







文章目录
论文阅读 | CVPR | MambaOut:视觉任务真的需要 Mamba 吗?
题目:MambaOut: Do We Really Need Mamba for Vision?
会议:IEEE Conference on Computer Vision and Pattern Recognition(CVPR)
论文:https://doi.org/10.48550/arXiv.2405.07992
代码:https://github.com/yuweihao/MambaOut?tab=readme-ov-file
年份:2025

摘要
提出MambaOut模型:
- 与卷积模型和基于注意力的模型相比,Mamba 在视觉任务上的表现往往不尽人意。
- 结论:Mamba非常适合具有长序列和自回归特性的任务。
- 对于视觉任务而言:
图像分类任务并不具备这两个特性(长序列和自回归特性),因此假设 Mamba对于该任务并非必需;
检测和分割任务虽然不是自回归的,但具有长序列特性; - 构建名为 MambaOut 的模型,这些模型通过堆叠 Mamba块并去除其核心令牌混合器 SSM 得到。

图 1(a)门控卷积神经网络(Gated CNN)和Mamba 模块的架构(省略了归一化层和残差连接)。Mamba模块在门控卷积神经网络的基础上增加了一个状态空间模型(SSM)从而进行了扩展。对于ImageNet上的图像分类任务来说,状态空间模型并非是必需的。堆叠门控卷积神经网络模块来构建一系列名为MambaOut的模型。
- MambaOut 模型在 ImageNet 图像分类任务上超越了所有视觉 Mamba 模型,这表明 Mamba 对于该任务确实并非必要。
引言
-
本文从概念上总结出 Mamba 非常适合具有两个关键特性的任务:长序列和自回归特性。 这是由于 SSM 固有的 RNN机制(详见图 2 和图 3 的解释)。
-
文中提出,具备这长序列和自回归的视觉任务并不多:
以 ImageNet图像分类任务为例,它既不符合长序列特性,也不符合自回归特性;
COCO 数据集上的目标检测与实例分割任务与ADE20K数据集上的语义分割任务,仅符合长序列特性。- 注释1:自回归特性要求每个令牌仅从前面的令牌和当前令牌聚合信息,这种令牌混合方式被称为因果模式(见图 2 (a))。

- 注释1:自回归特性要求每个令牌仅从前面的令牌和当前令牌聚合信息,这种令牌混合方式被称为因果模式(见图 2 (a))。
图 2:从内存角度展示因果注意力机制和类循环神经网络(RNN)模型的机制示意图,其中 x i x_i xi 表示第i步的输入令牌。(a) 因果注意力将前面所有令牌的键 k k k 和值 v v v 存储为内存。通过不断添加当前令牌的键和值来更新内存,因此这种内存是无损的,但缺点是随着序列变长,整合旧内存和当前令牌的计算复杂度会增加。因此,注意力机制能有效地处理短序列,但在处理长序列时可能会遇到困难。(b) 相比之下,类 RNN 模型将前面的令牌压缩为固定大小的隐藏状态 h h h,以此作为内存。这种固定大小意味着 RNN 的内存本质上是有损的,无法直接与注意力模型的无损内存容量相媲美。尽管如此,类 RNN 模型在处理长序列时可以展现出明显的优势,因为无论序列长度如何,将旧内存与当前输入合并的复杂度保持不变。
-
文中提出,所有视觉识别任务都属于理解范畴,而非生成范畴,这意味着模型可以一次性看到整个图像。 因此,在视觉识别模型的令牌混合过程中施加额外的因果约束可能会导致性能下降(见图 2 (b))。
-
基于上述概念性讨论,我们提出以下两个假设:
-
假设 1:由于 ImageNet 图像分类任务既不符合长序列特性,也不符合自回归特性,因此 SSM 对于该任务并非必要。
-
假设 2:虽然目标检测与实例分割任务以及语义分割任务不具有自回归特性,但它们符合长序列特性,因此 SSM 可能对这些任务具有潜在益处。
-
-
为了通过实验验证假设,开发了一系列名为 MambaOut 的模型,这些模型通过堆叠门控卷积神经网络(Gated CNN) [18] 块构建而成。Gated CNN 块和 Mamba 块的关键区别在于是否存在 SSM,如图 1 (a) 所示。
-
实验结果表明,更为简单的 MambaOut 模型在实际应用中已经超越了视觉 Mamba 模型的性能,这反过来验证了我们的假设 1。

