




本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/N09ZOUnv9LBwskB7ZIwqvg

精简阅读版本
本文主要解决了什么问题
-
1. 基于视觉的驾驶员疲劳检测方法在复杂条件下(如部分遮挡、侧面面部姿态和弱光环境)的鲁棒性差问题。
-
2. 小物体(如手机)或被遮挡目标检测效果不佳的问题。
-
3. 多尺度特征建模有限,难以同时捕获局部细节和全局上下文信息的问题。
-
4. 现有方法在计算成本和实时性能之间的平衡问题,特别是在嵌入式系统上的部署瓶颈。
本文的核心创新是什么
-
1. 提出了卷积与注意力融合模块(CAFM),通过局部CNN特征与基于Transformer的全局上下文集成,增强特征表达能力和上下文理解。
-
2. 引入了矩形校准模块(RCM),通过捕获水平和垂直上下文信息,提高空间定位精度,特别适用于侧面面部和手机等小物体检测。
-
3. 基于YOLO11n构建了轻量级高效的YOLO11-CR模型,通过CAFM和RCM的协同作用,实现了在复杂驾驶场景下的高性能实时疲劳检测。
结果相较于以前的方法有哪些提升
-
1. 在DSM数据集上实现了87.17%的精确率、83.86%的召回率、88.09%的mAP@50和55.93%的mAP@50-95,显著优于基线模型(如YOLOv8、YOLOv10n和YOLO11n)。
-
2. 消融研究表明,CAFM模块使召回率提升了3.20%,RCM模块使精确率提升了1.62%,两者结合时在所有指标上均达到最佳性能,体现了模块间的互补性和协同效应。
-
3. 在分类性能上,正常面部类别的mAP@50达到98.6%,侧面面部为89.1%,手机类别为76.3%,特别是在小物体和被遮挡目标检测上表现突出。
-
4. 混淆矩阵和PR曲线分析显示,YOLO11-CR在分类敏感性和特异性上均有提升,尤其在手机检测上正确分类率达到85%,远高于对比模型。
局限性总结
-
1. 手机类别的检测性能(精确率75.8%,召回率65.9%)仍低于正常面部和侧面面部,主要受限于小尺寸和部分遮挡的挑战。
-
