






本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
什么是图像标注工具
图像标注工具用于标记一组视觉数据,以确保机器学习模型训练的准确性。换句话说,用于训练计算机视觉模型的数据质量与其输出的准确性直接相关。正确标记的数据意味着计算机视觉模型能够识别和分类对象。因此,为其提供高质量的数据不仅是成功的关键,也是提高效率和节省成本的关键。
图像标注适用于众多行业,从医疗应用到零售、制造和地理空间等等。例如,DICOM(医学数字成像和通信)是医疗行业使用的标准格式,涵盖X射线、CT扫描、MRI扫描和超声图像。其应用范围广泛,从医学到地理空间成像,再到开发用于自动照片编辑的AI照片编辑工具。经过标注和训练的计算机视觉算法可以解读重要的元数据,用于图像分割、目标检测、图像配准、疾病诊断和治疗计划。
虽然标记数据是训练机器学习模型的基础,但由于它通常依赖于人工注释,因此可能会出现错误,因此拥有一个简化和改进这一过程的工具是关键。
Encord
Encord是一个端到端数据开发平台,配备先进的图像标注工具,适用于复杂的计算机视觉和多模态用例。该平台提供先进的模型辅助标记和可定制的工作流程,以加速图像标注项目并构建可用于生产的模型。
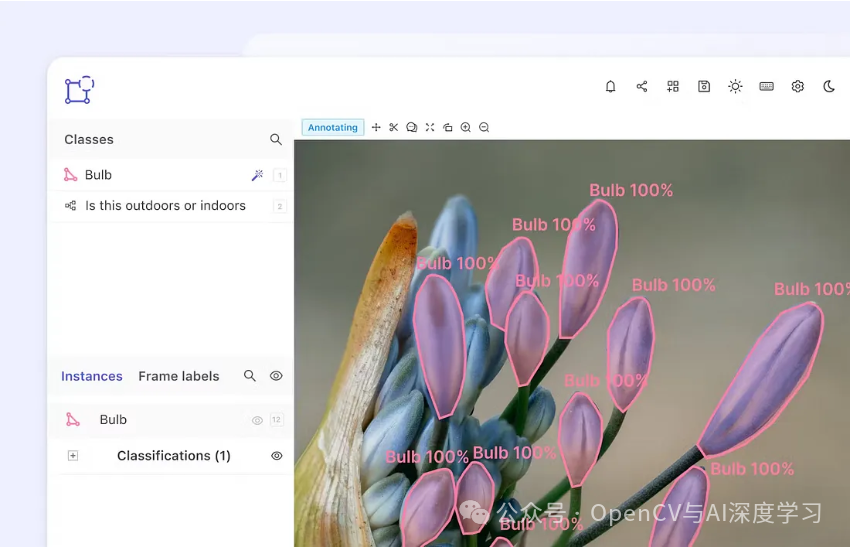
主要特点
-
-
人工智能辅助标记:利用 SOTA 自动标记功能(例如 Meta AI 的 Segment Anything 模型 ( SAM )),以 99% 的准确率自动完成 97% 的图像注释。
-
全套工具: Encord 支持一系列标签选项,例如边界框、可旋转框、多边形、折线、关键点和分类,以支持您的模型要求。
-
使用模型在环加速:将您自己的模型带到 Encord 平台或利用我们的一个代理预先标记数据集。
-
可扩展性:Encord 支持多达 500,000 张图像的大量数据集,让您可以扩展 AI 项目。
-
构建平衡的数据集: 在整合的可视化浏览器中筛选和切片数据集,并一键导出进行标记。Encord 支持深度搜索、筛选和元数据分析。
-
复杂本体:在数据模式中构建嵌套关系结构,以提高模型输出的质量。
-
批量分类:利用自然语言或相似性搜索选择大型数据集并进行批量标记,排队审核以加速标记操作。
-
构建可靠的质量控制工作流程:构建具有多步骤审查阶段和质量保证共识基准的强大工作流程。
-
查找并修复标签错误:自动显示标签错误,以将您的注意力转移到影响模型性能的标签上。
-
协作:通过权限控制用户角色,管理任务分配并无限扩展您的 MLOps 工作流程。
-
企业级安全性作为标准: Encord Annotate 符合通用数据保护条例(GDPR )、系统和组织控制 2 (SOC 2 ) 和健康保险流通与责任法案 ( HIPAA ) 标准,同时使用高级加密协议来确保数据隐私。
-
集成: Encord 让您完全掌控数据。安全连接您的原生云存储,并以编程方式控制工作流程。先进的 Python SDK 和 API 访问,轻松导出为 JSON 和COCO格式。
-
集成数据标记服务:将您的标记任务外包给经过审查、培训和专业的注释人员组成的专家团队。
-
涵盖的方式
-
-
图像
-
视频
-
DICOM
-
SAR
-
文件
-
音频
-
G2 评测总结