图 1 (b) 在 ImageNet 图像分类任务上,MambaOut 的性能优于视觉 Mamba 模型,例如 Vision Mamba 、VMamba 和 PlainMamba 。
- 还通过实验结果表明,在检测和分割任务中,MambaOut 的性能不及当前最先进的视觉 Mamba 模型,这凸显了 SSM 在这些任务中的潜力,有效地验证了我们的假设 2。
创新点
本文的贡献主要体现在三个方面:
- 第一,分析了 SSM 类 RNN 的机制,从概念上得出 Mamba 适合具有长序列和自回归特性任务的结论。
- 第二,研究了视觉任务的特性,并假设由于 ImageNet 图像分类任务不满足上述两个特性,因此 SSM对于该任务并非必要;而对于检测和分割任务,尽管它们不具有自回归特性,但由于符合长序列特性,探索 SSM 在这些任务中的潜力仍然具有价值。
- 第三,我们开发了一系列基于 Gated CNN 块但不含 SSM 的 MambaOut 模型。它很可能成为未来视觉 Mamba模型研究的自然基线。
概念讨论
-
Mamba 的令牌混合器是SSM ( 选择性状态空间模型 ) ,它定义了四个与输入相关的参数 ( Δ , A , B , C ) (Δ,A,B,C) (Δ,A,B,C),并通过以下公式将它们转换为 ( A ‾ , B ‾ , C ) ( \overline{A},\overline{B} ,C) (A,B,C):
A ‾ = exp ( Δ A ) B ‾ = ( Δ A ) − 1 ( exp ( Δ A ) − I ) ⋅ Δ B (1) \overline{A} = \exp(\Delta A)\tag{1} \\\overline{B}=(\Delta A)^{-1}(\exp(\Delta A)-I)\cdot\Delta B A=exp(ΔA)B=(ΔA)−1(exp(ΔA)−I)⋅ΔB(1)
-
状态空间模型(SSM)的序列到序列转换可以用以下公式表示:
h t = A ‾ h t − 1 + B ‾ x t (2) h_{t}=\overline{A}h_{t - 1}+\overline{B}x_{t}\tag{2} ht=Aht−1+Bxt(2)
y t = C h t (3) y_{t}=Ch_{t}\tag{3} yt=Cht(3)
其中,t表示当前时刻,表示当前时刻的输入,表示当前时刻的隐藏状态,表示当前时刻的输出。
公式
(
2
)
(2)
(2)的递归特性将类循环神经网络(RNN-like)的状态空间模型与因果注意力机制(Causal attention)区分开,详情见图2。

图 2:从内存角度展示因果注意力机制和类循环神经网络(RNN)模型的机制示意图,其中 x i x_i xi 表示第i步的输入令牌。(a) 因果注意力将前面所有令牌的键 k k k 和值 v v v 存储为内存。通过不断添加当前令牌的键和值来更新内存,因此这种内存是无损的,但缺点是随着序列变长,整合旧内存和当前令牌的计算复杂度会增加。因此,注意力机制能有效地处理短序列,但在处理长序列时可能会遇到困难。(b) 相比之下,类 RNN 模型将前面的令牌压缩为固定大小的隐藏状态 h h h,以此作为内存。这种固定大小意味着 RNN 的内存本质上是有损的,无法直接与注意力模型的无损内存容量相媲美。尽管如此,类 RNN 模型在处理长序列时可以展现出明显的优势,因为无论序列长度如何,将旧内存与当前输入合并的复杂度保持不变。
- 隐藏状态 h h h 可以看作是一个固定大小的内存,用于存储所有历史信息。通过公式 ( 2 ) (2) (2),这个内存不断更新,同时保持大小不变。固定大小意味着 内存必然存在信息损失 ,但它 确保了将内存与当前输入进行整合的计算复杂度保持不变。
- 相反,因果注意力 (Causal attention) 将前面所有令牌的键和值存储为其内存,随着新输入的加入,通过添加当前令牌的键和值来扩展内存。这种内存 理论上是无损的。 然而,随着输入令牌的增加,内存大小不断增长,从而增加了将内存与当前输入进行整合的复杂度。
- 由于 SSM 的内存本质上是有损的,从逻辑上讲,它不如注意力的无损内存。因此,Mamba 在处理短序列时无法展现其优势,而注意力在短序列处理方面表现出色。
- 在涉及长序列的场景中,注意力由于其二次复杂度会出现性能下降。 在这种情况下,Mamba 在将内存与当前输入进行整合时的效率优势就会凸显出来,从而能够流畅地处理长序列。因此,Mamba 特别适合处理长序列。