2. 模型在低光照和极端遮挡条件下的鲁棒性有待进一步验证,当前实验主要基于DSM数据集,可能未覆盖所有真实驾驶场景。
-
3. 尽管模型轻量化,但在嵌入式设备上的实时性能(FPS)并非最优,计算效率仍有提升空间。
-
4. 研究未涉及时间建模和多模态数据集成(如热成像与可见光融合),这些可能是未来改进的方向。
深入阅读版本
导读

1. 引言
随着车辆使用的全局快速扩张,疲劳驾驶已成为一个关键的公共安全问题[1]。随着驾驶员和车辆数量的逐年增长,疲劳直接导致了约20%的交通事故,通常造成严重伤害或死亡[2]。因此,及时检测和干预对于减轻这些风险至关重要,使实时准确的疲劳检测和警报系统的开发与部署成为增强整体交通安全及减少事故造成的伤害和死亡的基本策略。
当前驾驶员疲劳检测的方法可大致分为三类:基于生理信号的方法[3]、基于车辆动力学的方法[4]和基于视觉的技术[5-7]。基于生理信号的技术,如脑电图[8-10],提供高准确性但需要侵入式测量[11-13],在信号整合方面面临计算复杂性,并且对环境和个体差异敏感[14-18]。基于车辆动力学的方法,通过异常驾驶行为如转向角波动[19-21]推理疲劳,允许非侵入式监测,但在不同驾驶条件和车辆型号上缺乏一致性。
基于视觉的方法因其非侵入性、易于部署和与实时应用的兼容性而越来越受欢迎。这些方法已从传统的手工特征方法发展到先进的深度学习框架。早期方法专注于使用手动设计的特征提取视觉线索,如眼睛状态、打哈欠和 Head 姿势。Deng等人[22]开发了DriCare系统,该系统从视频帧中捕捉眨眼频率和打哈欠以推理疲劳状态,证明了基于视觉的非侵入式监测的可行性。Knapik等人[23]提出了一种基于热成像的打哈欠检测方法,解决了可见光系统在不同光照条件下的局限性。Saurav等人[24]和Lima等人[25]通过结合卷积神经网络(CNNs)和支持向量机(SVMs)探索眼睛状态识别,实现了实时眨眼检测。这些方法虽然有效,但依赖于预定义特征,在部分遮挡或姿势变化等复杂场景中表现不佳。
