






本文来源公众号“江大白”,仅用于学术分享,侵权删,干货满满。
原文链接:CVPR 2025,即插即用MambaOut,图像分类、目标检测多场景SOTA!(附论文及源码)
导读
MambaOut挑战视觉Mamba权威:去掉SSM反而分类更强,检测分割也表现亮眼!轻量高效、即插即用,证明“曼巴退场”,未必是坏事。论文代码全公开,值得一看!

论文链接:https://arxiv.org/abs/2405.07992
代码链接:https://github.com/yuweihao/MambaOut
“我能说什么呢,曼巴要退场了。” —— 科比 · 布莱恩特2016年NBA告别演讲。
"Mamba Out"是已故篮球巨星科比 · 布莱恩特在退役战后的告别语。这句话蕴含了多重意义,它既是科比在球场上告别观众的用语,也象征着他作为"黑曼巴"这一绰号所代表的精神的结束。四年后(2020年1月),科比因直升机事故遇难。

一、论文信息
论文题目:MambaOut: Do We Really Need Mamba for Vision?
中文题目:MambaOut: 我们真的需要Mamba来实现视觉功能吗?
论文链接:https://arxiv.org/pdf/2405.07992
官方github:https://github.com/yuweihao/MambaOut/tree/main
所属机构:新加坡国立大学
核心速览:本文探讨了Mamba架构在视觉任务中的必要性,通过构建不包含状态空间模型(SSM)的MambaOut模型,验证了SSM对于图像分类任务并非必需,但对于检测和分割任务可能有益。
二、论文概要
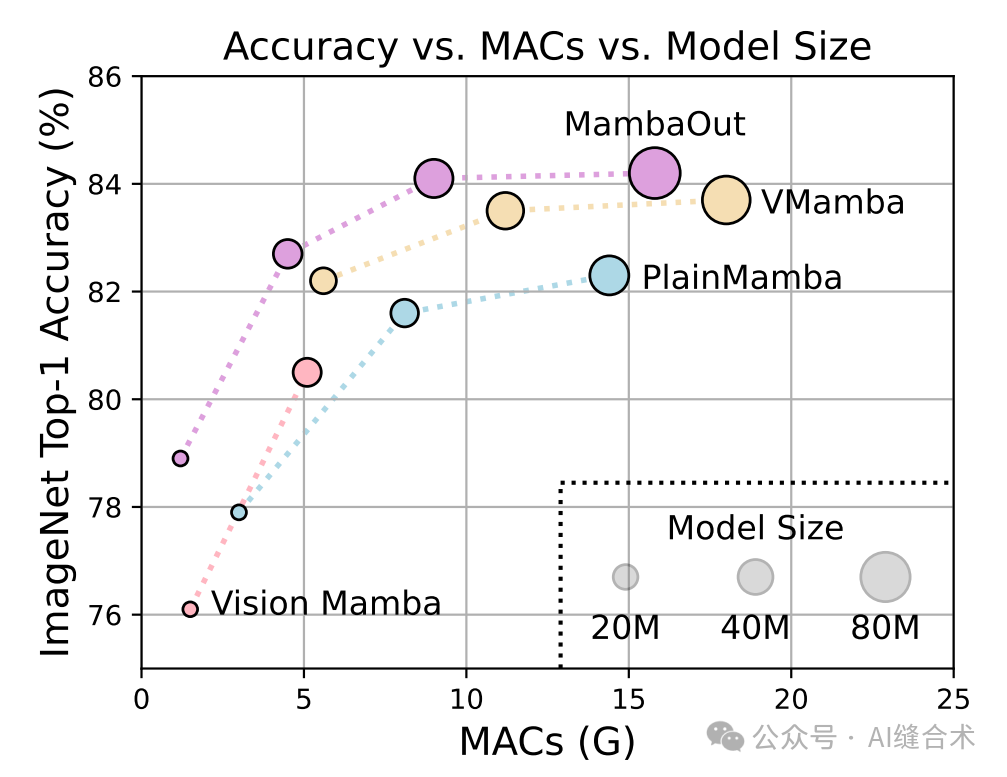
图1:(b) MambaOut在ImageNet图像分类上优于视觉Mamba模型,例如,Vision Mamba ,VMamba 和PlainMamba。
1. 研究背景:
-
研究问题:Mamba架构是否真的对视觉任务至关重要?鉴于Mamba在视觉任务中的表现通常不如卷积和基于注意力的模型,本文旨在探讨Mamba在视觉任务中的适用性。
-
研究难点:如何在保持模型性能的同时,减少模型复杂度和计算成本是研究中的一个关键挑战。此外,需要验证Mamba架构中SSM对于不同视觉任务的实际效用。
-
文献综述:回顾了Transformer架构及其在不同领域的应用,特别是其注意力机制的二次复杂度问题,以及为解决这一问题而提出的各种线性复杂度的token mixer。同时,文章也提到了RNN-like模型在处理长序列任务中的优势,以及Mamba架构在视觉识别任务中的应用尝试。