图 3:(a) 两种令牌混合模式。对于总共 T T T 个令牌,全可见模式允许令牌 t t t 聚合来自所有令牌的输入,即 { x i } i = 1 T \{x_i\}_{i=1}^{T} {xi}i=1T,来计算其输出。相比之下,因果模式限制令牌 t t t 仅聚合来自前面和当前令牌的输入 { x i } i = 1 t \{x_i\}_{i=1}^{t} {xi}i=1t。 默认情况下,注意力机制以全可见模式运行,但可以通过因果注意力掩码调整为因果模式。类似 RNN 的模型,如 Mamba 的状态空间模型(SSM),由于其循环特性,本质上以因果模式运行。(b) 我们将视觉 Transformer(ViT)的注意力机制从全可见模式修改为因果模式,并观察到在 ImageNet 上的性能下降,这表明因果混合对于理解任务来说并非必要。
- 【因果模式】: 状态空间模型(SSM)的递归特性公式
(
2
)
(2)
(2) 使Mamba能够高效处理长序列,但它也带来了一个显著的限制制:
h
t
h_t
ht 只能访问前一个和当前时间步的信息。
如图3(下图)所示,这种令牌混合方式被称为因果模式,可以用公式表示为:
y t = f ( x 1 , x 2 , . . . . . . , x t ) (4) y_t=f(x_1,x_2,......,x_t)\tag{4} yt=f(x1,x2,......,xt)(4)
其中, x t x_t xt 和 y t y_t yt 分别代表第 t t t 个令牌的输入和输出。由于其因果特性,这种模式非常适合自回归生成任务。
- 【全可见模式】:在这种模式下,每个令牌都可以聚合来自所有前序和后续令牌的信息。 这意味着每个令牌的输出取决于所有令牌的输入:
y t = f ( x 1 , x 2 , . . . . . . , x T ) (5) y_t=f(x_1,x_2,......,x_T)\tag{5} yt=f(x1,x2,......,xT)(5)
其中 T T T 表示令牌的总数。全可见模式适用于理解任务,在这类任务中,模型可以一次性访问所有输入。
Mamba到底适合处理什么样的任务?
Mamba 非常适合具有以下特性的任务:
- 特性 1:任务涉及长序列处理。
- 特性 2:任务需要因果令牌混合模式。
视觉任务具有很长的序列吗?
考虑一个具有常见多层感知机(MLP)比例为 4 的Transformer模块;假设其输入 X ∈ R L × D X \in \mathbb{R}^{L×D} X∈RL×D,那么该模块的浮点运算次数(FLOPs)可以计算为:
FLOPs = 24 D 2 L + 4 D L 2 \text{FLOPs} = 24D^{2}L + 4DL^{2} FLOPs=24D2L+4DL2
由此推导出公式:
r L = 4 D L 2 24 D 2 L = L 6 D r_{L}=\frac{4DL^{2}}{24D^{2}L}=\frac{L}{6D} rL=24D2L4DL2=6DL
如果 L > 6 D L > 6D L>6D,那么关于 L L L的二次项的计算量就会超过一次项的计算量。这提供了一个简单的衡量标准,用于判断该任务是否涉及长序列。
-
例如,在ViT - S模型中有384个通道时,阈值 τ s m a l l = 6 × 384 = 2304 \tau_{small}=6\times384 = 2304 τsmall=6×384=2304;而对于ViT - B模型中768个通道的情况, τ b a s e = 6 × 768 = 4608 \tau_{base}=6\times768 = 4608 τbase=6×768=4608。
-
对于ImageNet数据集上的图像分类任务,典型的输入图像尺寸为 224 × 224 224×224 224×224,当图像块(patch)尺寸为 16 × 16 16×16 16×16时,会得到 14 × 14 = 196 14×14 = 196 14×14=196个图像块(令牌)。显然, 196 196 196远小于 τ s m a l l \tau_{small} τsmall和 τ b a s e \tau_{base} τbase, 这表明ImageNet上的图像分类任务不能算作长序列任务。
-
对于 COCO 数据集上的目标检测与实例分割任务,推理图像尺寸为 800 × 1280 800\times1280 800×1280;对于 ADE20K 数据集上的语义分割任务,推理图像尺寸为 512 × 2048 512\times2048 512×2048。当图像块(patch)尺寸为 16 × 16 16\times16 16×16时,令牌数量大约为 4000 4000 4000个。
-
由于 4000 > τ s m a l l = 6 × 384 = 2304 4000>\tau_{small}=6\times384 = 2304 4000>τsmall=6×384=2304且 4000 > τ b a s e = 6 × 768 = 4608 4000>\tau_{base}=6\times768 = 4608 4000>τbase=6×768=4608,所以 COCO 数据集上的目标检测任务和 ADE20K 数据集上的语义分割任务都可被视为长序列任务。
如何计算Transformer 模块的浮点运算次数(FLOPs)?
定义
F L O P s FLOPs FLOPs 定义:1 次乘法和 1 次加法均计为 1 次 F L O P FLOP FLOP。
一个 D D D维行向量与一个 D D D维列向量相乘的情况