值得注意的是,近期的研究集中于集成先进的注意力机制以应对这些挑战。例如,Li等人将通道空间注意力模块(CSAM)引入YOLOv4,通过动态加权通道和空间维度增强了小目标的特征表示[34]。类似地,Chen等人提出了多尺度特征注意力网络(MFAN),该网络能够自适应地聚合不同尺度的特征,提高了在不同光照条件下疲劳线索的检测准确性[35]。这些研究表明,注意力机制可以有效缓解传统CNN架构在捕捉细粒度细节方面的局限性。
随着YOLOv8的发布,研究采用了其增强的transformer Backbone 网络来捕获复杂的空间特征。Zhang等人构建了一个混合模型,将YOLOv8与LSTM时序模块相结合,通过整合时空上下文提高了微睡眠检测的敏感性。最近,YOLO11系列因其准确性和效率的平衡而受到关注。Huang等人[36]开发了LWYOLO11,这是一个轻量级变体,在保持侧面人脸和手机检测精度的同时减少了计算负载。Deng等人[37]将多尺度注意力机制整合到YOLOv6中,以提高在不同光照条件下对细微面部疲劳指标的敏感性。这些进展展示了一个向多目标、多尺度检测框架发展的趋势。YOLO模型在平衡高mAP与实时处理方面表现出色,使其适合在车载环境中部署。关键创新包括注意力机制、多尺度特征聚合和 Anchor-Free 点检测Head,这些创新增强了从面部表情到次要任务干扰等多种疲劳线索的识别能力。
然而,基于视觉的方法面临着关键障碍。在复杂条件下的鲁棒性,如被手或太阳镜部分遮挡、侧面面部姿态和弱光环境,仍然具有挑战性;例如,当被太阳镜遮挡时,标准模型难以检测闭眼状态。识别同时发生的行为(如使用手机和打哈欠)需要先进的时空推理能力,而许多模型缺乏这种能力[22]。在有限数据集上训练的模型通常无法适应不同的驾驶环境、摄像头角度或驾驶员人口统计特征[38-40]。尽管出现了轻量级模型,但在低功耗嵌入式系统上的实时性能仍然是广泛采用的 Bottleneck 。未来的研究应专注于增强被遮挡物体的特征表示,整合多模态传感(如热成像和可见光),并开发领域自适应模型。通过大规模实地试验进行时间建模和跨场景验证,对于弥合实验室准确性与现实世界可靠性之间的差距也至关重要。
为解决这些局限性,包括遮挡条件下的鲁棒性差、多尺度特征建模有限以及高计算成本。本文提出了YOLO11-CR,一种轻量级且高性能的检测模型。本文的主要贡献可总结如下:
-