2. 本文贡献:MambaOut模型架构
-
模型结构:MambaOut模型基于Gated CNN块构建,通过堆叠这些块来构建模型。模型采用4阶段框架,每个阶段都堆叠了Gated CNN块。模型的配置细节包括不同阶段的块数和通道数,以及模型的参数量和MACs(乘加运算次数)。
-
核心区别:MambaOut与Mamba模型的主要区别在于MambaOut移除了SSM(状态空间模型)。Mamba模型基于Gated CNN块,但加入了SSM,而MambaOut则完全基于Gated CNN块,没有SSM。
-
实现细节:MambaOut模型的实现简洁优雅,采用深度可分离卷积作为token mixer,并且只在部分通道上执行深度可分离卷积以提高实际速度。模型的实现代码在PyTorch库中完成,并在TPU v3上进行训练。
三、创新方法
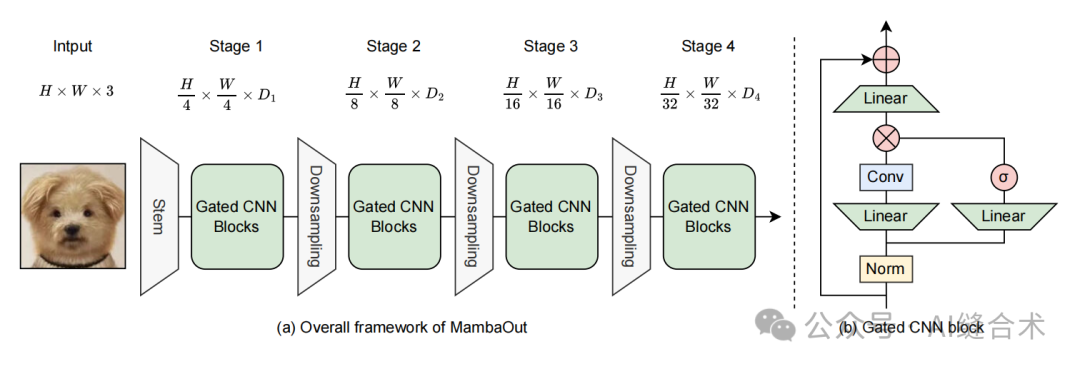
图4:(a) MambaOut用于视觉识别的整体框架。类似于ResNet,MambaOut采用具有四个阶段的分层架构。Di表示第i阶段的通道维度。(b) 门控CNN块的架构。门控CNN块与Mamba块之间的区别在于门控CNN块中缺少SSM(状态空间模型)。
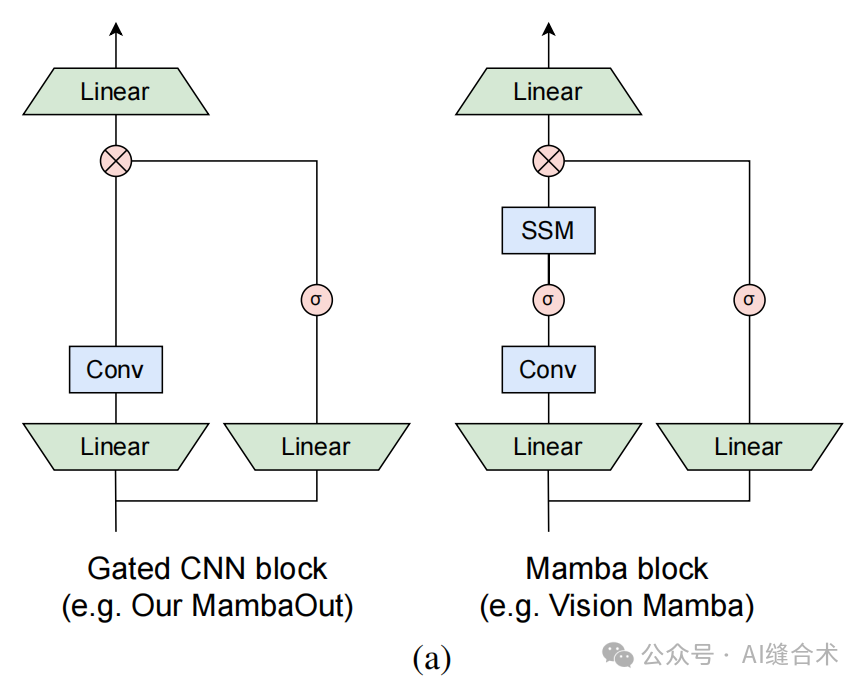
图1:(a) 门控CNN 和Mamba块的架构(省略了归一化和快捷连接)。Mamba块通过增加一个额外的状态空间模型(SSM)扩展了门控CNN。正如第3节将要概念性讨论的,SSM对于在ImageNet上的图像分类并不是必需的。为了实证验证这一说法,我们堆叠了门控CNN块来构建一系列名为MambaOut的模型。
Gated CNN block(MambaOut):通过归一化、Token Mixing、权重矩阵应用、线性变换和残差连接等步骤实现特征的提取和传递,相比Mamba减少了SSM。实现较为简单,主要步骤:
1. 输入归一化:首先对输入数据X进行归一化处理,这有助于稳定训练过程并提高模型性能。公式表示为:X' = Norm(X)。
2. Token Mixing:接着,使用Token Mixer对归一化后的数据进行处理。Token Mixer的作用是混合输入数据中的token,以提取特征。
3. 权重矩阵应用:在Token Mixer处理后,将结果与两个可学习的权重矩阵W1和W2进行点乘操作,然后应用激活函数σ。
