






本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:如何在 Docker 容器中使用 GPU
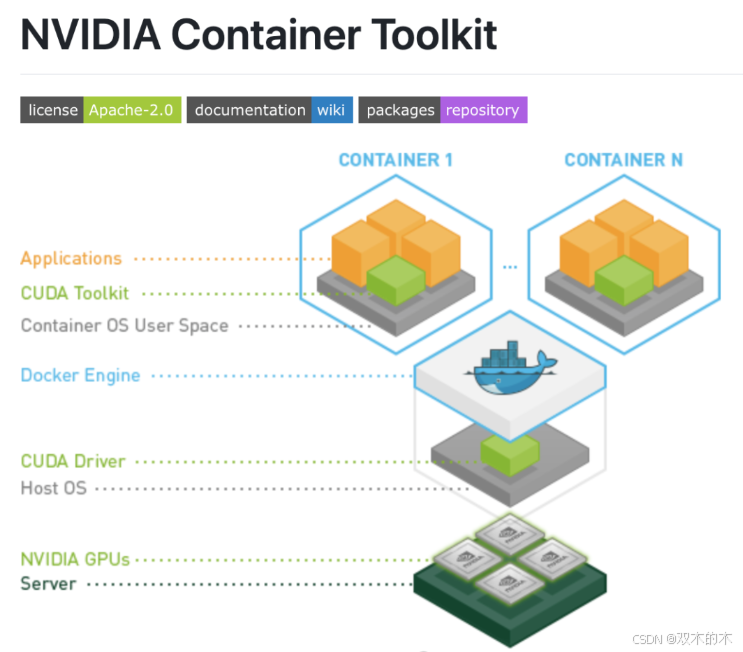
在计算机上配置 GPU 可能非常困难。配置步骤会根据计算机的操作系统和计算机所具有的 NVIDIA GPU 类型而变化。更难的是,当 Docker 启动容器时,它几乎需要从头开始。
有些东西(比如 CPU 驱动程序)是预先为您配置的,但当您运行 docker 容器时,GPU 并未配置。幸运的是,您找到了这里解释的解决方案。它被称为NVIDIA Container Toolkit。
在本文中,我们将介绍在 Docker 容器内访问机器 GPU 所需的步骤。
Docker GPU 错误
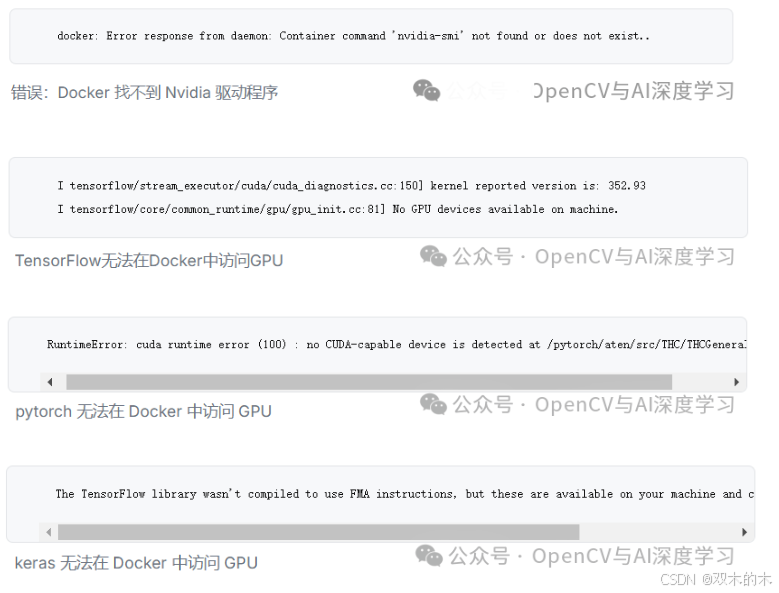
当您尝试在 Docker 中运行需要 GPU 的容器时,您可能会收到以下列出的任何错误。这些错误表明 Docker 和 Docker Compose 无法连接到您的 GPU。
以下是您可能会遇到的一些错误:
让 Docker 使用你的 GPU
如果您遇到任何类似于上述列出的错误,以下步骤将帮助您解决它们。让我们逐步讨论您需要做什么才能允许 Docker 使用您的 GPU。
在基础机器上安装 NVIDIA GPU 驱动程序
首先,您必须在基础机器上安装 NVIDIA GPU 驱动程序,然后才能在 Docker 中使用 GPU。
如前所述,由于操作系统、NVIDIA GPU 和 NVIDIA GPU 驱动程序的分布过多,这可能很困难。您将运行的确切命令将根据这些参数而有所不同。
如果您使用 NVIDIA TAO 工具包,我们有关于如何构建和部署自定义模型的指南。
以下资源可能有助于您配置计算机上的 GPU:
NVIDIA 官方工具包文档
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html?ref=blog.roboflow.com在 Ubuntu 上安装 NVIDIA 驱动程序指南
https://linuxconfig.org/how-to-install-the-nvidia-drivers-on-ubuntu-18-04-bionic-beaver-linux?ref=blog.roboflow.com从命令行安装 NVIDIA 驱动程序
https://www.cyberciti.biz/faq/ubuntu-linux-install-nvidia-driver-latest-proprietary-driver/?ref=blog.roboflow.com完成这些步骤后,运行nvidia-smi命令。如果命令列出了有关 GPU 的信息,则表明您的 GPU 已被计算机成功识别。您可能会看到如下输出:
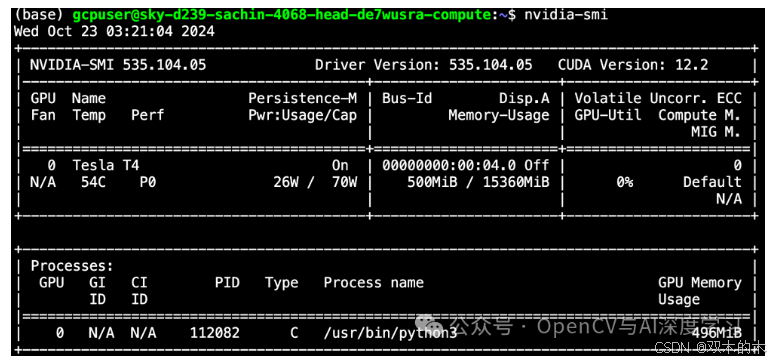
现在我们知道 NVIDIA GPU 驱动程序已安装在基础机器上,我们可以将层次更深地移到 Docker 容器。
使用 NVIDIA 工具包向 Docker 公开 GPU 驱动程序