1. 设计卷积与注意力融合模块(CAFM)来替换C2PSA模块中的注意力层,形成增强的C2PSA_CAFM结构。该模块通过局部和全局分支整合CNN和Transformer以提取各自的特征,最终输出通过对这些流求和得到,用于建模局部-全局表示并增强特征表达能力和上下文理解。
-
2. 引入矩形校准模块(RCM)来替代YOLO11n特定特征提取/融合阶段中的传统3×3和1×1卷积。RCM通过捕获水平-垂直全局上下文来增强YOLO11中的空间特征建模,实现更准确的多尺度目标定位/识别,并提高整体网络检测性能。
-
3. 对YOLO11-CR进行微调和测试以用于疲劳检测场景,重点关注三个关键目标类别:正常面部、侧面面部和手机。
本文的其余部分组织如下:第2节详细介绍了提出的YOLO11-CR、CAFM的结构以及RCM的结构。第3节介绍了实验设置,包括数据集概述、训练超参数和评估指标。第4节对YOLO11-CR中的CAFM和RCM模块进行了消融研究,并对性能参数进行了全面分析。最后,本文在第5节进行了总结。
2. 框架
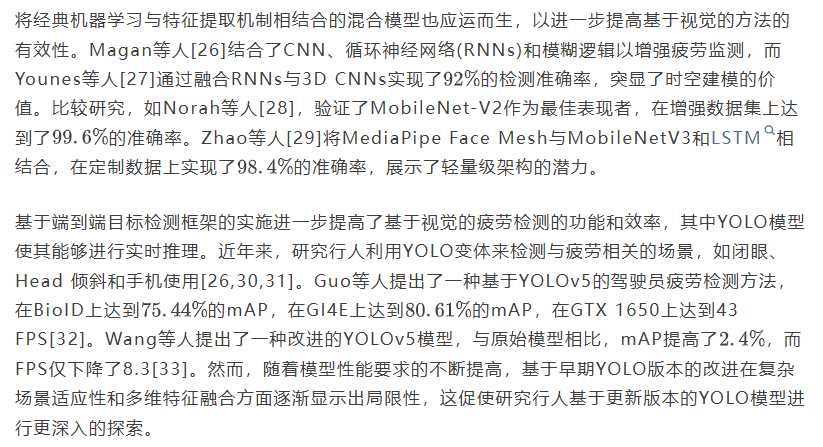
为构建有效的疲劳驾驶检测系统,本文提出了YOLO11-CR,这是一种基于YOLO11的增强型单阶段目标检测框架,旨在解决驾驶员行为分析中的小尺度目标、部分遮挡和非正面面部朝向等挑战。如图1所示,YOLO11-CR集成了两个新颖的结构模块:CAFM和RCM,它们协同增强了多尺度表示学习、空间特征对齐以及复杂场景下的检测精度。采用典型的编码器-解码器设计,该网络包括用于分层特征提取的YOLO11n Backbone 网络、特征融合 Neck 和多尺度检测Head。检测目标被定义为正面面部、侧面面部和手机,它们作为疲劳检测系统中的关键语义线索。 Backbone 网络生成P3–P5 Level 的特征,分别以8、16和32的因子进行上采样,这些特征在传递到检测Head进行边界框回归和类别概率预测之前,会通过注意力增强表示进行增强。
2.1 卷积与注意力融合模块
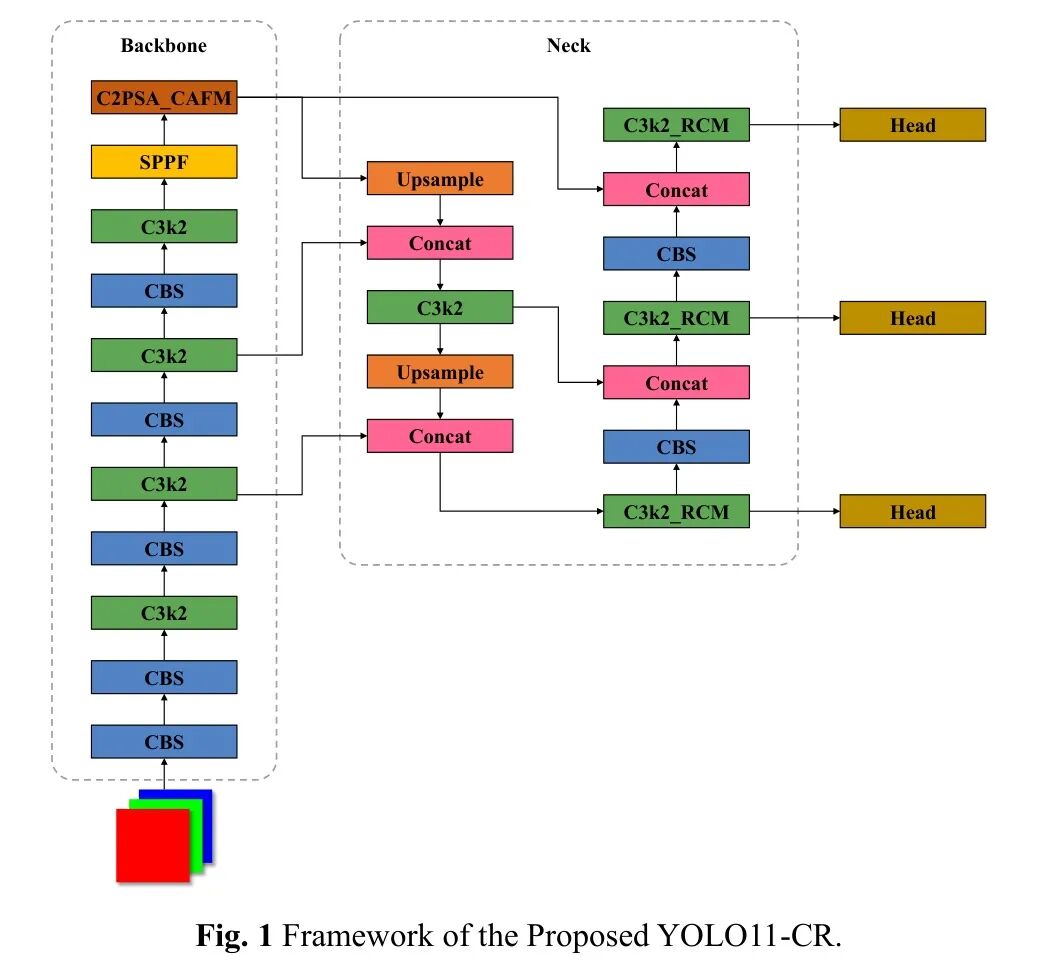
