






本文来源公众号“AI算法之道”,仅用于学术分享,侵权删,干货满满。
原文链接:DeepSeek-R1论文解读
01 引言
近年来,人工智能(AI)领域发展迅速,大型语言模型(LLM)为通用人工智能(AGI)铺平了道路。OpenAI 的 o1 是一个杰出的模型,它引入了创新的推理扩展技术,大大增强了推理能力。然而,它仍然是闭源的。

今天,我们将深入探讨 DeepSeek 推出 DeepSeek-R1 的开创性研究论文。这篇题为《DeepSeek-R1: Incentivizing Reasoning Capability in Large Language Models via Reinforcement Learning》的论文介绍了一个最先进的开源推理模型,以及使用大规模强化学习技术训练此类模型的详细方法。
闲话少说,我们直接开始吧!
02 回顾LLM训练过程
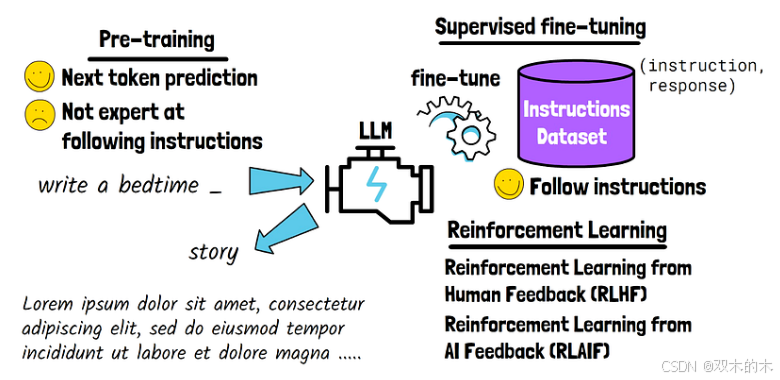
深入探讨论文本身之前,让我们简要回顾一下LLM的训练过程。一般来说,LLM的训练过程主要分为三个阶段:
LLM的一般训练过程
-
Pre-training:在这一阶段,LLM 在大量文本和代码上进行预训练,以学习通用知识。这一步骤有助于模型熟练预测序列中的下一个Token。例如,如果输入 "写一个睡前_",模型可以用一个合理的词来完成,如 "故事"。但是,经过预训练后,模型在遵循人类指令方面仍然很吃力。下一阶段将解决这一问题。
-
Supervised Fine-tuning: 在这一阶段,模型在指令数据集上进行微调。数据集中的每个样本都由指令-响应对组成,其中响应被用作标签。经过这一阶段后,模型就能更好地遵循指令。
-
Reinforcement Learning: 利用反馈进一步改进 LLM。从人类反馈中强化学习(RLHF)就是一种强大的方法,它根据人类反馈对模型进行训练。收集大规模、高质量的人类反馈,尤其是复杂任务的反馈,是一项挑战。因此,另一种常见的方法是人工智能反馈强化学习(RLAIF),即由人工智能模型提供反馈。要使 RLAIF 有效发挥作用,需要一个能力很强的模型来提供准确的反馈。
03 DeepSeek R1-Zero模型
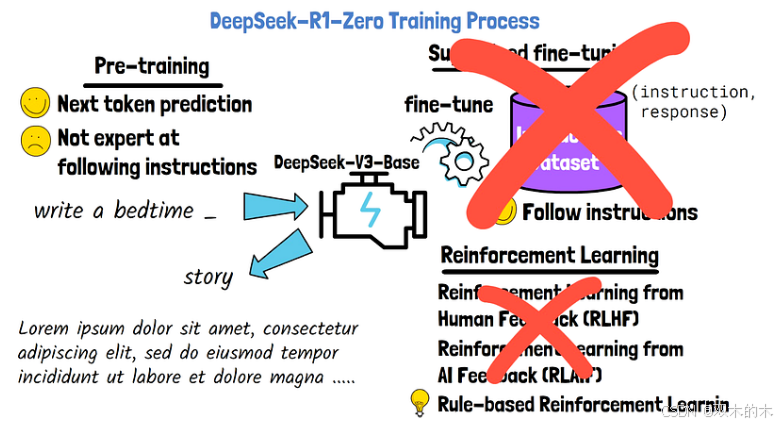
我们今天分享的这篇论文取消或部分取消了监督微调阶段。
