






本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
https://arxiv.org/pdf/2412.16643
文章提出了一种名为TimeRAG的框架,通过将检索增强生成(Retrieval-Augmented Generation, RAG)引入时间序列预测的大型语言模型(Large Language Models, LLMs)中,以提高预测准确性。
TimeRAG框架从历史序列中构建时间序列知识库,使用动态时间规整(Dynamic Time Warping, DTW)作为距离度量,从知识库中检索与查询序列具有相似模式的参考序列,并将这些参考序列与预测查询结合为文本提示,输入到时间序列预测的LLM中。
论文出发点
时间序列预测在数据科学和机器学习研究中至关重要,广泛应用于金融市场分析、需求预测、天气预测等领域。
然而,现有的时间序列预测LLMs难以适应不同领域,且训练成本高昂,通常针对特定领域进行优化。
此外,由于LLMs的“幻觉”问题,它们可能会生成不准确的预测、异常值或与数据不符的模式,缺乏可解释性。
论文方法
方法概述
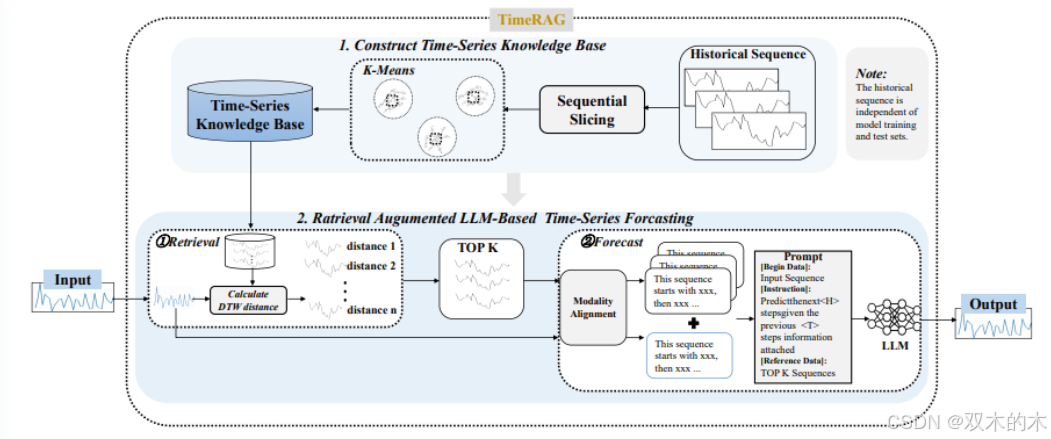
为了提升大型语言模型(LLMs)在时间序列预测任务中的性能,文章提出了一种名为 TimeRAG 的检索增强框架。该框架由两个主要组件构成:时间序列知识库(Time Series Knowledge Base, KB)(II-B部分)和 基于LLM的时间序列预测模型(II-C部分)。具体流程如下:
-
时间序列分割:首先,TimeRAG 通过滑动窗口将原始时间序列分割成多个子序列。
-
构建知识库:利用 K-means 聚类从训练集中提取具有代表性的子序列,构建时间序列知识库。
-
检索相似序列:给定时间序列预测查询,使用动态时间规整(Dynamic Time Warping, DTW)作为距离度量,从知识库中检索与查询序列具有相似波形和趋势的参考序列。DTW 的优势在于能够处理时间序列中的时间扭曲问题。
-
生成提示并预测:将输入查询和检索到的参考序列重新组合成自然语言提示,输入到 LLMs 中进行预测。
时间序列知识库
为了构建时间序列知识库,TimeRAG 采用以下步骤:

基于检索增强的LLM时间序列预测
尽管 LLMs 在时间序列预测中表现出色,但在处理未训练过的序列时,其预测准确性会下降。此外,LLMs 存在“遗忘”问题,可能导致预测准确性降低。为了解决这些问题,TimeRAG 引入了基于检索增强的LLM时间序列预测方法,分为两个阶段:

实验对比
实验设置
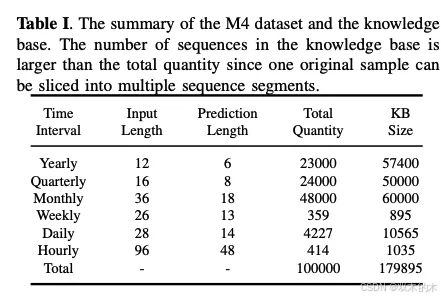
实验在 M4 基准数据集 上进行评估。M4 数据集广泛用于时间序列预测,包含来自金融、人口统计、市场营销等多个领域的数据,具有不同的时间采样频率(如年、季度、月、周、日、小时)。每个频率对应特定的预测范围和输入长度,支持对预测模型的全面评估。
采用以下三个广泛接受的指标来评估模型性能:
-
SMAPE(对称平均绝对百分比误差):衡量预测值与实际值之间的百分比误差。
-
MASE(平均绝对缩放误差):评估模型的预测准确性相对于朴素预测策略的表现,具有尺度独立性和鲁棒性。
-
OWA(整体加权平均):结合 SMAPE 和 MASE,提供对模型性能的综合评估。
将 TimeRAG 与多种最先进的时间序列模型进行比较,包括:
-
基于 Transformer 的模型:iTransformer、FEDformer、Pyraformer、Autoformer、Informer 和 Reformer。
-
其他竞争模型:Time-LLM、DLinear、TSMixer、MICN、FiLM 和 LightTS。
实验结果
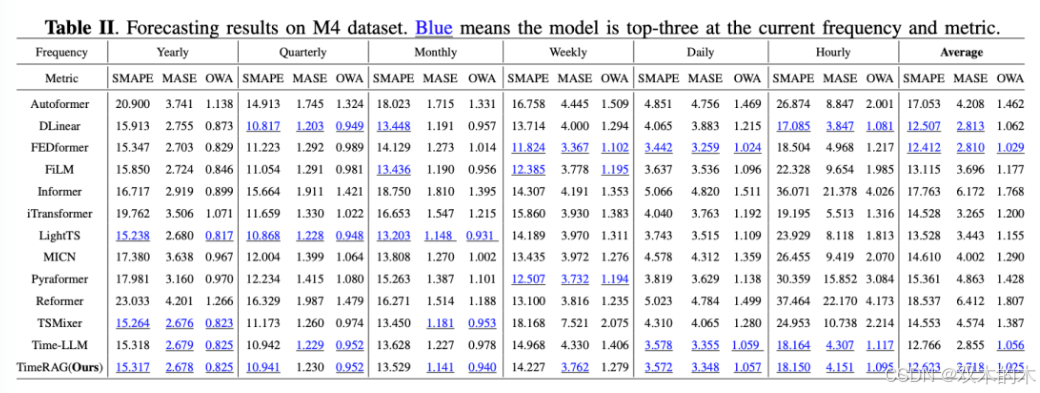
TimeRAG 与 Time-LLM 的比较:
-
TimeRAG 在预测准确性上显著优于未使用 RAG 的 Time-LLM。
-
平均而言,TimeRAG 在 SMAPE 上降低了 1.13%,在 MASE 上降低了 4.78%,在 OWA 上降低了 3.00%,整体提升了 2.97%。
-
在最佳情况下,TimeRAG 在“周”频率上的 SMAPE 降低了 0.74,MASE 提升了 13.12%。
TimeRAG 与其他 SOTA 模型的比较:
-
TimeRAG 在当前训练范式下,在 MASE 和 OWA 指标上表现最佳。
-
平均 MASE 得分为 2.72,是所有评估模型中的最低值,表明其预测准确性最高。
-
在 OWA 指标上,TimeRAG 以 1.03 的得分领先,其次是 FEDformer 和 Time-LLM。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1184
1184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









