







知乎:木尧(已授权)
链接:https://zhuanlan.zhihu.com/p/20538667476
编辑:「深度学习自然语言处理」公众号
总览
最近在研究和复现 DeepSeek-R1(671B 参数 MoE,激活 37B 参数,128K 上下文的深度思考模型)论文,于是画了三张图来把整个论文核心内容总结一下,欢迎大家讨论!核心是三组模型:
一是纯强化学习(后文简称 RL)方案训的 DeepSeek-R1-Zero 验证技术方案可行,Reasoning 能力提升;
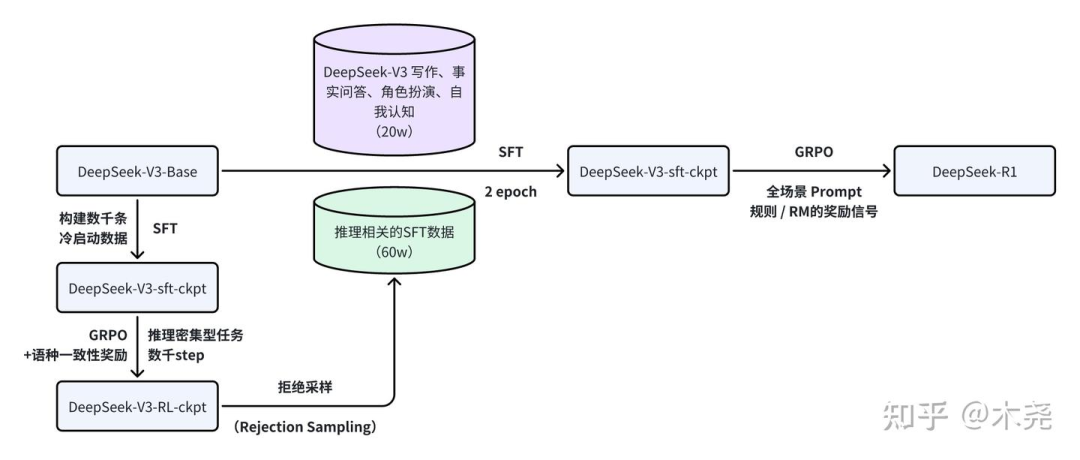
二是 80w 有监督微调(后文简称 SFT)+ 类似刚才 RL 方案训练的 DeepSeek-R1,能力对标 OpenAI o1;
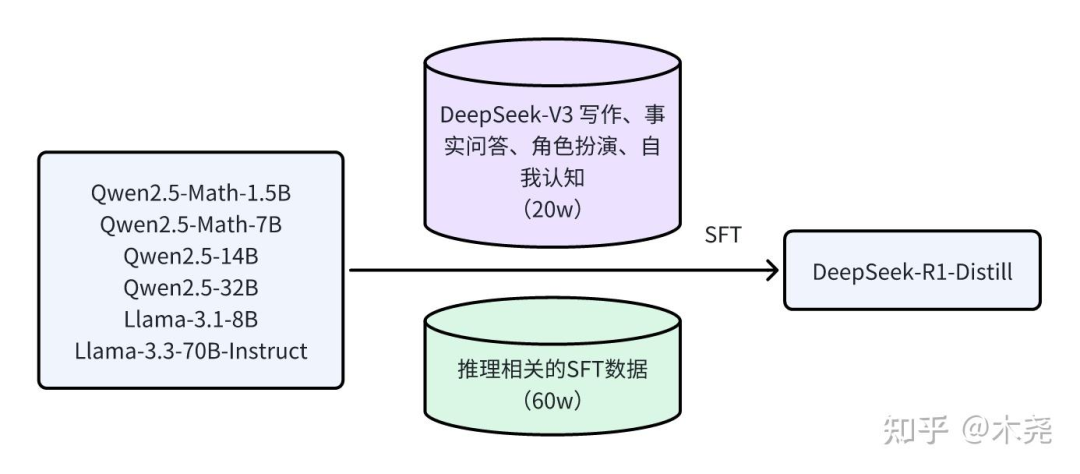
三是直接拿刚才 80w 对 Qwen/Llama 系列模型 SFT 蒸馏出来的小模型,能力对标 OpenAI o1-mini。
先上图!
分别展开三张图
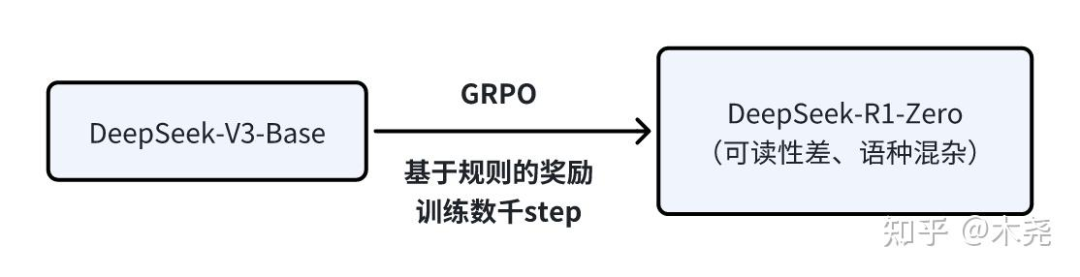
图一:DeepSeek-R1-Zero 训练
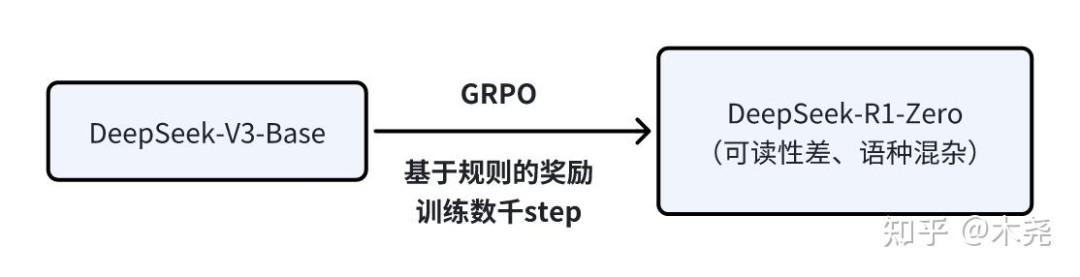
先说意义:DeepSeek-R1-Zero 首次通过纯 RL 而不用任何 SFT 激发 LLM 的推理能力,让模型自己探索解决复杂问题的 CoT,生成能自我验证(self-verification)、反思(reflection)的 long-CoT。
再看动机:RL在推理任务中已被证明具有显著的效果,然而之前的工作严重依赖于监督数据,收集耗时费力。所以能不能让 LLM 通过纯 RL 进行自我进化嘞
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









