPTQ作为基础算法。显然,作者观察到VLMQ在INT2g128配置下性能显著提升。例如,与GPTQ相比,Qwen2.5-VL-7BInstruct-INT2g128在MME-RealWorld(中文)基准测试上准确率提升了16.45%。
6.2 消融实验
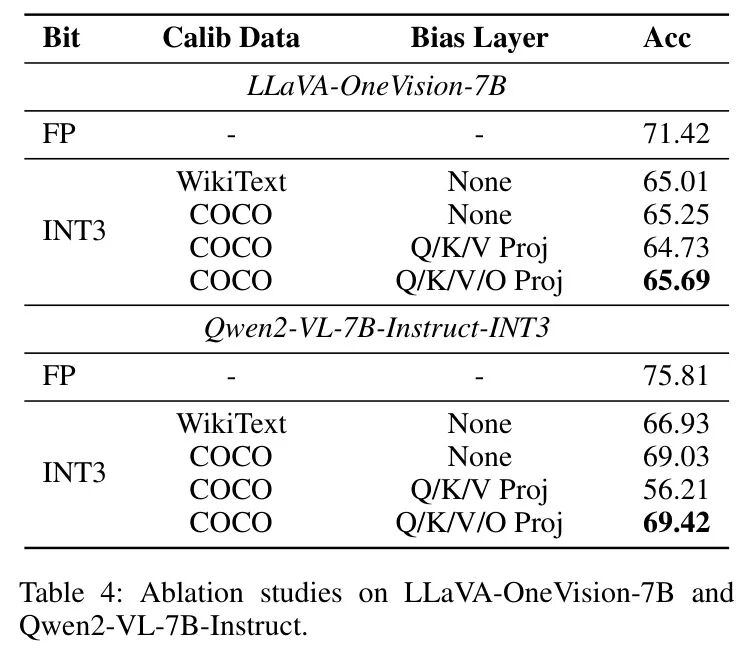
作者对Qwen2-VL-7BInstruction-INT3和LLaVA-OneVision-INT3进行了逐步的消融研究,如表4所示。很明显,仅使用WikiText作为校准数据集会导致性能大幅下降,这突显了在量化时引入视觉模态的必要性。通过结合token Level 的重要性方差,VLMQ通过重要性感知加权来增强Hessian矩阵,从而改进权重更新步骤并提升整体量化质量。值得注意的是,作者发现将作者的有偏校准策略应用于至关重要。作者将其归因于量化q-proj、k proj和时产生的误差累积。利用O-proj中的增强Hessian信息,可以在每个残差块内进行有效的误差补偿,最终提高量化保真度。
6.3 量化效率
7 结论与局限性
作者提出了VLMQ,一种针对视觉语言模型(VLMs)的新型重要性感知量化(PTQ)框架。作者识别出视觉过度表征问题,该问题阻碍了现有大语言模型(LLMs)PTQ方法在VLMs上的直接应用。基于这一见解,VLMQ明确利用了重要性感知目标产生的增强Hessian矩阵。VLMQ有效提升了量化VLMs在多种视觉语言基准测试中的性能,使得大型VLMs在超低比特设置下的部署更加实用。在局限性方面,作者的评估主要集中于图像-文本任务。然而,作者相信VLMQ可以推广到更广泛的应用场景,例如视频理解和纯语言任务,这些方向留待未来进一步探索。
参考
[1]. VLMQ: Efficient Post-Training Quantization for Large Vision-Language Models via Hessian Augmentation
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









