 GhostRNN:精简RNN模型并提升性能
GhostRNN:精简RNN模型并提升性能







本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:GhostRNN:以低成本 Transformer Layer 实现 RNN 模型精简与性能提升 !

基于长程依赖建模的循环神经网络(RNNs)在各种语音任务中得到广泛应用,例如关键词检测(KWS)和语音增强(SE)。然而,由于低资源设备的功率和内存限制,需要高效的RNN模型用于实际应用。
在本文中,作者提出了一种高效的RNN架构GhostRNN,通过廉价操作减少隐藏状态冗余。
特别地,作者观察到在训练好的RNN模型中,隐藏状态的某些部分与其他部分相似,这表明特定RNN中的冗余性。
为了减少冗余并降低计算成本,作者提出首先生成几个内在状态,然后根据内在状态应用廉价操作生成鬼状态。
在KWS和SE任务上的实验表明,提出的GhostRNN在保持性能相似的同时,显著降低了内存使用率(约40%)和计算成本。
1 Introduction
近年来,随着神经网络的快速发展,在各种语音任务上取得了显著的改进。在这些神经网络中,RNNs,例如LSTMs [1] 或 GRUs [2],在低资源设备(如手机)上的各种语音相关任务中得到广泛应用,如 KWS [3, 4, 5] SE [6],自动语音识别 [7],声学回波消除 [8, 9],等,尽管它们的并行性不如Transformer [10]。
由于在边缘设备上部署AI模型的需求很高,这些设备具有有限的功率和内存,因此设计具有低计算成本且保持高性能的 efficient 模型是可取的。在这个方向上已经做出了多种努力。Dey 和 Salem [11] 提出了一种高效的 GRU 变体,通过调整门矩阵的计算方法来减少门矩阵的大小,例如,仅以隐藏状态作为输入来计算门向量。 [12] 提出的 Light-Gated-GRU (Li-GRU) 去除了重置门,并发展成一个单门 RNN。Amoh 和 Odame [13] 提出了一个嵌入的 Gaed Recurrent Unit,它只有一个门,具有单门机制。类似于 Li-GRU,Fanta 等 [14] 在他们提出的 SITGRU 中,摒弃了 GRU 的重置门,并用 Sigmoid 替换 Tanh 的激活函数。张等人 [15] 使用双门机制压缩 RNN 模型。尽管这些方法可以有效地减少模型的参数数量,但减少门矩阵的数量可能会损害对上下文信息的探索。
在这项工作中,作者在上述先前的研究中除了门控矩阵外,还实证观察到RNN模型隐藏状态中的冗余性。因此,作者提出要充分挖掘隐藏状态的冗余性来压缩RNN,这在语音任务中尚未被研究。特别是,作者考虑了RNN模型与SE任务,并分析了RNN层中的隐藏状态。
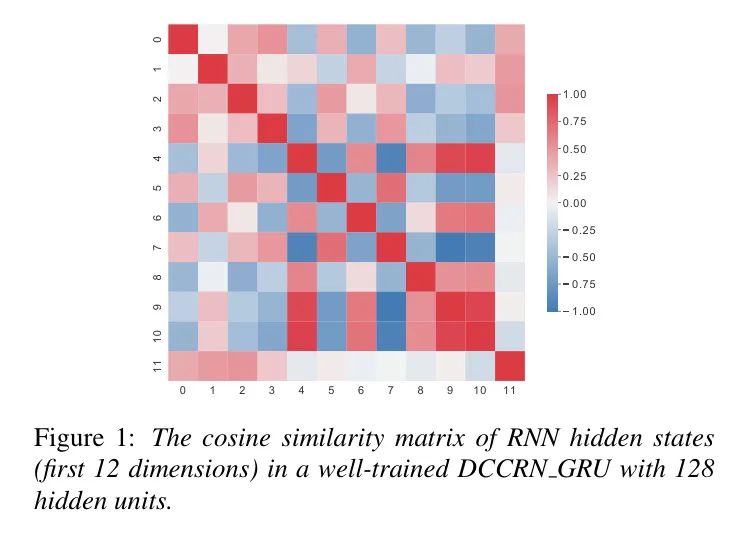