Encord 的评分为 4.8/5(基于 60 条评论)。用户更青睐 Encord 强大的本体功能,该功能能够为各种规模的数据定义丰富的分类法。此外,该平台的协作功能和精细的注释工具有助于用户提升注释质量。
亚马逊 SageMaker Ground Truth
Amazon SageMaker Ground Truth 是一个人机交互数据标记平台,提供标记大型数据集的功能。它提供自助服务和托管服务选项,帮助您简化多项 CV 任务的注释工作流程。
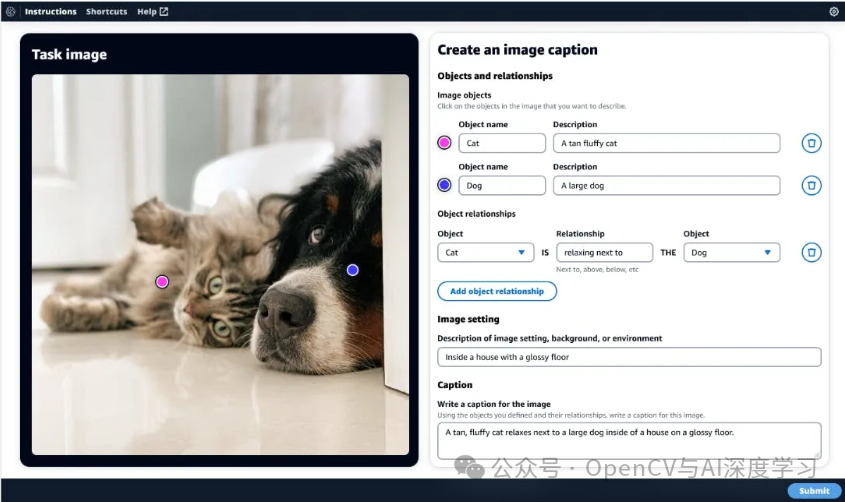
主要特点
-
-
数据生成:该平台提供工具来对几个数据点上的预训练模型进行微调,以生成合成数据样本,从而进行更多样化的训练。
-
模型评估: Sagemaker Ground Truth 让您能够通过人工反馈,根据准确性、相关性、毒性和偏见等多项指标来评估基础模型。
-
标签模板:它具有超过三十个标签模板,适用于多个 CV 和 NLP 任务,包括图像分类、对象检测、文本分类和命名实体识别 ( NER )。
-
交互式仪表板:该工具提供直观的仪表板和用户友好的界面,以监控多个项目的标签进度。
-
涵盖的方式
-
-
图像
-
视频
-
文本
-
点云
-
优点和缺点
优点:
-
-
自动标注
-
支持多种数据类型
-
可定制的标签工作流程
-
与 Amazon SageMaker 集成
-
缺点:
-
-
与非 AWS 服务结合使用可能会带来摩擦
-
对贴标机的控制有限
-
设置需要熟悉 AWS 的 IAM 策略、权限和一般 AWS 环境
-
可能缺乏某些小众或复杂项目所需的定制深度
-
G2 评测总结
Amazon SageMaker Ground Truth 的评分为 4.1/5(基于 19 条评论)。用户喜欢它的易用性和高级注释功能。然而,他们认为它价格昂贵,而且追踪标记性能具有挑战性。
Scale Rapid
Scale Rapid 是一个支持计算机视觉用例的数据和标签服务平台。它专注于人工反馈强化学习 ( RLHF )、用户体验优化、大型语言模型 (LLM) 和合成数据。
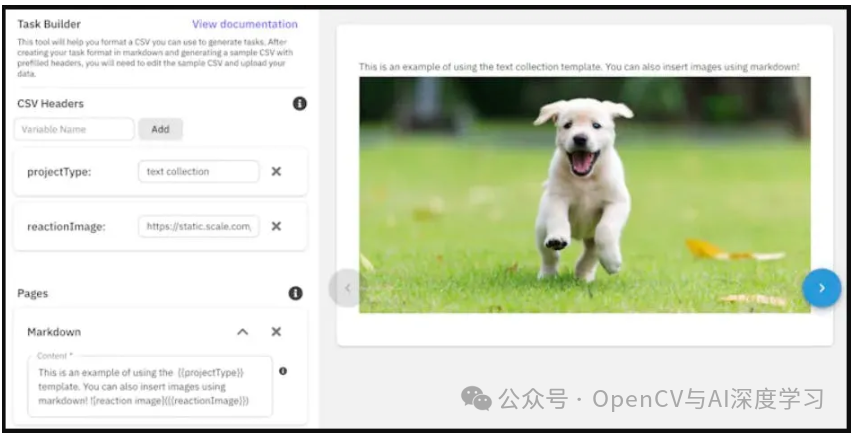
主要特点
-
-
支持的数据类型: Scale 允许您注释文本、图像、视频、音频和点云数据。
-
可定制的工作流程:提供根据特定项目要求和用例定制的标签工作流程。
-
数据标注服务:为图片、文本、音频、视频等多种数据类型提供高质量的数据标注服务。
-
可扩展性:能够处理大型注释项目并适应不断增长的数据集和注释需求。
-
涵盖的方式
-
-
图像
-
视频
-
测试
-
文件
-
音频
-
优点和缺点
优点:
-
-
通过人工参与标记实现高质量注释
-
针对速度进行了优化,即使在大型数据集上也能提供快速的交付时间
-
支持一系列复杂数据类型,包括 3D 点云和 LiDAR 数据
-
内置质量控制措施
-
缺点:
-
-
可能无法提供高度特定或非常规标签任务所需的深度定制
-
与一些竞争对手相比,自动化标签集成程度不够
-
不能直接集成到机器学习流程中
-
G2 评测总结
Scale Rapid 的评分为 4.4/5(基于 11 条评论)。用户表示它易于学习,无需复杂的安装程序。然而,他们认为该工具的用户界面略显笨重,且定价机制复杂。
Supervisely
Supervisely 是一个端到端的计算机视觉平台,提供多种用于标记图像和视频的注释工具。它具有基于 AI 的标记功能,允许用户通过高级机器学习模型自动化标记工作流程。