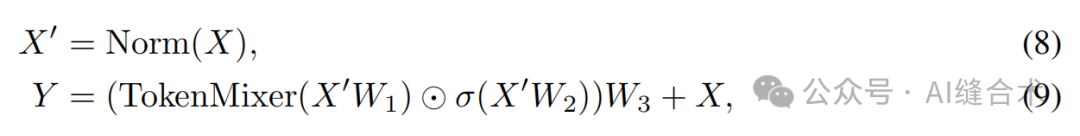
4. 线性变换:将激活后的结果与另一个可学习的权重矩阵W3进行点乘操作,得到最终的输出Y。
5. 残差连接:最后,将原始输入X与经过上述步骤处理后的输出Y相加,形成最终的输出。
算法:

四、实验分析
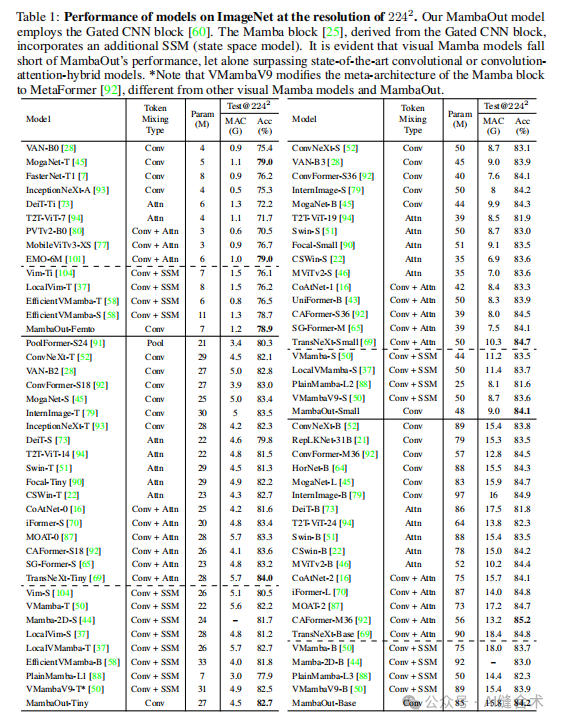
1. 图像分类实验
实验设置:在ImageNet数据集上进行图像分类实验,使用DeiT训练方案,数据增强包括随机裁剪、水平翻转、RandAugment、Mixup、CutMix、随机擦除和颜色抖动。训练使用AdamW优化器,学习率缩放规则为lr = 1e-3,批量大小设置为4096。
实验结果:MambaOut模型在不包含SSM的情况下,性能超过了包含SSM的视觉Mamba模型。例如,MambaOut-Small模型在ImageNet上达到了84.1%的top-1准确率,比LocalVMamba-S模型高出0.4%,而所需的MACs仅为后者的79%。这些结果支持了MambaOut模型在图像分类任务中不需要SSM的假设。
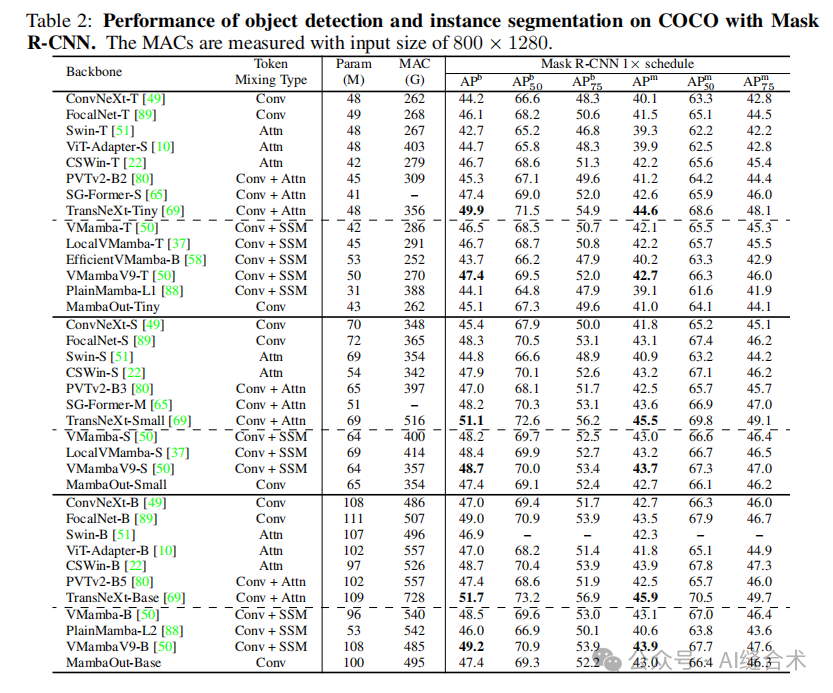
2. 对象检测与实例分割实验
实验设置:在COCO数据集上进行对象检测和实例分割实验,使用Mask R-CNN作为检测框架,模型初始化权重来自ImageNet预训练。训练遵循标准的1×训练计划,图像尺寸调整为800×1280。
实验结果:MambaOut模型在COCO数据集上能够超越一些视觉Mamba模型,但在与最先进的视觉Mamba模型,如VMamba和LocalVMamba相比,仍然存在性能差距。例如,MambaOut-Tiny作为Mask R-CNN的backbone时,其性能比VMamba-T模型低1.4 APb和1.1 APm。
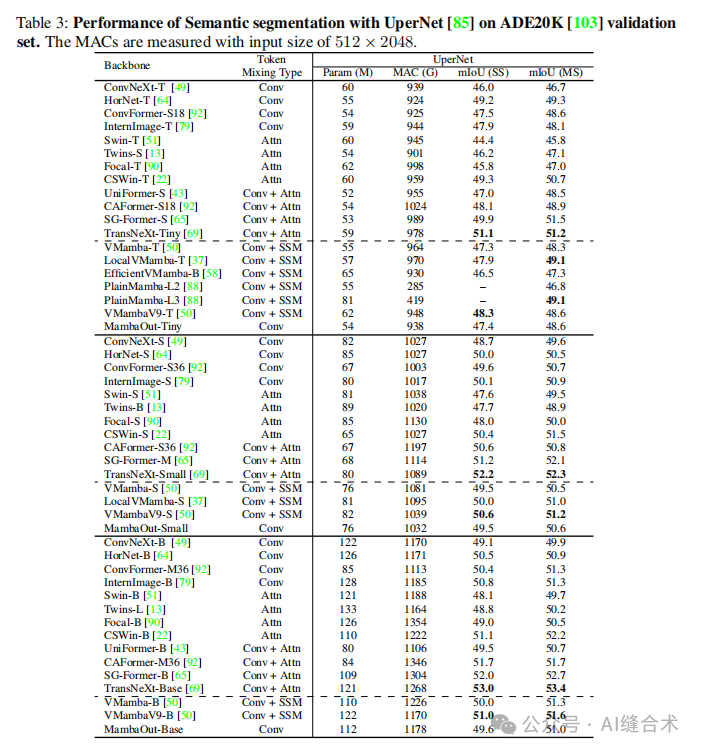
3. 语义分割实验
实验设置:在ADE20K数据集上进行语义分割实验,使用UperNet作为分割框架,模型同样初始化权重来自ImageNet预训练。训练使用AdamW优化器,学习率为0.0001,批量大小为16,迭代次数为160,000。
实验结果:MambaOut模型在ADE20K数据集上的表现趋势与COCO数据集上的对象检测相似。MambaOut能够超越一些视觉Mamba模型,但无法匹敌最先进的视觉Mamba模型。例如,LocalVMamba-T模型在单尺度和多尺度评估中均比MambaOut-Tiny高出0.5 mIoU。