上图展示了一个
D
D
D维行向量与一个
D
D
D维列向量相乘的情况。
一个
D
D
D维行向量与一个
D
D
D维列向量相乘得到一个结果元素,这需要进行乘法和加法运算,总共的浮点运算次数
(
F
L
O
P
s
)
(FLOPs)
(FLOPs)为
2
D
2D
2D
所以在 这种情况下,1个结果元素需要
2
D
2D
2D次浮点运算。因此
L
×
L
L×L
L×L个输出元素所需的浮点运算次数是:
L
×
L
×
D
=
2
D
L
2
L\times L\times D = 2DL^{2}
L×L×D=2DL2
计算输入

假设输入
X
∈
R
L
×
D
X \in \mathbb{R}^{L \times D}
X∈RL×D,其中
L
L
L表示序列长度(token 数量),
D
D
D表示通道数。查询(queries)、键(keys)和值(values)由
Q
=
X
W
Q
Q = XW_Q
Q=XWQ
K
=
X
W
K
K = XW_K
K=XWK
V
=
X
W
V
V = XW_V
V=XWV
计算得到,且计算中涉及的参数
Q
,
K
,
V
∈
R
L
×
D
Q, K, V \in \mathbb{R}^{L \times D}
Q,K,V∈RL×D以及
W
Q
,
W
K
,
W
V
∈
R
D
×
D
W_Q, W_K, W_V \in \mathbb{R}^{D \times D}
WQ,WK,WV∈RD×D是可学习的。
计算 Q , K , V Q, K, V Q,K,V是相似的,我们举其中一个例子。由于一个输出元素需要 2 D 2D 2D次运算,所以 L × D L \times D L×D输出元素需要 L × D × 2 D = 2 D 2 L L \times D \times 2D = 2D^{2}L L×D×2D=2D2L。计算 K K K、 V V V和计算 Q Q Q类似。
因此总的浮点运算次数是: FLOP Q K V = 3 × 2 D L 2 = 6 D 2 L \text{FLOP}_{QKV} = 3 \times 2DL^{2} = 6D^{2}L FLOPQKV=3×2DL2=6D2L。
计算注意力图
A = Q × K T A =Q ×K^{T} A=Q×KT ,其中 A ∈ R L × L A \in \mathbb{R}^{L ×L} A∈RL×L 是注意力图

一个输出元素需要
2
D
2D
2D 次浮点运算,因此
L
2
L^{2}
L2个输出元素需要
F
L
O
P
A
=
L
2
×
2
D
=
2
D
L
2
F L O P_A=L^{2} ×2 D=2 D L^{2}
FLOPA=L2×2D=2DL2
接下来,使用注意力图对值进行聚合以获得新的值,
V
′
=
A
V
V' = A V
V′=AV