主要特点
-
-
多功能注释工具:它支持多种注释类型,包括边界框、多边形、折线、点和分割蒙版,以实现精确标记。
-
支持的数据类型: Supervisely 允许您标记图像、视频、点云和医学图像数据。
-
智能标签工具:根据您的使用情况,提供基于可定制神经网络的类别无关智能工具,用于捕获任何对象类型。
-
协作:该平台允许您与团队成员协作并分配相关的用户角色来跟踪问题和标记性能。
-
涵盖的方式
-
-
图像
-
视频
-
点云
-
DICOM
-
优点和缺点
优点:
-
-
界面直观且高度可视化
-
提供针对高级注释类型(例如语义分割)的专用工具
-
整合人工智能辅助标签工具
-
用户可以创建自定义插件和脚本
-
缺点:
-
-
不提供内置的标签劳动力
-
缺乏一些高级工作流自动化功能
-
G2 评测总结
Supervisely 的评分为 4.7/5(基于 10 条评论)。用户喜欢该工具与 Supervisely 生态系统中多个应用的集成,这带来了流畅的用户体验。然而,其选项数量可能过于繁琐,而且平台存在延迟问题。
Labelbox
Labelbox 是一家成立于 2017 年的美国数据注释平台,它通过协作和模型评估工具为整理和标记数据集提供了统一的框架。
除了独立的图像标记平台外,该工具还提供由数据标记专家提供的托管注释服务。
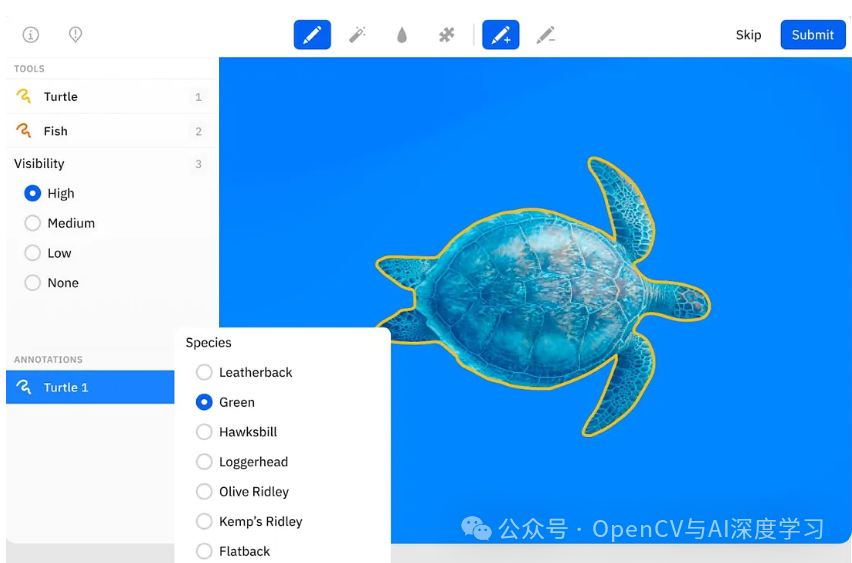
主要特点
-
-
数据管理:Labelbox 提供 QA 工作流程和数据注释器性能跟踪。
-
可定制的标签界面:它具有用户友好的界面,为特定需求提供易于导航的编辑器。
-
自动化:允许与 AI 模型集成,实现自动数据标记,从而加速注释过程。
-
注释功能:它支持图像以外的多种数据类型的注释,包括文本、视频、音频、地理空间和医学图像。
-
涵盖的方式
-
-
图像
-
视频
-
文本
-
音频
-
优点和缺点
优点:
-
-
具有质量保证工具,例如共识评分和注释审查
-
包括人工智能辅助标记工具
-
与流行的机器学习框架和平台集成
-
缺点:
-
-
可能无法提供高度专业化的工作流程所需的深度定制
-
高度基于云,这可能会对数据治理严格的行业带来挑战
-
处理高分辨率图像或视频数据有时可能会影响平台性能
-
G2 评测总结
LabelBox 的评分为 4.7/5(基于 33 条评论)。用户认为该工具的数据管理功能很实用。然而,他们认为它在处理高分辨率图像时效果不佳。
Playment
Playment 是一家总部位于印度的端到端数据注释平台,成立于 2015 年,目前由 Telus 旗下运营。它通过聘请计算机视觉团队为多种用例注释训练数据,提供托管注释服务。

主要特点
-
-
数据标注服务:为各种数据类型提供高质量的数据标注服务,包括图像、视频、文本、传感器数据等。
-
支持:承包商和数据标签员的全球劳动力。
-
可扩展性:能够处理大规模注释项目并适应不断增长的数据集和注释需求。
-
音频标记工具:该工具具有语音识别训练平台,可以处理五百多种语言和方言。
-
涵盖的方式
-
-
图像
-
视频
-
点云
-
优点和缺点
优点:
-
-
在自动驾驶、地理空间分析和室内地图等复杂用例中表现出色
-
包括具有质量控制机制的人机交互流程
-
多个质量控制层,包括审计、共识评分和反馈循环
-
允许在工作流程中进行一些定制
-
缺点:
-
-