五、代码
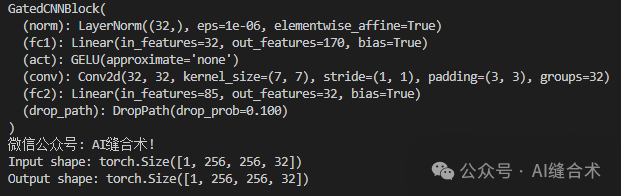
以下是正确缩进后的代码:
```python
from functools import partial
import torch
import torch.nn as nn
from timm.models.layers import trunc_normal_, DropPath
class GatedCNNBlock(nn.Module):
r"""
Our implementation of Gated CNN Block: https://arxiv.org/pdf/1612.08083
Args:
Conv_ratio: 控制进行深度卷积的通道数。对部分通道进行卷积可以提高实际效率。
部分通道的想法来自 ShuffleNet V2 (https://arxiv.org/abs/1807.11164) 也被
InceptionNeXt (https://arxiv.org/abs/2303.16900) 和 FasterNet (https://arxiv.org/abs/2303.03667) 使用。
"""
def __init__(self, dim, expansion_ratio=8/3, kernel_size=7, conv_ratio=1.0,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
act_layer=nn.GELU,
drop_path=0., **kwargs):
super().__init__()
self.norm = norm_layer(dim)
hidden = int(expansion_ratio * dim)
self.fc1 = nn.Linear(dim, hidden * 2)
self.act = act_layer()
conv_channels = int(conv_ratio * dim)
self.split_indices = (hidden, hidden - conv_channels, conv_channels)
self.conv = nn.Conv2d(conv_channels, conv_channels, kernel_size=kernel_size, padding=kernel_size//2, groups=conv_channels)