在经过n个时间步后,具有m个隐藏单元的隐藏状态的特征图可以表示为,第i个隐藏单元的特征图可以表示为。首先,作者对一个经过良好训练的DCCRN_GRU模型的隐藏状态特征图进行奇异值分解。作者发现只有半数奇异值可以达到主成分分析(PCA)的99%贡献率,这表明某些相对冗余。此外,如图1所示,作者计算了在不同索引处的余弦相似度,其中一些相似值相当大,表明高度相似性[16]。
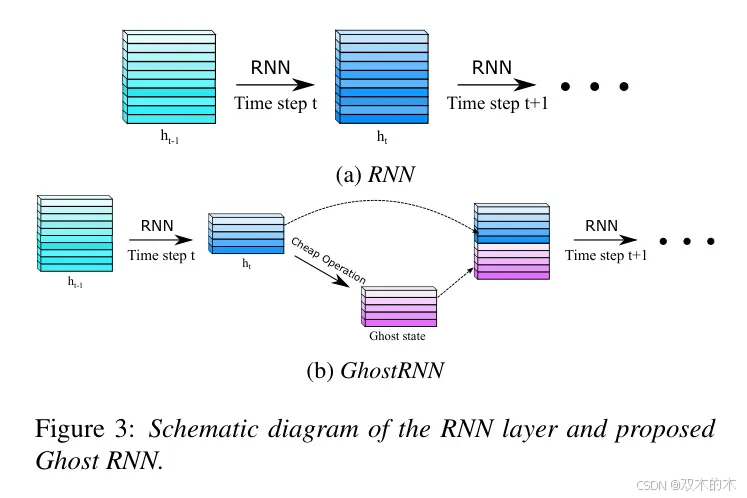
受到上述观察的启发,作者提出GhostRNN以减少隐藏状态中的冗余,从而构建高效RNN模型。特别是,部分RNN隐藏状态由基本的RNN模型生成,作为内在状态。接下来,实现了一些廉价的操作,包括简单的线性变换和激活函数,以基于内在状态生成鬼状态。然后,将鬼状态与内在状态连接起来,作为前一个时间步的完整特征表示,并传递到下一个时间步进行进一步计算。与基本的RNN矩阵乘法相比,作者的廉价操作具有更少的FLOPs和参数,因此GhostRNN模型的计算和内存成本显著降低。
针对KWS和SE任务进行了实验,以检验作者提出的方法的有效性。实验结果表明,作者的方法在Google语音指令数据集上实现了0.1%的准确率提升,同时将 Baseline 模型的参数压缩了40%。在SE任务中,作者的方法在约40%的压缩率下,将SDR和Si-SDR提高了约0.1dB。
2 Proposed Method
在本节中,作者将详细介绍提出的GhostRNN,并在模型压缩方面进行说明。为方便起见,作者使用GRU来说明GhostRNN的定义。作者的方法可以应用于其他RNNs,例如LSTM。
Rnn
作为一类模型结构,循环神经网络(RNNs)利用隐状态来存储和利用上下文信息[17],包括广为人知的变体门控循环单元(GRUs)和长短时记忆单元(LSTMs)。作为最常用的RNN模型之一,GRU是LSTM的一种简化版本,其定义如下:

GhostRNN
针对降低隐状态冗余,作者提出的GhostRNN利用极低成本的变换从内在状态生成幽灵状态。
关于隐藏状态冗余性的观察如第一部分所述,以往的研究主要关注模型压缩时门矩阵数量减少,而很少关注隐藏状态的冗余性,这也对有效减少模型参数数量至关重要。因此,本节将对隐藏状态的冗余性进行全面研究。首先,采用PCA贡献率作为评估指标。将时间上的隐藏状态向量累积视为特征图,对其进行奇异值分解。根据结果,只需要大约一半的奇异值,特征图可以达到99%的PCA贡献率,表明仅用一半的隐藏状态,就可以构建完整的特征信息。此外,如图1所示,作者将不同时间步长下不同维度的隐藏状态向量累积作为状态组件state_i,并计算不同组件之间的余弦相似度。结果表明,某些组件的余弦相似度接近1。图1(a)中显示了一组具有高度相关趋势的组件,表明GRU的隐藏状态存在冗余性。另一方面,如图1(b)所示,特定组件之间的余弦相似度接近0,表明这些状态组件几乎正交,因此是必要且不可替代的。因此,保留必要的状态组件并消除冗余组件是压缩RNN模型的直接而实际的方法。