在后期训练中仅使用 RL 训练 DeepSeek-R1-Zero,不使用 SFT
具体来说,为了训练论文中提出的第一个模型 DeepSeek-R1-Zero,我们从一个名为 DeepSeek-V3-Base 的预训练模型开始,该模型有 6710 亿个参数。我们完全省略了监督微调阶段。为了大规模运行强化学习,我们采用了一种基于规则的强化学习方法,而不是使用人或人工智能反馈的标准强化学习。
04 基于规则的强化学习
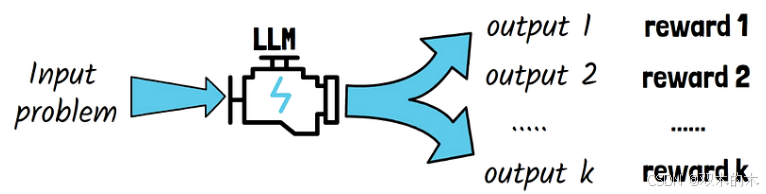
论文中所使用的强化学习方法称为组相对策略优化(GRPO),由 DeepSeek 自主开发。
GRPO 对给定输出的多个输出进行采样,并指示模型优先选择最佳输出,对每个输出使用奖励
给定一个要训练的模型和一个输入问题,将输入送入模型,并对一组输出进行采样。每个输出包括一个推理过程和一个答案。GRPO 方法观察这些采样输出,并使用预定义的规则计算每个输出的奖励,从而训练模型生成首选方案:
-
Accuracy: 一套规则可以计算出准确度奖励。例如,对于结果确定的数学问题,我们可以可靠地检查模型提供的最终答案是否正确。对于带有预定义测试用例的代码问题,编译器会根据测试用例生成反馈。
-
Format: 另一种规则是创建格式奖励。在论文中的下图中,我们可以看到模型是如何被指示做出回应的,其推理过程在标签内,答案也在标签内。格式奖励确保模型遵循这一格式。

这种基于规则的机制不使用神经模型来生成奖励,简化并降低了训练过程的成本,使其在大规模应用中变得可行。
05 DeepSeek R1-Zero性能
现在让我们来了解一下 DeepSeek-R1-Zero 模型的性能。
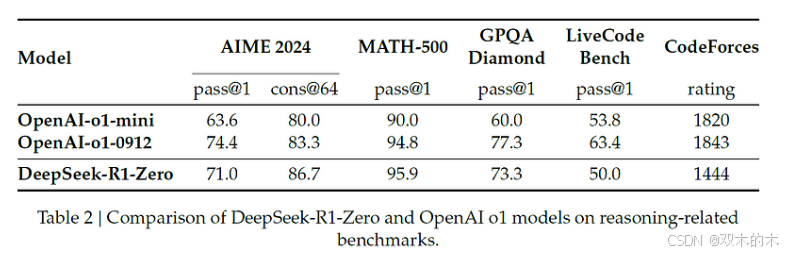
DeepSeek-R1-Zero 与 OpenAI o1 的性能比较
在论文的上表中,我们可以看到 DeepSeek-R1-Zero 和 OpenAI 的 o1 在推理相关基准上的比较。令人印象深刻的是,DeepSeek-R1-Zero 与 o1 不相上下,在某些情况下甚至超过了 o1。下面这幅引人入胜的图显示了在 AIME 数据集上测量的训练过程中的改进进展。值得注意的是,AIME 的平均 pass@1 分数大幅提高,从最初的 15.6% 跃升至令人印象深刻的 71.0%,达到了与 OpenAI 的 o1 不相上下的水平!