缺乏一些先进的人工智能辅助标签功能
-
主要基于云的平台,这可能会给严格数据隐私的组织带来挑战
-
G2 评测总结
Playment 的评分为 4.7/5(基于 11 条评论)。用户认为 Playment 的注释速度快且准确。然而,他们认为该工具价格昂贵,且自动标记功能需要进一步改进。
Appen
Appen 是一家成立于 1996 年的数据标签服务平台,是市场上最早、历史最悠久的解决方案提供商之一,为各行各业提供数据标签服务。2019 年,Appen 收购了Figure Eight,以扩展其软件能力,并帮助企业训练和改进其计算机视觉模型。

主要特点
-
-
数据标签服务:支持多种注释类型(边界框、多边形和图像分割)。
-
数据收集:数据采购(预先标记的数据集)、数据准备和真实世界模型评估。
-
自然语言处理:支持情感分析、实体识别和文本分类等自然语言处理 (NLP) 任务。
-
图像和视频分析:分析图像和视频以执行对象检测、图像分类和视频分割等任务。
-
涵盖的方式
-
-
文本
-
图像
-
音频
-
视频
-
优点和缺点
优点:
-
-
采用共识评分、准确性监控和注释审查等质量控制流程
-
可以与流行的机器学习工具和平台集成
-
多语言数据标记专业知识
-
缺点:
-
-
并非完全为实时反馈或迭代调整而设计
-
依赖于自己管理的员工,可能缺乏希望使用内部团队的公司所需的集成选项
-
G2 评测总结
Appen 的评分为 4.2/5(基于 28 条评论)。用户喜欢这款工具基于网页,无需特殊安装程序。然而,该平台的服务器经常崩溃,而且支持团队的响应速度很慢。
Dataloop
Dataloop 是一个位于以色列的数据标记平台,为数据管理和注释项目提供全面的解决方案。该工具提供涵盖图像、文本、音频和视频注释的数据标记功能,帮助企业训练和改进其机器学习模型。
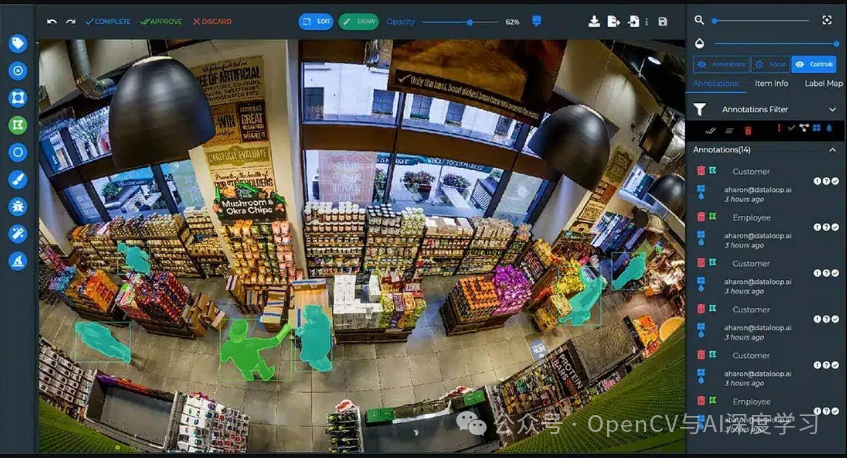
主要特点
-
-
数据注释:支持多种图像注释任务,包括分类、检测和语义分割。
-
协作工具:它具有注释者之间的实时协作、项目共享和版本控制工具,可实现高效的团队合作。
-
数据管理:提供数据管理功能,包括数据版本控制、跟踪和组织,以简化工作流程。
-
模型管理: Dataloop 提供工具来管理不同模型版本并从模型市场下载 SOTA 模型。
-
涵盖的方式
-
-
图像
-
视频
-
优点和缺点
优点:
-
-
支持多种注释类型
-
AI辅助标签功能
-
具有质量控制机制,包括注释审查和共识检查
-
与流行的机器学习工具和平台集成
-
缺点:
-
-
高度具体的工作流程或特定的注释要求可能需要额外的定制
-
对自然语言处理 (NLP) 或音频数据的工具和支持相对有限
-
G2 评测总结
Dataloop 的评分为 4.4/5(基于 90 条评论)。该工具的优点包括易用性和注释效率。然而,用户发现它学习起来比较困难,而且经常遇到性能问题。
SuperAnnotate
SuperAnnotate 是一个端到端 AI 平台,提供数据管理和自动注释工具,并支持 MLOps 功能。它还允许您使用带注释的数据和 RLHF 对 LLM 进行微调。
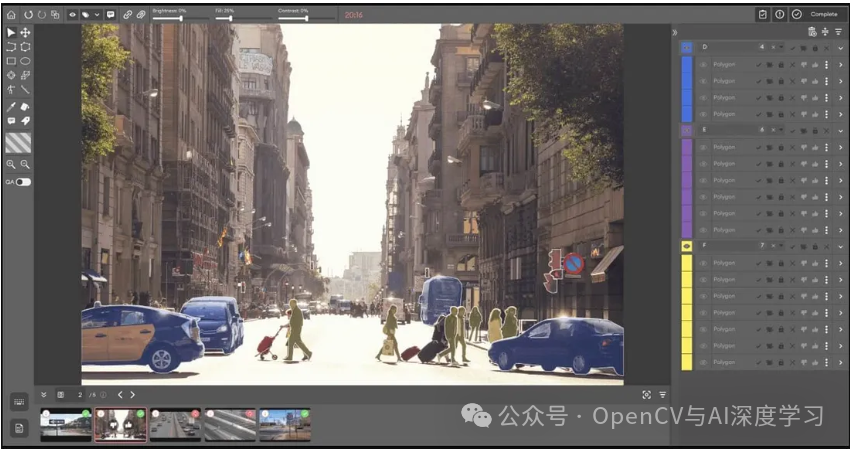
主要特点
-
-
多数据类型支持:用于标记视频、文本、音频和图像数据的多功能注释功能。
-
AI辅助:集成AI辅助标注,加速标注流程,提高效率。