基于上述结果和分析,作者提出GhostRNN模块,该模块基于内在状态构建鬼状态,如图3所示,可以定义如下:

Analysis on the Number of Parameters and Computational Complexity
普通GRU和作者所提出的GhostRNN的参数数量可以按照以下方式计算:
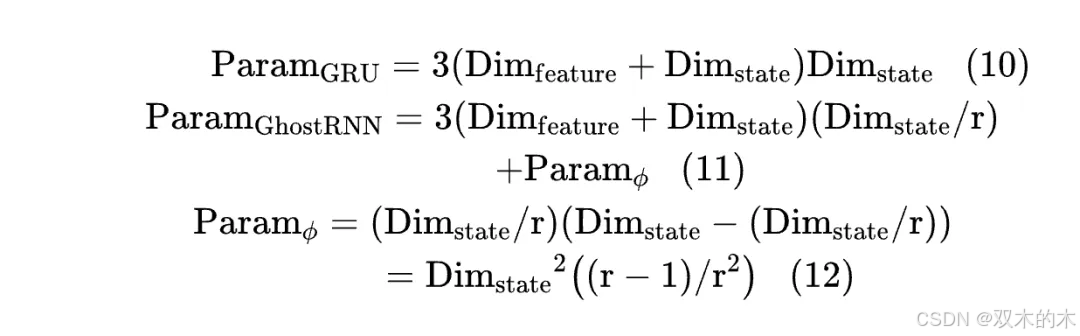
其中, r表示完整状态与内在状态的比例。如 Eqs (10) 至 (11) 所示,GhostRNN 的输出隐状态维度被比例 r与常规 GRU 中的相比。尽管应用了一个额外的廉价操作模块,由线性层组成,根据 Eq. (12),廉价操作模块的参数数量远小于 GRU 模型。因此,GhostRNN 的总参数数量将压缩为 r倍。
如果廉价操作模块采用其他计算方法(如无需参数的常规线性变换)构建,压缩比可以达到 r。至于计算复杂度,由于 GRU 中的所有矩阵都是线性层,GRU 的计算复杂度几乎与参数数量成正比。因此,GhostRNN 的计算复杂度也将通过相同因子 r 降低。
3 Experiments
进行了两项实验以评估作者方法的有效性:KWS和SE。
Datasets
在作者的实验中,使用了Google语音指令数据集v0.02 [18],该数据集包含成千上万的1秒音频样本,分为30个类别。遵循先前的研究[3, 19],作者选择了12个类别:“是”,“否”,“上”,“下”,“左”,“右”,“开”,“关”,“停”,“走”,“静音”和“未知”。作者分别使用这些样本的36,923, 4,445和4,890个样本进行训练,验证和测试。作者使用10维Mel-频率倒谱系数(MFCC)作为语音特征,窗口长度为40 ms,窗口平移为20 ms,导致每个语音样本的特征图大小为49x10。此外,作者采用了类似于[3]中建议的增加背景噪声和随机平移等数据增强技术,以提高模型的鲁棒性。
为了评估作者的方法在SE任务上的性能,作者使用了LibriMix数据集[20],该数据集通过将来自LibriSpeech[21]的干净语音与来自WHA!数据集[22]的噪声相结合来生成嘈杂的语音片段。作者使用了训练-360数据集的16kHz版本,共有50,800个训练样本,3000个验证样本和3,000个测试样本,总共234小时的数据。作者实现了与Asteroid[23]中相同的数据预处理。
Settings and Evaluation Metrics