为了解决在轻量高效的方式下同时捕获局部细粒度特征和全局上下文关系的基本挑战。受卷积操作和自注意力机制的互补优势启发,本节引入CAFM [41]来解决复杂检测场景的问题,如小目标检测、遮挡目标识别和疲劳特征提取。
如图2所示,CAFM由两个功能分支组成,局部分支旨在捕获对检测小尺度目标和保持边界精度至关重要的细粒度空间模式,通过卷积操作提取空间细节;全局分支则通过引入轻量级自注意力机制来解决卷积感受野有限的问题,以建模长距离空间依赖关系,这对于理解遮挡或分布特征至关重要。

2.2 矩形校准模块
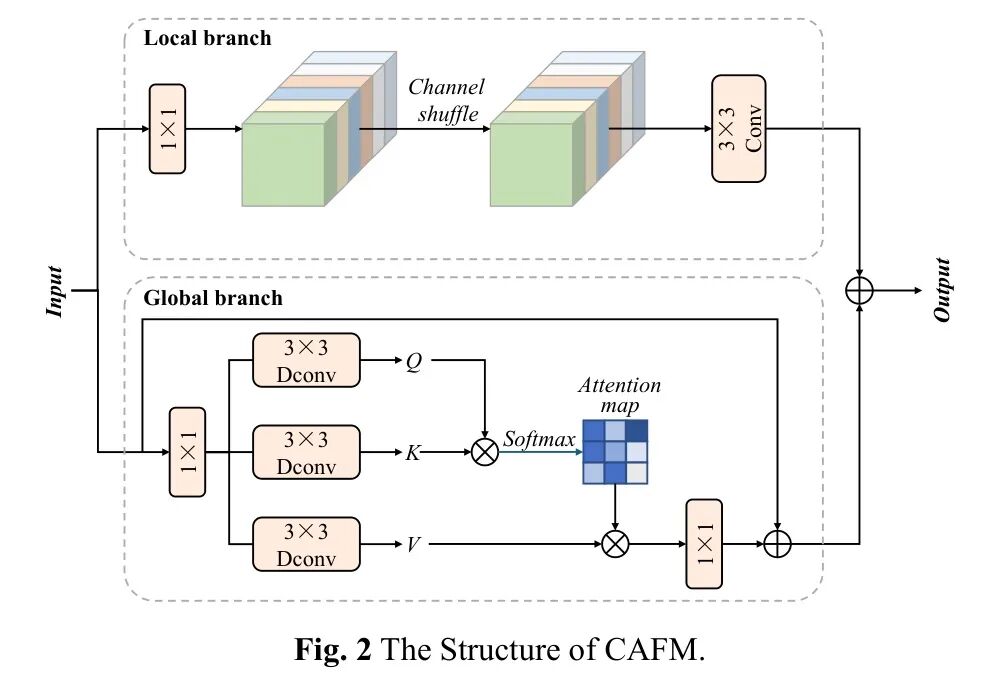
虽然传统的卷积操作和标准的注意力机制是有效的,但它们往往难以精确建模现实场景中常见的细长、轴向对齐和部分遮挡的结构,例如侧面人脸、手持物体或与疲劳相关的手势。为了应对这些挑战,RCM [42]被整合到网络中,如图3所示,RCM包含四个关键组成部分:轴向全局上下文聚合、形状自校准重建、局部-全局特征融合和残差细化。
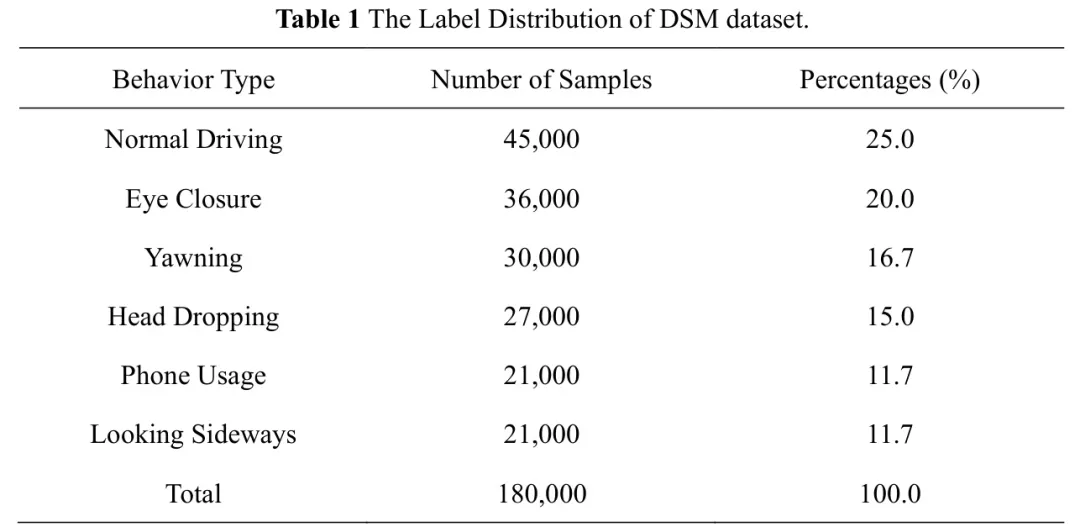
为了建模矩形区域,RCM将2D全局注意力分解为水平池化(HP)和垂直池化(VP),其中水平池化沿每行平均特征响应以捕获水平上下文,垂直池化沿每列平均响应以捕获垂直上下文,这两个轴向全局上下文通过广播相加形成初始的粗略矩形注意力图,如下所示:

2.3 多尺度检测Head
多尺度检测Head在三种分辨率(P3, P4, P5)上运行,每个分辨率都嵌入了一个RCM块,用于在预测之前优化语义表示,其中最终的Detect模块在各个尺度上预测三个类别的类别概率和边界框,通过在 Backbone 网络尾部引入CAFM,并在检测尺度上引入RCM,YOLO11-CR通过融合注意力有效改善了正常面部的检测以捕获全局面部结构,通过矩形核改善侧面面部的检测以定位细长轮廓,并通过多尺度上下文和方向注意力改善手机的检测以抑制背景噪声和杂乱。
3. 实验设置
为了验证所提出的YOLO11-CR模型在疲劳检测方面的有效性,作者设计并执行了一套全面的实验。本节详细介绍了实验设置,包括数据集选择、评估指标和实现细节。
3.1 实验数据集