最好的方法是使用NVIDIA Container Toolkit。NVIDIA Container Toolkit 是一个 Docker 镜像,它支持自动识别基础机器上的 GPU 驱动程序,并在运行时将这些相同的驱动程序传递给 Docker 容器。
如果您能够在基础机器上运行nvidia-smi,那么您也将能够在 Docker 容器中运行它(并且您的所有程序都将能够引用 GPU)。为了使用 NVIDIA Container Toolkit,您可以将 NVIDIA Container Toolkit 映像拉到 Dockerfile 的顶部,如下所示:
FROM nvidia/cuda:12.6.2-devel-ubuntu22.04CMD nvidia-smi
在该 Dockerfile 中,我们导入了适用于 10.2 驱动程序的 NVIDIA Container Toolkit 映像,然后我们指定了在运行容器时要运行的命令来检查驱动程序。您可能希望在新版本发布时更新基础映像版本(在本例中为 10.2)。
现在我们使用以下命令来构建图像:
docker build . -t nvidia-test
现在,我们可以使用以下命令从映像运行容器:
docker run --gpus all nvidia-test请记住,我们需要 --gpus all 标志,否则 GPU 将不会暴露给正在运行的容器。
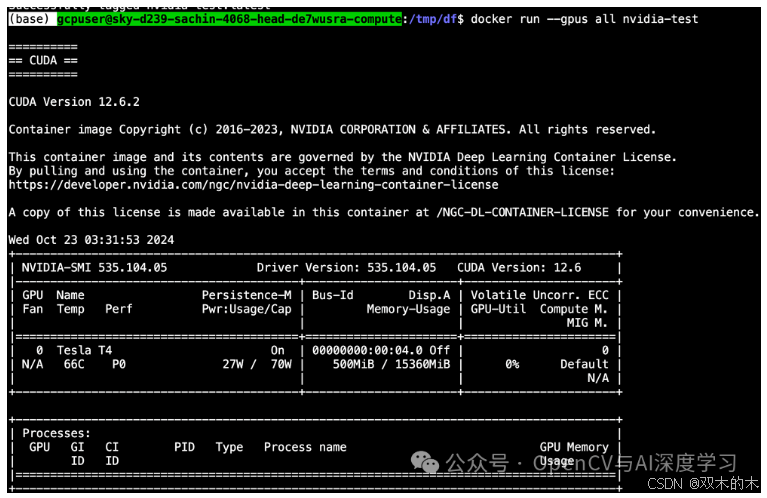
从此状态开始,您可以开发您的应用程序。在我们的示例中,我们使用 NVIDIA Container Toolkit 为实验性深度学习框架提供支持。完整构建的 Dockerfile 的布局可能如下所示(其中 /app/ 包含所有 python 文件):
FROM nvidia/cuda:12.6.2-devel-ubuntu22.04CMD nvidia-smi#set up environmentRUN apt-get update && apt-get install --no-install-recommends --no-install-suggests -y curlRUN apt-get install unzipRUN apt-get -y install python3RUN apt-get -y install python3-pipCOPY app/requirements_verbose.txt /app/requirements_verbose.txtRUN pip3 install -r /app/requirements_verbose.txt#copies the applicaiton from local path to container pathCOPY app/ /app/WORKDIR /appENV NUM_EPOCHS=10ENV MODEL_TYPE='EfficientDet'ENV DATASET_LINK='HIDDEN'ENV TRAIN_TIME_SEC=100CMD ["python3", "train_and_eval.py"]
上述 Docker 容器使用基础机器的 GPU 根据规格训练和评估深度学习模型。
通过暴力破解的方式将 GPU 驱动程序暴露给 Docker
为了让 Docker 识别 GPU,我们需要让它知道 GPU 驱动程序。我们在镜像创建过程中执行此操作。此时我们运行一系列命令来配置 Docker 容器将在其中运行的环境。