-
定制:提供可定制的注释界面和工作流程,以根据特定的项目要求定制注释任务。
-
导出格式:SuperAnnotate 支持多种数据格式,包括 JSON、COCO 和 Pascal VOC 等流行格式。
-
涵盖的方式
-
-
图像
-
文本
-
视频
-
音频
-
优点和缺点
优点:
-
-
支持多种注释类型
-
包括人工智能辅助标签功能
-
与流行的机器学习框架集成
-
缺点:
-
-
不提供内置注释器
-
不像其他平台那样专注于自然语言处理 (NLP) 任务
-
大型视频数据集或高分辨率媒体的挑战
-
G2 评测总结
SuperAnnotate 的评分为 4.9/5(基于 137 条评论)。用户认为该工具功能全面,界面直观。然而,也有人抱怨其自定义工作流程设置和高昂的价格。
V7 Labs
V7 是一家总部位于英国的数据注释平台,成立于 2018 年。该公司支持团队使用自动化流程和自定义工作流程注释图像和视频数据。该平台还提供模型和数据管理工具,帮助用户为可扩展的 AI 项目构建高质量的训练数据。

主要特点
-
-
协作能力:项目管理和自动化工作流程功能,具有实时协作和标记功能。
-
数据管理:该工具提供数据管理功能,包括过滤和排序数据的功能。它还有助于在团队和数据集级别组织和管理数据类。
-
自动注释:具有自动注释功能,可让您使用深度学习模型创建像素完美的多边形蒙版。
-
自动跟踪: V7 提供自动跟踪功能,用于长视频中的对象跟踪和实例分割。
-
涵盖的方式
-
-
图像
-
视频
-
DICOM
-
优点和缺点
优点:
-
-
高级 AI 辅助标记功能
-
支持多种注释类型,包括边界框、多边形和关键点
-
与流行的机器学习框架和云存储提供商集成
-
缺点:
-
-
主要关注图像和视频数据,未针对 NLP 或音频任务进行优化
-
一些人工智能辅助功能和集成在本地部署中可能会受到限制,因为它们依赖于云基础设施
-
G2 评测总结
V7 的评分为 4.8/5(基于 52 条评论)。用户认为其自动化和协作功能非常有用。然而,他们认为 V7 缺乏文件操作选项,并且其排序和过滤功能在处理大文件时效果不佳。
Hive
Hive 是一个内容审核平台,提供深度学习模型来突出显示图片、视频、文本和音频中有害且露骨的内容。它还具有搜索和生成 API,可以可视化图片和视频之间的相似性,并根据文本提示生成图片。
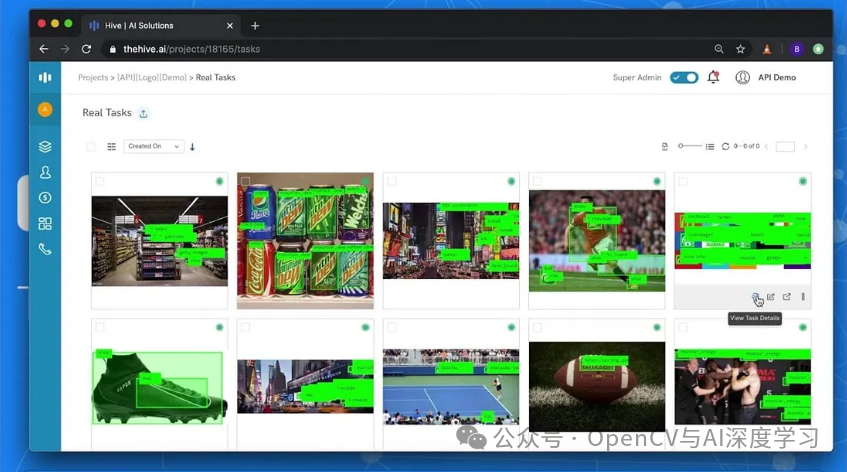
主要特点
-
-
易于使用: Hive 提供直观的界面,具有多个内置图像和文本分类模型。
-
嵌入:该平台允许您快速创建文本嵌入,以构建基于检索增强生成 ( RAG ) 的 LLM。
-
搜索: Hive 提供丰富的网页搜索功能。您可以使用图片提示来检索类似图片的相关链接。
-
生成人工智能 (Gen AI): Hive 具有 API,可根据文本提示生成文本、图像和视频。
-
涵盖的方式
-
-
图像
-
文本
-
音频
-
优点和缺点
优点:
-
-
可以对图像进行实时审核
-
允许用户创建自定义审核类别和规则
-
包括强大的 API 选项,可无缝集成到现有工作流程中
-
缺点:
-
-
复杂案件仍需人工监督
-
对于利基领域或高度特定的内容类别可能不那么有效
-
一些定制挑战,例如专门的审核工作流程。
-
G2 评测总结
Hive 的评分为 4.6/5(基于 528 条评论)。用户认为其项目管理和协作功能很实用。然而,其界面导航困难,且存在一些小故障,导致操作复杂。