为评估所提出的YOLO11-CR模型在检测疲劳相关行为方面的有效性,本研究采用了Driver State Monitoring (DSM)数据集,这是一个专门为驾驶员疲劳和分心检测整理的综合基准数据集。DSM数据集源自Ortega等人提出的公开可用的DMD数据集,该数据集是领域内最广泛采用的多模态驾驶员监测数据集之一。
DSM数据集包含超过180,000张RGB图像,这些图像是从车载视频录像中提取的,涵盖了城市道路、高速公路和夜间驾驶等多种环境。数据是通过安装在仪表盘和天花板上的高清摄像头收集的,确保了正面和侧面视角的覆盖。如图4所示,数据集中的几个典型样本展示了所捕获行为的多样性,包括面部表情和侧面姿势。每张图像都标注了特定行为的标签,包括"正常驾驶"、"闭眼"、"打哈欠"、"低头"、"使用手机"和"侧视",详细的标签分布见表1。该数据集包含边界框、面部标志和遮挡 Level 的标注,使得检测模型能够在不同的视觉条件下进行稳健评估。此外,该数据集还包含了各种人口统计特征,如不同年龄段、性别和配饰(例如太阳镜、帽子、 Mask ),使其成为需要在不同驾驶员间进行泛化的疲劳检测任务的理想选择。为了模型训练和评估的目的,该数据集按7:2:1的比例划分为训练集、验证集和测试集。

除了逐帧标注外,DSM数据集还支持时序分析,允许应用序列模型来检测渐进性疲劳症状,如眨眼频率降低或微睡眠。正如Ortega等人所强调的,其多模态结构和现实世界复杂性使其成为测试安全关键型汽车应用中疲劳检测系统的理想基准。
3.2 实现细节
所有实验均在使用配备AMD Ryzen 9 5950X CPU、NVIDIA GeForce RTX 3090 GPU和64 GB DDR5 RAM的高性能计算环境中进行。操作系统为Windows 11,实现使用Python 3.11.2和支持CUDA12.4的PyTorch 2.5.1完成。此配置确保了充足的计算资源,能够高效处理大规模训练任务。
在训练过程中,批量大小设置为64,并使用随机梯度下降(SGD)优化器,初始学习率为0.001。在训练过程中,使用余弦退火调度器动态调整学习率。SGD的动量系数设置为0.937,以促进稳定收敛。模型总共训练了100个轮次。未采用早停机制,使模型能够完成完整的训练计划并彻底探索优化景观。