确保 Docker 能够识别 GPU 驱动程序的“强力方法”是包含您在基础机器上配置 GPU 时使用的相同命令。当 Docker 构建映像时,这些命令将运行并在映像上安装 GPU 驱动程序,一切应该都很好。
暴力方法也有缺点。每次重建docker镜像时,你都必须重新安装该镜像。这会减慢你的开发速度。
此外,如果您决定将 Docker 映像从当前机器转移到具有不同 GPU、操作系统的新机器上,或者您想要新的驱动程序 - 您将必须每次为每台机器重新编写此步骤。
这有点违背了构建 Docker 镜像的目的。此外,您可能不记得在本地机器上安装驱动程序的命令,因此您又得重新在 Docker 中配置 GPU。
暴力破解方法在你的 Dockerfile 中看起来像这样:
FROM ubuntu:22.04MAINTAINER Regan <http://stackoverflow.com/questions/25185405/using-gpu-from-a-docker-container>RUN apt-get update && apt-get install -y build-essentialRUN apt-get --purge remove -y nvidia*ADD ./Downloads/nvidia_installers /tmp/nvidia > Get the install files you used to install CUDA and the NVIDIA drivers on your hostRUN /tmp/nvidia/NVIDIA-Linux-x86_64-331.62.run -s -N --no-kernel-module > Install the driver.RUN rm -rf /tmp/selfgz7 > For some reason the driver installer left temp files when used during a docker build (i don't have any explanation why) and the CUDA installer will fail if there still there so we delete them.RUN /tmp/nvidia/cuda-linux64-rel-6.0.37-18176142.run -noprompt > CUDA driver installer.RUN /tmp/nvidia/cuda-samples-linux-6.0.37-18176142.run -noprompt -cudaprefix=/usr/local/cuda-6.0 > CUDA samples comment if you don't want them.RUN export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64 > Add CUDA library into your PATHRUN touch /etc/ld.so.conf.d/cuda.conf > Update the ld.so.conf.d directoryRUN rm -rf /temp/* > Delete installer files.