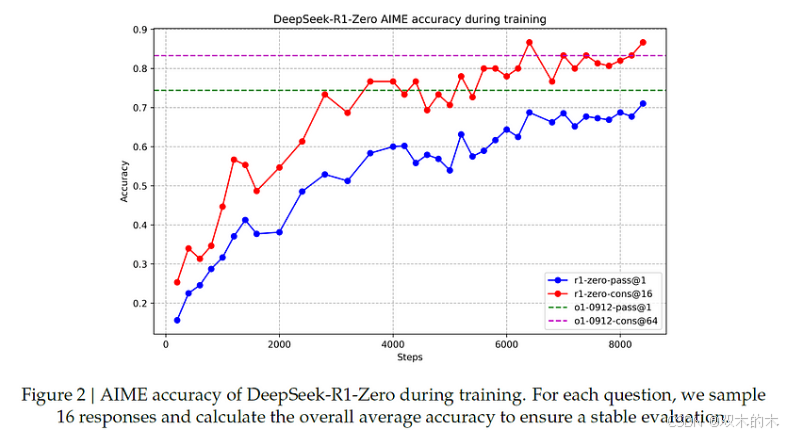
DeepSeek-R1-Zero 在训练期间的测试表现
06 DeepSeek R1-Zero的自我演化
本文的一个重要观点是模型的自我演化的过程,如下图所示。
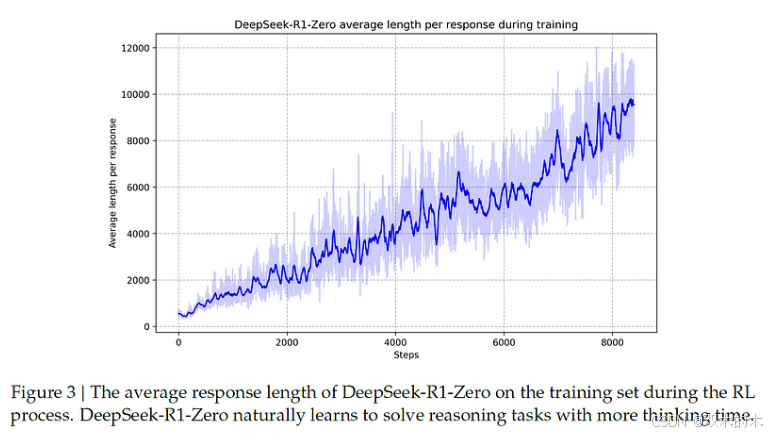
DeepSeek-R1-Zero 的自我演化过程
如图所示,x 轴表示训练步数,y 轴表示随着训练的进行,模型的响应长度会增加。通过强化学习,模型自然而然地学会了在解决推理任务时分配更多的思考时间。令人惊奇的是,这种情况的发生不需要任何外部训练调整。

如果以上还不够,论文中还提到了另一个有趣的现象,即 DeepSeek-R1-Zero 的 "啊哈时刻"。上图中的数学示例演示了这一现象。在给出一道数学题后,模型开始了推理过程。然而,到了一定程度,模型开始重新评估其解决方案。模型学会了重新评估其初始方法,并在必要时进行自我修正。这种非凡的能力是在强化学习训练过程中自然产生的。
07 为什么需要DeepSeek-R1 ?