在KWS的训练过程中,作者使用了标准交叉熵损失和Adam优化器,批量大小为100。作者采用了一个逐步降低的学习率策略,初始学习率为5e-4,步长设置为[10,000,20,000]。所有模型都从零开始训练,总共进行了30,000次迭代,并使用准确性指标[3]进行评估。为了确保作者的结果的可靠性,每个模型都使用相同配置进行了三次训练,并报告了平均实验结果。
在SE的训练过程中,作者使用了置换不变损失和ADAM优化器,并将批量大小设置为12(对于DCRNN [5])和32(对于GRU-TasNet [24])。所有实验中均应用了学习率衰减策略和早停策略。初始学习率设置为0.001,并应用了1e-5的重量衰减。在滤波器方面,作者的设置与[23]中描述的一致。在评估时,作者使用了5种指标,即信号与噪声比(SDR)、SDR改进(SDRi)、尺度不变信号与噪声比(Si-SDR)、Si-SDR改进(Si-SDRi)和短时客观可懂性(STOI)[26]。
Baselines
KWS model
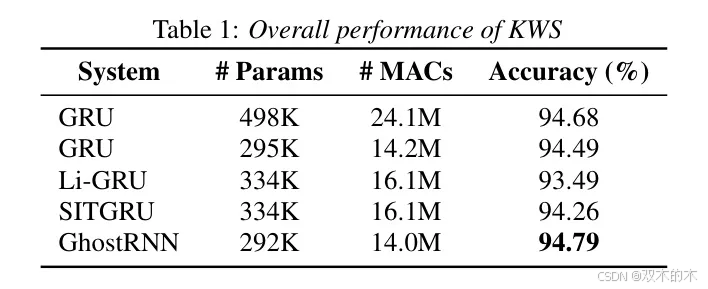
表1中展示了,作为KWS[3]的基准模型,使用了大小约为500k的GRU模型,以及大小约为295k的另一个GRU模型,同时实现了Li-GRU[12]和SITGRU[14]进行比较。
SE models
为了比较SE任务,作者选择了两种模型作为 Baseline 模型。第一种是DCCRN [5],该模型主要基于卷积层,并辅以RNN层。第二种是GRU-TasNet [24],其中RNN是主要模块。以下是对它们简要的介绍:
DCCRN。该模型包括三个主要部分:卷积编码器、转置卷积解码器和RNN模块。在作者的实验中,作者选择了DCCRN-CL [5]模型,并替换了LSTM,其中选择了128和80两个大小的隐单元来构建不同大小的 Baseline 模型。
GRU-TasNet. 该模型由时域音频分离网络(Time-domain Audio Separation Network)优化而来,该网络包含三个部分:一个一维卷积编码器(1-D convolutional encoder)、一个一维反卷积解码器(1-D deconvolutional decoder)以及一个深度长短期记忆分离模块(Deep LSTM separation module) [24]。在作者的实验中,长短期记忆(LSTM)被替换为门控循环单元(GRU)。作者设计了四种具有不同大小的 Baseline 模型,这些模型的差异在于GRU的隐藏层大小:512、384、192和136。
Results on KWS
表1呈现了实验结果和模型参数。作者提出的GhostRNN模型与两个 Baseline 500k GRU和300k GRU进行了比较,以及两种其他模型压缩方法:Li-GRU [12]和SITGRU [14]。结果表明,作者提出的GhostRNN模型约减少了40%的参数,在准确率上相对于500k GRU模型提高了约0.1%,同时也超过了稍微参数更多的Li-GRU和SIT-GRU模型,这表明了作者提出的GhostRNN的有效性。