Label Studio
Label Studio 是一个流行的开源数据标注平台,用于标注各种类型的数据,包括图像、文本、音频和视频。它支持协作标注、自定义标注界面以及与机器学习 (ML) 流程的集成,以执行数据标注任务。

主要特点
-
-
可定制的标签界面:Label Studio 允许您通过灵活的配置标记数据,从而允许您根据特定任务定制注释界面。
-
协作工具:实时注释和项目共享功能,实现注释者之间的无缝协作。
-
导出格式:Label Studio 支持多种数据格式,包括 JSON、CSV、TSV 和 VOC XML(如 Pascal VOC),方便从不同来源进行机器学习任务的集成和注释。
-
ML 管道: Label Studio 可让您将模型开发管道与数据标记项目连接起来。该方法允许您使用 ML 模型预测标签、评估模型性能并执行人工参与的标记。
-
涵盖的方式
-
-
图像
-
音频
-
文本
-
视频
-
优点和缺点
优点:
-
-
该平台是开源的,允许用户下载、定制和运行,无需支付许可费用
-
支持多种数据类型和注释类型
-
可定制的用户界面,允许用户创建适合特定项目需求的独特注释界面
-
与机器学习工作流程和其他平台的集成
-
缺点:
-
-
需要预标记或 AI 注释支持的用户需要集成第三方工具或自定义模型
-
未针对大规模高通量实时标记进行优化
-
对高级项目管理功能(如工作流自动化和任务优先级)的支持有限
-
G2 评测总结
G2 审核不可用。
OCO Annotator
COCO Annotator 是一款基于 Web 的标注工具,由 Justin Brooks 开发,遵循 MIT 许可证。该工具有助于简化用于对象识别、定位和关键点检测模型的图像标注流程。它还提供一系列功能,以满足机器学习从业者、数据科学家和研究人员的多样化需求。
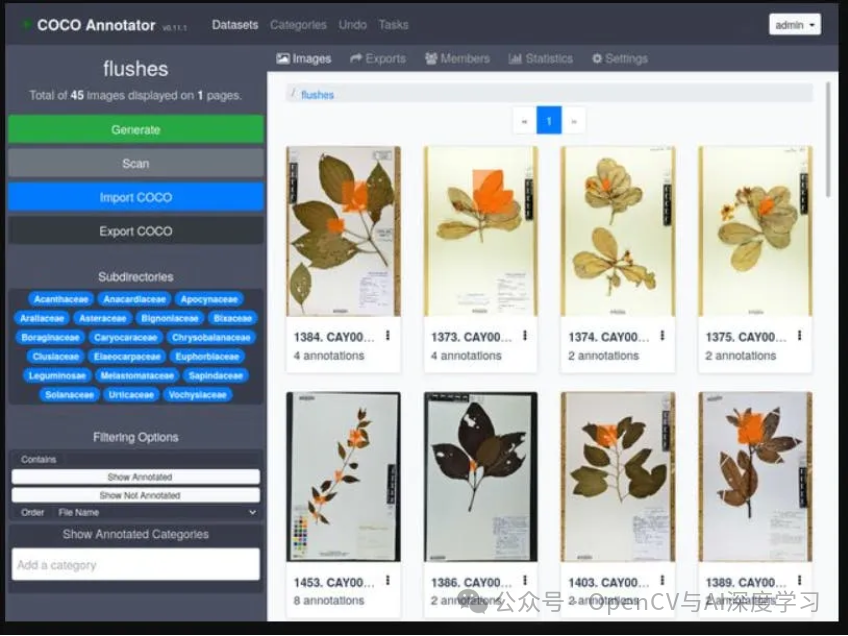
主要特点
-
-
图像注释:支持对象检测、实例分割、关键点检测和字幕任务的图像注释。
-
导出格式:该工具以 COCO 格式导出和存储注释,以方便进行大规模对象检测。
-
自动化:该工具通过整合半训练模型,简化了图像注释。它还提供高级选择工具,包括基于遮罩区域的卷积神经网络 ( MaskRCNN )、Magic Wand 和深度极值分割 ( DEXTR)框架。
-
元数据管理:用户可以为每个实例或对象创建自定义元数据。
-
涵盖的方式
-
-
图像
-
优点和缺点
优点:
-
-
易于与 COCO 数据集或其他使用此格式的系统配合使用
-
支持多种注释类型
-
开源,允许用户满足特定的项目需求
-
缺点:
-
-
缺乏对音频、视频和文本注释的支持
-
不包括共识评分和审查工作流程等高级质量控制工具
-
对于非常大的数据集或大量并发用户,可能无法实现最佳性能
-
没有内置的AI辅助标签工具
-
5 款最佳免费图像注释工具
以下部分概述了最好的免费图像注释工具,包括它们提供的功能以及它们的评价方式。
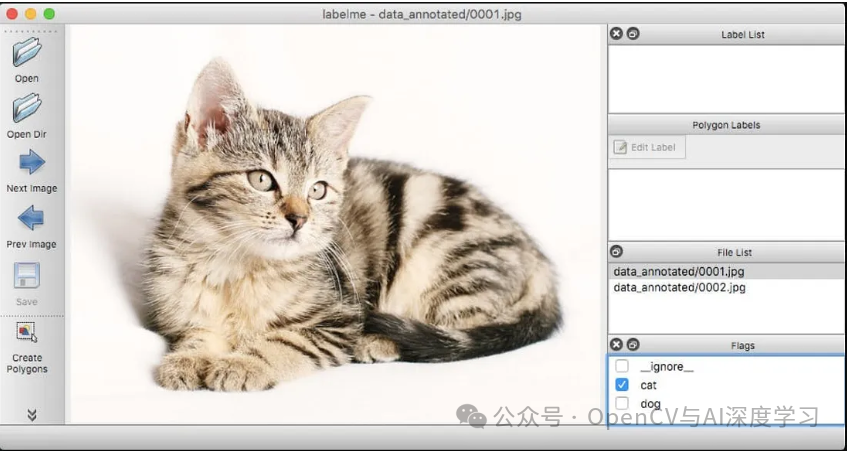
LabelMe
LabelMe 是麻省理工学院计算机科学与人工智能实验室 (CSAIL) 开发的一款基于 Web 的开源工具,允许用户为计算机视觉研究的图像添加标签和注释。它提供了一个用户友好的界面,用于绘制边界框、多边形和语义分割蒙版,以标记图像中的对象。