既然 DeepSeek-R1-Zero 已经取得了显著成果,我们为什么还需要第二个模型呢?主要原因有两个:
-
可读性问题:DeepSeek-R1-Zero 的输出结果经常存在可读性差的问题。
-
语言一致性:在一个答复中经常混合使用多种语言。
上述情况使得 DeepSeek-R1-Zero 对用户不那么友好。有趣的是,一项消融研究表明,引导模型与一种语言保持一致会轻微损害其性能。与通常只使用一种语言的人类不同,模型通过使用多种语言学会了更好地表达自己,这一点令人着迷。
08 DeepSeek-R1的训练过程
为了解决这些问题,DeepSeek-R1采用了四个阶段的训练流程:
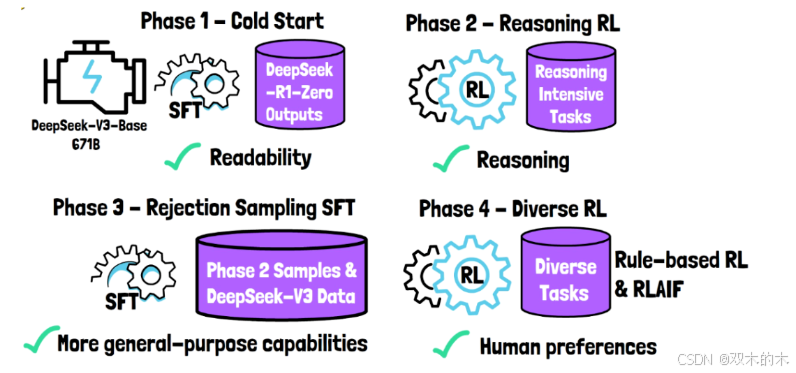
-
冷启动(第一阶段):从预训练模型DeepSeek-V3-Base开始,该模型在DeepSeek-R1-Zero收集的少量数据集上进行有监督的微调。这些结果经过验证,被认为是高质量且可读的。该数据集包含数千个样本,规模相对较小。在这样一个小而高质量的数据集上进行有监督的微调,有助于DeepSeek-R1缓解初始模型中观察到的可读性问题。
-
推理强化学习(第二阶段):这一阶段应用了与前一模型相同的大型强化学习,以增强模型的推理能力。具体而言,在编程、数学、科学和逻辑推理等任务中,可以定义明确的解决方案来为强化学习过程设定奖励规则。
-
拒绝采样和有监督微调(第三阶段):在这一阶段,使用第二阶段的模型生成大量样本。通过拒绝采样,仅保留正确且可读的样本。此外,生成式奖励模型DeepSeek-V3用于决定哪些样本应该保留。DeepSeek-V3的部分训练数据也被纳入这一阶段。然后,模型在这个数据集上使用有监督微调进行训练。该数据集不仅包括推理导向的问题,还增强了模型在更多领域的功能。
-
多样化强化学习阶段(第四阶段):这一最终阶段包含多样化的任务。对于允许使用规则的任务,如数学,采用基于规则的奖励。对于其他任务,则由一个大型语言模型(LLM)提供反馈,以使模型与人类偏好保持一致。
此外,还利用第三阶段构建的数据集对各种较小的开源模型进行了蒸馏,提供了具有高推理能力的更小替代模型。
09 DeepSeek-R1的性能表现
最后,我们通过强调DeepSeek-R1(与OpenAI的o1模型相比)所取得的显著成果来结束本文。
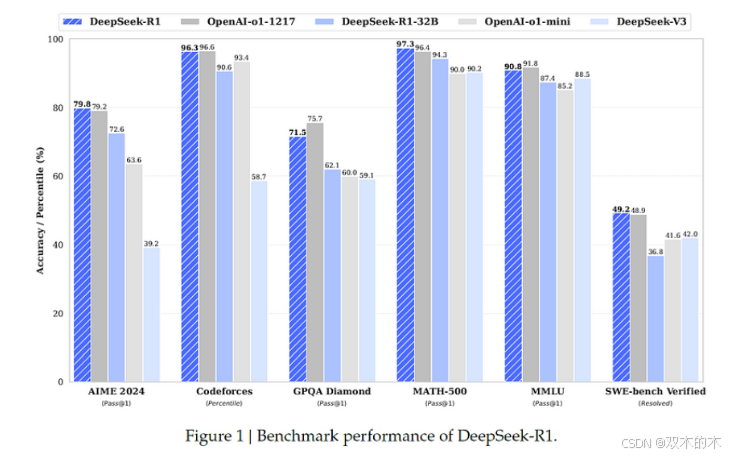
DeepSeek-R1 与 OpenAI o1的性能比较
论文中的上图显示,DeepSeek-R1不仅与o1相当,而且在某些基准测试中还超越了o1。
此外,经过蒸馏的320亿参数模型也展现出了令人印象深刻的性能,使其成为一种具有高推理能力的可行的小型替代方案。
[相关参考]
论文:https://arxiv.org/abs/2501.12948
GitHub: https://github.com/deepseek-ai/DeepSeek-R1/tree/main
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 8370
8370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