Results on SE
表2展示了DCCRN和DCCRN_Ghost128在libririx1数据集上的性能。结果表明,通过在DCCRN模型中的GRU层中剪枝隐藏层大小以实现模型压缩,SDR和Si-SDR指标降低了约0.1 dB。相比之下,当作者应用所提出的GhostRNN压缩方法和压缩约10%的参数时,SDR和Si-SDR指标仅降低了约0.05 dB。这些发现明显证明了GhostRNN的有效性。
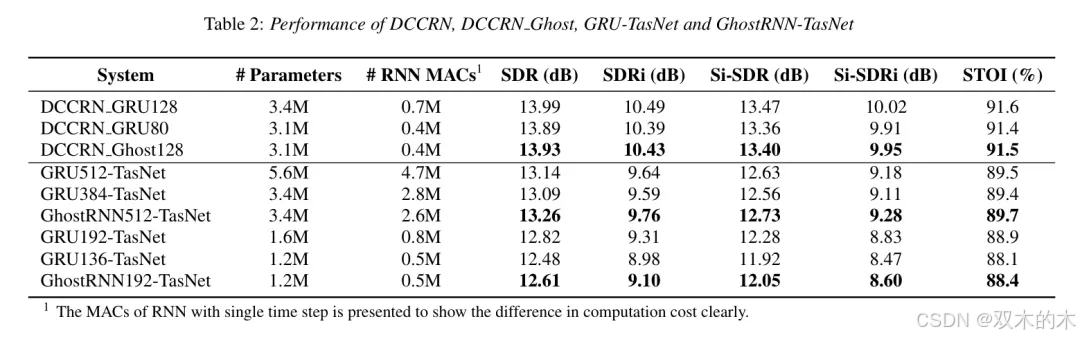
表2展示了GRU-TasNet和GhostRNN-TasNet在libririx1数据集上的性能。指标显示,当模型从GRU512-TasNet压缩到GRU384-TasNet时,SDR和Si-SDR略有降低,表明GRU512-TasNet存在冗余参数。在这种情况下,GhostRNN方法在SDR和Si-SDR上实现了0.1 dB以上的性能提升,且参数比GRU512-TasNet减少了40%。然而,当模型进一步压缩到1.6M(GRU192-TasNet)时,性能明显下降,表明模型冗余度较低。在这种情况下,GhostRNN192相对于GRU136-TasNet在SDR和Si-SDR上大约有0.13 dB的优势。总之,GhostRNN是一种有效的RNN模型压缩方法。
4 Conclusions
在本文中,作者提出了GhostRNN,用于基于RNN模型压缩的观察到隐藏状态的冗余性。在作者的GhostRNN中,给定内在的隐藏状态,应用了极低成本的 Transformer Layer 来生成鬼状态,这显著减少了基础GRU模型的参数数量和计算成本,但实现了竞争力的性能。实验结果表明,作者的方法在压缩 Baseline 模型参数的同时,在Google语音命令数据集上实现了0.1%的准确性改进。在SE任务中,作者的方法将SDR和Si-SDR提高了约0.1 dB,压缩率约为40%。
此外,作者的方法在SDR和其他评估指标方面,与具有相同参数数量的基础GRU模型相比,大约提高了0.13 dB。总体而言,提出的GhostRNN是一种简单而有效的RNN模型压缩方法。在未来的工作中,值得研究将GhostRNN扩展到其他RNN结构,如LSTM,并进一步探索新的鬼状态生成方法,以实现模型计算复杂性和性能之间的更好平衡。此外,作者计划探索将GhostRNN与其他现有RNN压缩技术结合的潜在好处。
5 参考文献
[0]. GhostRNN: Reducing State Redundancy in RNN with Cheap Operations.
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