主要特点
-
-
基于 Web:可通过基于 Web 的界面访问,允许您在任何现代 Web 浏览器中执行注释任务,而无需安装软件。
-
支持的数据类型:该工具支持图像和视频注释。
-
支持的注释类型: LabelMe 允许您绘制多边形、矩形、圆形、线条和点。
-
导出格式:它允许您以 VOC 和 COCO 格式导出注释以进行语义和实例分割。
-
涵盖的方式
-
-
图像
-
视频
-
优点和缺点
优点:
-
-
免费使用,为预算有限的团队和研究人员提供灵活性
-
可以自托管,让用户完全控制数据隐私和安全
-
开发人员可以修改以添加功能或自定义其功能
-
缺点:
-
-
缺乏自动分割或对象跟踪等人工智能辅助标记功能
-
缺乏质量控制和协作功能
-
需要手动上传和导出数据
-
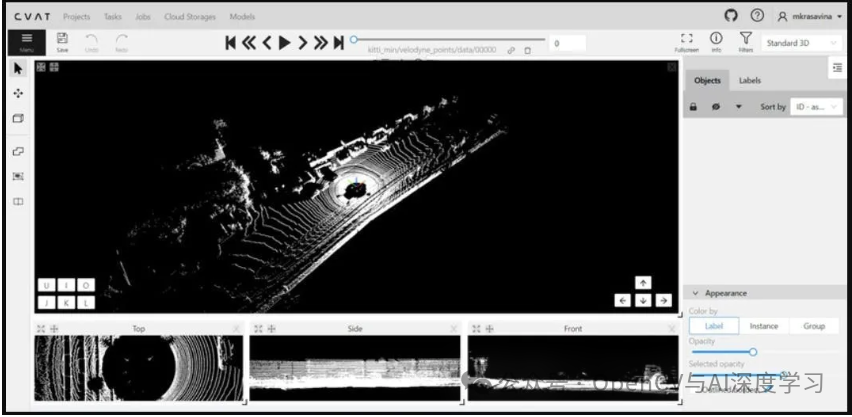
CVAT(计算机视觉标注工具)
CVAT是英特尔开源的基于 Web 的图像标注工具。2022 年,CVAT 的数据、内容和 GitHub 代码库并入 OpenCV,并继续保持开源状态。此外,CVAT 还可以标注图像中的二维码,从而促进二维码识别与计算机视觉流程和应用程序的集成。
主要特点
-
-
手动注释工具:该工具支持各种注释类型,包括边界框、多边形、折线、点和长方体,满足不同的注释需求。
-
多平台兼容性:适用于 Windows、Linux 和 macOS 等多种操作系统,为用户提供灵活性。
-
导出格式:CVAT 支持多种数据格式,包括 JSON、COCO 和Pascal VOC,确保注释与各种工具和平台的兼容性。
-
自动标记: CVAT 支持多种算法,包括 Segment Anything 模型 ( SAM )、YOLOv3和 Deep Extreme Cut ( DEXTR )。
-
涵盖的方式
-
-
图像
-
视频
-
优点和缺点
优点:
-
-
免费使用且高度可定制
-
专门支持视频注释,具有逐帧注释和对象跟踪等功能
-
包括质量控制功能
-
与机器学习模型集成,提供半自动化标记
-
缺点:
-
-
运行 CVAT,特别是对于视频注释或大型数据集,会消耗大量的 CPU 和内存资源
-
虽然它提供了基本的任务分配和审查工作流程,但缺乏复杂的项目管理功能
-
不提供与流行云存储服务的原生集成
-
G2 评测总结
CVAT 根据两条评论获得了 4.5/5 的评分。用户喜欢这款工具,因为它免费使用,并且基于 Web,无需配置和安装。然而,其性能缓慢和后端服务器故障是最令人担忧的问题。
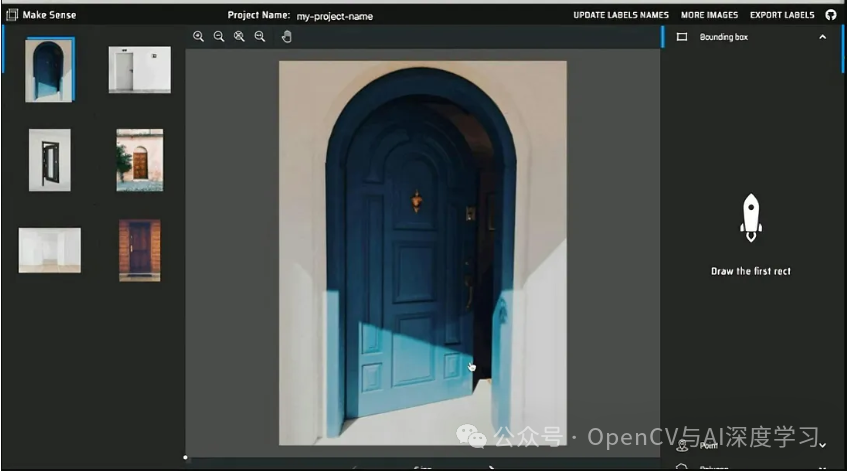
Make Sense
Make Sense AI 是一款用户友好的开源注释工具,遵循GPLv3许可证。它可以通过 Web 浏览器访问,无需高级安装。该工具简化了多种图像类型的注释流程。
主要特点
-
-
开源:Make Sense AI 是一款出色的开源工具,可根据 GPLv3 许可免费使用,促进协作和社区参与,从而促进其持续发展。
-
可访问性:它确保基于网络的可访问性,无需复杂的安装即可在网络浏览器中无缝运行,从而促进在各种设备上的易用性。
-
导出格式:它有助于以多种格式(YOLO、VOC XML、VGG JSON 和 CSV)导出注释,确保与各种机器学习算法兼容。
-
支持的注释类型:该工具支持矩形、线条、点和多边形。