其中, V ′ ∈ R L × D V' \in \mathbb{R}^{L × D} V′∈RL×D 是新的值。
一个输出元素需要 2 L 2L 2L 次浮点运算 ( F L O P S ) (FLOPS) (FLOPS),因此 L × D L × D L×D个输出元素需要的浮点运算次数 F L O P V ′ = L × D × 2 L = 2 D L 2 FLOP_{V'}=L × D × 2L = 2DL^{2} FLOPV′=L×D×2L=2DL2
线性变换
接下来,使用一个线性变换对
V
′
V'
V′ 进行转换,以获得注意力模块的最终输出
Y
=
V
′
W
O
Y = V'W_{O}
Y=V′WO
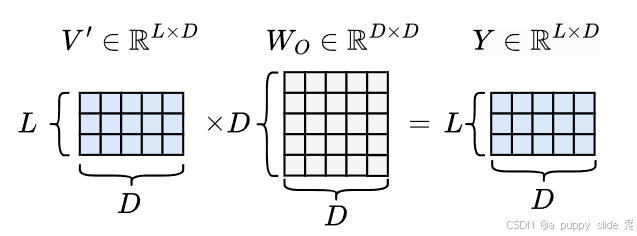
其中, W O ∈ R D × D W_{O} \in \mathbb{R}^{D × D} WO∈RD×D 是可学习参数, Y ∈ R L × D Y \in \mathbb{R}^{L × D} Y∈RL×D 是注意力模块的输出。
一个输出元素需要
2
D
2D
2D次运算,所以
L
×
D
L \times D
L×D输出元素需要
F
L
O
P
s
Y
=
L
×
D
×
2
D
=
2
D
2
L
FLOPs_Y=L \times D \times 2D = 2D^{2}L
FLOPsY=L×D×2D=2D2L
多层感知机

在注意力模块之后,下一个模块是多层感知机(MLP),其可以表示为:
Z
=
σ
(
Y
W
1
)
Z
′
=
Z
W
2
Z = \sigma(YW_1)\\ Z' = ZW_2
Z=σ(YW1)Z′=ZW2
其中
W
1
∈
R
D
×
4
D
W_1\in\mathbb{R}^{D\times 4D}
W1∈RD×4D 且
W
2
∈
R
4
D
×
D
W_2\in\mathbb{R}^{4D\times D}
W2∈R4D×D 是可学习参数,默认的MLP扩展比
(
r
)
(r)
(r) 为4。
σ
(
⋅
)
\sigma(\cdot)
σ(⋅) 是激活函数,其浮点运算次数
(
F
L
O
P
s
)
(FLOPs)
(FLOPs)可忽略不计。
1个输出元素需要
2
D
2D
2D 次浮点运算
(
F
L
O
P
s
)
(FLOPs)
(FLOPs),所以
L
×
4
D
L\times 4D
L×4D 个输出元素需要的浮点运算次数(FLOPs)为:
FLOP
Z
=
L
×
4
D
×
2
D
=
8
D
2
L
\text{FLOP}_Z = L\times 4D\times 2D = 8D^2L
FLOPZ=L×4D×2D=8D2L

1个输出元素需要
8
D
8D
8D 次浮点运算
(
F
L
O
P
s
)
(FLOPs)
(FLOPs),所以
L
×
D
L\times D
L×D 个输出元素需要的浮点运算次数(FLOPs)为:
FLOP
Z
′
=
L
×
D
×
8
D
=
8
D
2
L
\text{FLOP}_{Z'} = L\times D\times 8D = 8D^2L
FLOPZ′=L×D×8D=8D2L
因此,对于一个Transformer模型,总浮点运算次数(FLOPs)为:
FLOP
total
=
FLOP
QKV
+
FLOP
1
+
FLOP
2
+
FLOP
V
′
+
FLOP
Z
+
FLOP
Z
′
=
6
D
2
L
+
2
D
2
L
+
2
D
2
L
+
2
D
2
L
+
8
D
2
L
+
8
D
2
L
=
24
D
2
L
+
4
D
L
2
\text{FLOP}_{\text{total}}=\text{FLOP}_{\text{QKV}}+\text{FLOP}_{1}+\text{FLOP}_{2}+\text{FLOP}_{V'}+\text{FLOP}_{Z}+\text{FLOP}_{Z'}\\ = 6D^2L + 2D^2L+2D^2L + 2D^2L+8D^2L+8D^2L\\ = 24D^2L + 4DL^2
FLOPtotal=FLOPQKV+FLOP1+FLOP2+FLOPV′+FLOPZ+FLOPZ′=6D2L+2D2L+2D2L+2D2L+8D2L+8D2L=24D2L+4DL2


















 621
621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