为了增强泛化能力和鲁棒性,在训练过程中应用了数据增强技术。具体而言,采用了Mosaic增强和随机水平翻转来增加训练样本的多样性,并模拟各种真实世界的驾驶条件。
3.3 评估指标

4. 实验结果与讨论
为了全面评估所提出的YOLO11-CR模型的有效性,作者进行了一系列与几个 Baseline 检测模型的对比实验。本节详细分析了结果,通过消融研究检验了各个模块增强的影响、分类检测精度、混淆矩阵洞察、精确度-召回率特性以及与最先进(SOTA)模型的比较。
4.1 消融实验
为了评估CAFM和RCM对整体性能提升的贡献,进行了一项消融研究。结果如表2所示。
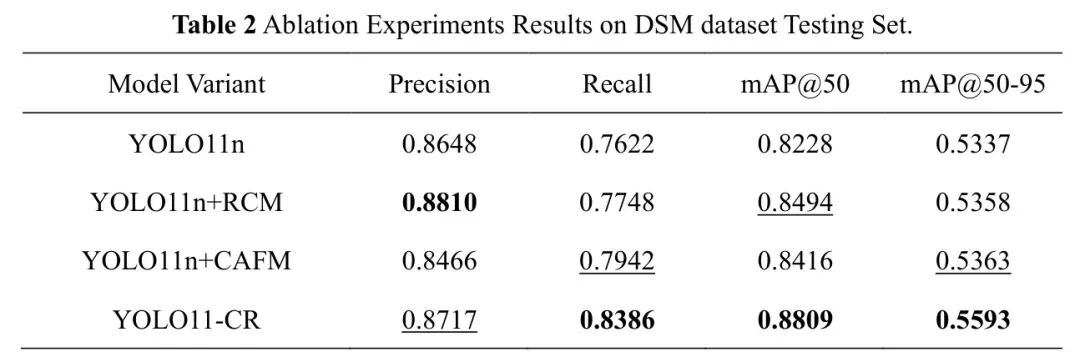

鉴于手机类别通常涉及小尺寸物体,召回率和精度的综合提升表明YOLO11-CR在检测小型、被遮挡和非正面目标方面特别有效。这验证了先进的多尺度特征融合和自适应空间校准对于改善现实世界条件下的驾驶员监控系统至关重要的直觉。
总体而言,消融研究证实了这两个模块都独特且协同地贡献于YOLO11-CR模型的增强性能。
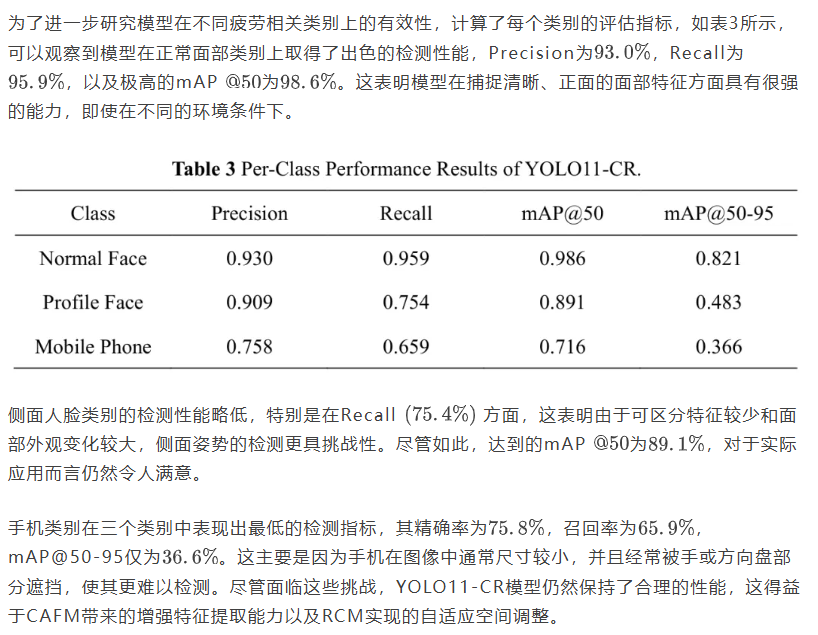
4.2 按类别性能分析
4.3 混淆矩阵分析
为了获得更深入的模型性能见解,对四个评估模型的归一化混淆矩阵进行了分析,如图5所示。每个混淆矩阵展示了在四个类别上的预测准确率:侧面人脸 (pface)、正面人脸 (nface)、手机和背景。
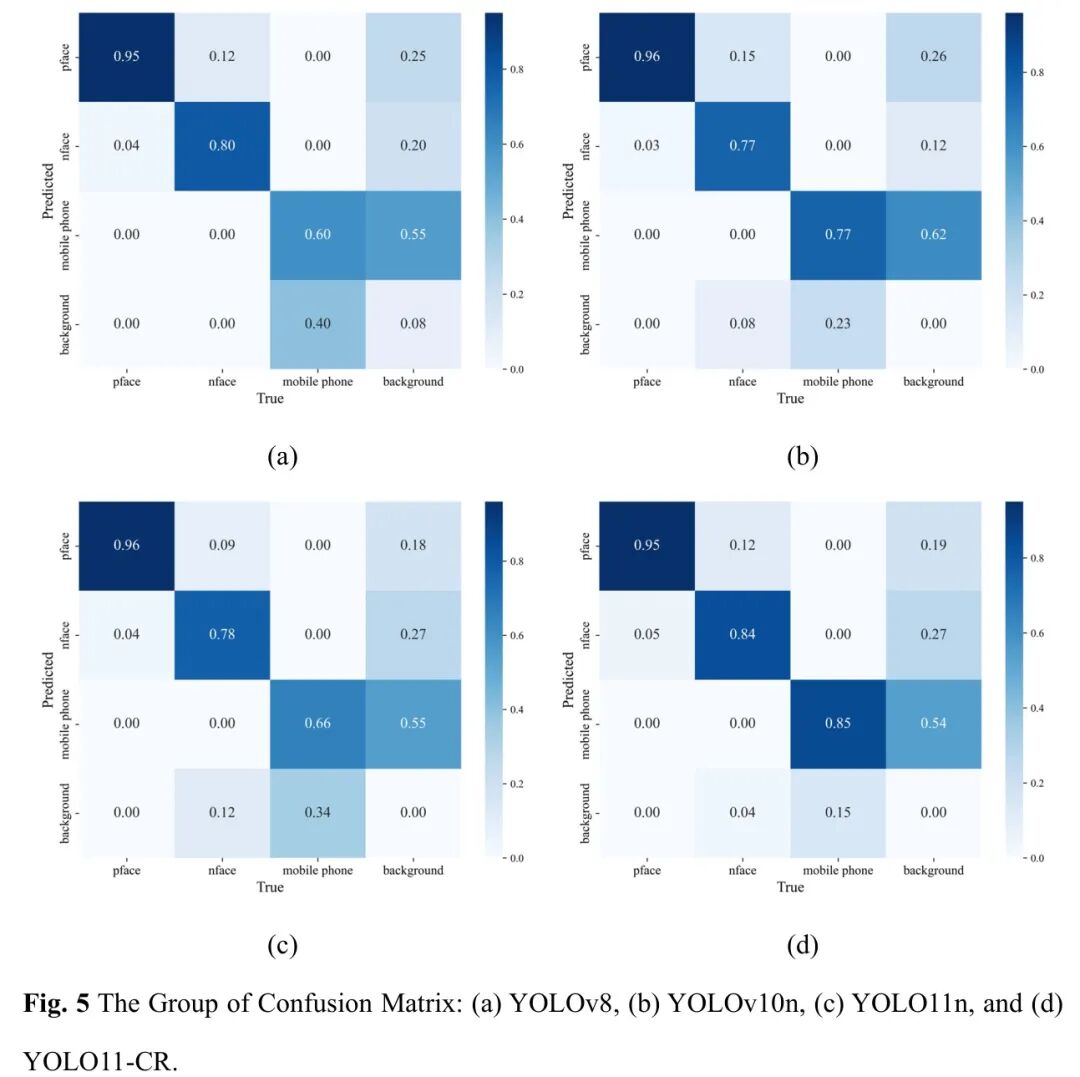
总体而言,混淆矩阵分析进一步证实,YOLO11-CR显著提高了分类敏感性(对于侧脸和手机等具有挑战性的类别具有更高的Recall)和分类特异性(在背景区域中具有更低的误报率),从而实现了平衡且稳健的性能,适用于现实世界的驾驶员监控应用。
4.4 Precision-Recall曲线分析
为了进一步评估不同模型的检测性能,分析了每个模型的精确率-召回率(PR)曲线,如图6所示。PR曲线描绘了在不同检测阈值下Precision和Recall之间的关系,全面展示了模型在平衡敏感性和特异性方面的稳健性。