-
涵盖的方式
-
-
图像
-
优点和缺点
优点:
-
-
完全免费且开源,对于预算有限的用户、小型研究团队和学生来说是一个有吸引力的选择
-
支持多种注释类型
-
可以自行托管,让用户完全控制其数据
-
缺点:
-
-
不提供人工智能辅助标签功能
-
缺乏项目管理和扩展功能,例如任务分配和注释跟踪
-
仅限于图像数据,不支持视频、音频或文本注释
-
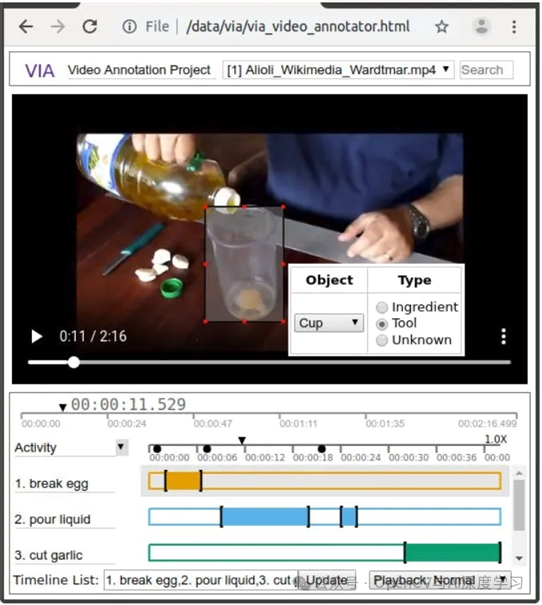
VGG Image Annotator
VGG 图像注释器 (VIA) 是由视觉几何组 (VGG) 开发的一款多功能开源工具,用于手动注释图像和视频数据。VIA 采用BSD-2条款许可,旨在满足学术界和商业用户的需求,为注释任务提供轻量级且易于访问的解决方案。
主要特点
-
-
轻量级且用户友好:VIA 是一种轻量级、独立的注释工具,它使用 HTML、Javascript 和 CSS,无需外部库。
-
离线功能:该工具可离线工作,在小于 200 KB 的单个 HTML 文件中提供完整的应用程序体验。
-
音频和视频注释:除了图像之外,该工具还允许用户使用文本描述定义音频和视频数据中的时间片段。
-
支持的注释类型:该工具允许您绘制矩形、圆形、椭圆形、多边形、点和折线。
-
涵盖的方式
-
-
图像
-
音频
-
视频
-
优点和缺点
优点:
-
-
完全免费且开源
-
允许用户定义区域的自定义属性,从而实现更详细、更结构化的注释
-
注释可以以 JSON 格式导出
-
缺点:
-
-
缺乏项目管理工具
-
不支持 AI 辅助标记功能,例如自动对象检测或分割
-
无法与外部存储解决方案或云平台原生集成,因此用户必须手动上传和管理其图像
-
VoTT(视觉对象标记工具)
VoTT 是一款开源图像标注工具,可直接从 Github 免费安装。它由微软创建,用于从图像和视频数据构建物体检测模型。VoTT 采用主动学习,这是一种监督式机器学习方法,利用训练数据优化周期来持续提升机器学习模型的性能。在此功能中,用户可以选择“预测标签”或“自动检测”。
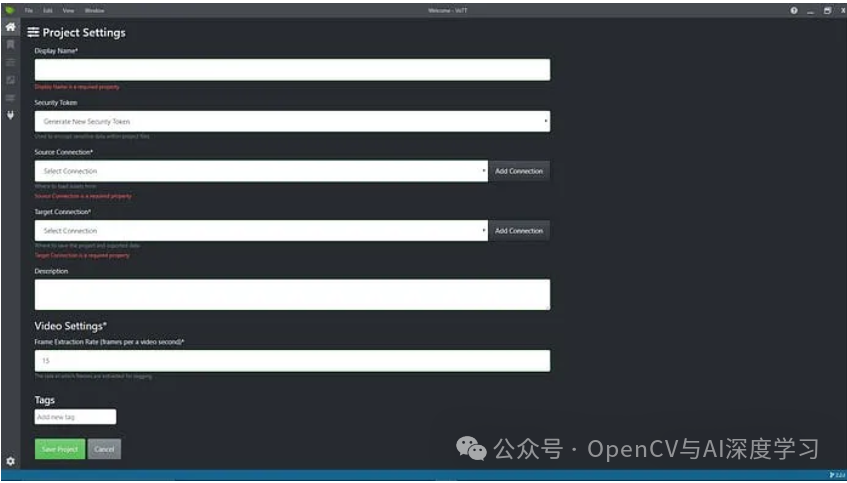
主要特点
-
-
多格式支持:可以在 Azure Custom Vision Service、CSV、CNTK、Pascal VOC、Tensorflow Records 和 VoTT Json 中导出。
-
标记功能:用户可以标记和注释图像目录和独立视频。
-
计算机辅助标记和跟踪:可以使用Camshift 跟踪算法标记对象。
-
标签导出功能:该工具允许将标签和资产导出为 CNTK 或 YOLO 格式
-
数据和模型验证:经过训练的 CNTK 对象检测模型可以进行验证
-
涵盖的方式
-
-
图像
-
视频
-
优点和缺点
优点:
-
-
完全免费且开源
-
与 Microsoft Azure 服务顺利集成,包括 Azure Blob 存储和 Azure 机器学习
-
包括人工智能辅助标记功能
-
缺点:
-
-
仅限于矩形和多边形注释
-
缺乏先进的项目管理功能、协作工具和内置质量控制
-
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 5248
5248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