self.fc2 = nn.Linear(hidden, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
shortcut = x # [B, H, W, C]
x = self.norm(x)
g, i, c = torch.split(self.fc1(x), self.split_indices, dim=-1)
c = c.permute(0, 3, 1, 2) # [B, H, W, C] -> [B, C, H, W]
c = self.conv(c)
c = c.permute(0, 2, 3, 1) # [B, C, H, W] -> [B, H, W, C]
x = self.fc2(self.act(g) * torch.cat((i, c), dim=-1))
x = self.drop_path(x)
return x + shortcut
if __name__ == "__main__":
batch_size = 1 # Batch size
channels = 32 # 输入通道数
height = 256 # 输入图像高度
width = 256 # 输入图像宽度
# 创建一个模拟输入张量,形状为 (batch_size, height, width, channels)
x = torch.randn(batch_size, height, width, channels)
# 初始化 GatedCNNBlock 模块
model = GatedCNNBlock(dim=channels, expansion_ratio=8/3, kernel_size=7, conv_ratio=1.0, drop_path=0.1)
print(model)
print("微信公众号: AI缝合术!")
# 前向传播
output = model(x)
# 打印输入和输出张量的形状
print(f"Input shape: {x.shape}")
print(f"Output shape: {output.shape}")
```运行结果
便捷下载
https://github.com/AIFengheshu/Plug-play-modules
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1306
1306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