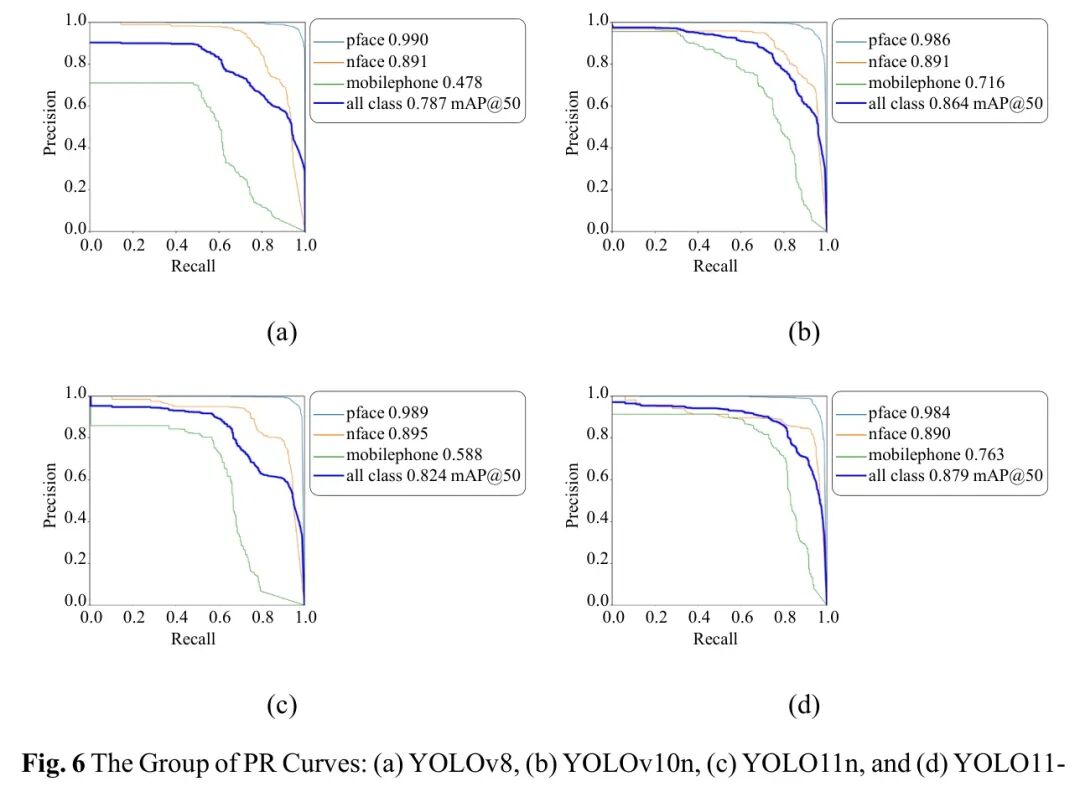

总体而言,PR曲线分析证实了YOLO11-CR模型具有优越的precision-recall平衡性和稳定性,确认了其在疲劳检测任务中实现高灵敏度和可靠性的有效性。
4.5 与SOTA的比较
最后,为了评估所提出的YOLO11-CR模型的有效性,作者与几个SOTA模型进行了对比实验,包括YOLOv8、YOLOv10n和YOLO11n。表4总结了这些模型在DSM数据集测试子集上的精确率、召回率、mAP@50、mAP@50-95、参数量、GLOPs和FPS等性能指标。尽管YOLO11-CR的FPS指标不是最优的,但考虑到所有其他性能指标都是最佳的,它在效率和准确性之间取得了理想的平衡。
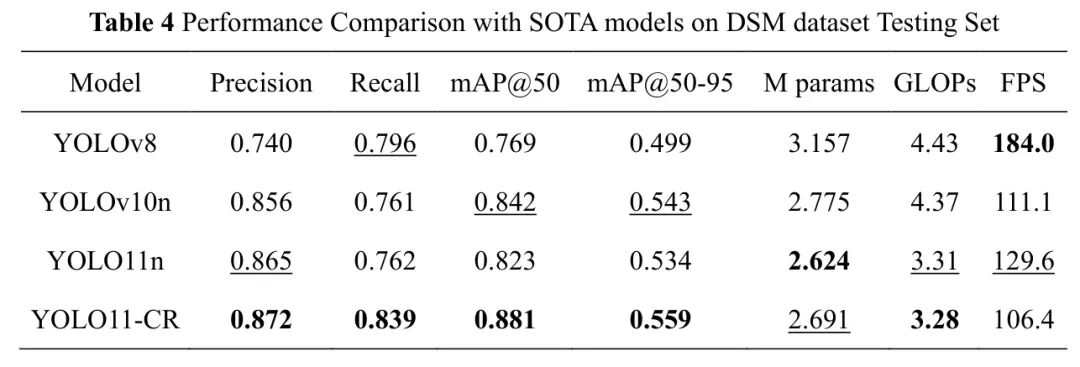
图7展示了不同YOLO系列模型在驾驶场景图像上的疲劳检测结果。每一行对应一组来自驾驶场景的测试样本,涵盖了车内人脸和手持物体等复杂工况。YOLOv8、YOLOv10n和YOLOv11n在手持目标检测中都不可避免地存在漏检或误检问题。相比之下,本文提出的YOLO11-CR模型有效解决了手机等长条形物体的漏检和误检问题,实现了更高的检测精度。

5. 结论
本文介绍了基于改进的YOLO11模型(称为YOLO11-CR)的轻量级、高精度疲劳驾驶检测系统的设计和优化。通过将CAFM和RCM集成到基础YOLO11架构中,所提出的模型显著增强了特征提取能力和空间定位精度,特别是对于小规模和被遮挡的物体。

总体而言,YOLO11-CR为实时疲劳监测提供了一个实用、高效且鲁棒的解决方案,在智能车载安全系统中具有强大的部署潜力。
参考
[1]. YOLO11-CR: a Lightweight Convolution-and-Attention Framework for Accurate Fatigue Driving Detection
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