此方法要求您将 NVIDIA 驱动程序放在本地文件夹中。您可以将上例中的“./Downloads”文件夹替换为您保存 GPU 驱动程序的目录。
如果我的 Dockerfile 中需要不同的基础镜像怎么办?
假设您一直依赖 Dockerfile 中的不同基础映像。那么,您应该考虑通过使用Docker 多阶段构建将 NVIDIA Container Toolkit 与当前拥有的基础映像一起使用。
现在您已将映像写入并通过基础机器的 GPU 驱动程序,您将能够将映像从当前机器中提取出来并将其部署到您想要的任何实例上运行的容器中。
指标的力量:了解正在运行的 Docker 容器中的 GPU 利用率
监控 GPU 的性能指标对于优化应用程序和最大限度地发挥硬件的价值至关重要。GPU 利用率、内存使用率和热特性等指标可为您提供宝贵的见解,让您了解容器化工作负载如何高效利用 GPU 资源。这些见解可帮助您识别瓶颈、微调应用程序配置并最终降低成本。
介绍DCGM:GPU监控套件
NVIDIA 的数据中心 GPU 管理器(DCGM) 是一套功能强大的工具,专为管理和监控集群环境中的 NVIDIA 数据中心 GPU 而设计。它提供以下全面功能:
-
-
主动的健康监测可以在潜在问题影响您的工作负载之前主动识别它们。
-
详细的诊断可以对 GPU 性能提供深入的分析。
-
系统警报会通知您与 GPU 相关的任何关键事件。
-
运行示例 GPU 推理容器
现在,让我们将理论付诸实践。我们将使用Roboflow 的 GPU 推理服务器 docker镜像作为示例 GPU 工作负载,并使用 DCGM、Prometheus 和 Grafana 监控其 GPU 使用情况。以下是如何拉取和运行 Roboflow GPU 推理容器:
docker pull roboflow/roboflow-inference-server-gpudocker run -it --net=host --gpus all roboflow/roboflow-inference-server-gpu:latest
使用 Prometheus、Grafana 和 DCGM 进行统一监控
为了简化 GPU 指标收集和可视化,我们将利用一个集成 Prometheus、Grafana 和 DCGM 的优秀开源项目。该项目提供了一个预配置的 Docker Compose 文件,用于设置所有必要的组件:
-
-
DCGM 导出器:此容器从您的 NVIDIA GPU 中抓取原始指标。
-
Prometheus:该容器作为收集和存储指标的中央存储库。
-
Grafana:该容器提供了一个用户友好的界面,用于可视化和分析您收集的指标。
-
提供的 Docker Compose 文件定义了每个组件的配置,包括资源分配、网络设置和环境变量。通过部署此 Docker Compose 堆栈,您将立即拥有一个完整的监控系统。
要获取监控堆栈设置:
git@github.com:hongshibao/gpu-monitoring-docker-compose.gitdocker compose up
这应该会启动 DCGM 导出器、Prometheus 和 Grafana pod。
Docker Compose文件的解释:
存储库提供的Docker Compose 文件 compose.yaml定义了各种服务和配置:
服务:
dcgm_exporter:此服务运行 DCGM 导出器容器来收集 GPU 指标。它利用nvidia设备驱动程序并请求访问所有具有 GPU 功能的可用 GPU。
prometheus:此服务运行 Prometheus 容器来存储和提供收集到的指标。您可以自定义存储参数,例如保留时间。
grafana:此服务运行 Grafana 容器以可视化指标。您可以配置用户凭据以进行访问控制。
卷:
为 Prometheus 数据和 Grafana 数据定义了持久卷,以确保即使在容器重启后数据仍然持久。
网络:
gpu_metrics创建一个名为的自定义网络,以促进服务之间的通信。
打开http://localhost:3000后将显示 Grafana 界面。您应该会看到如下所示的仪表板:
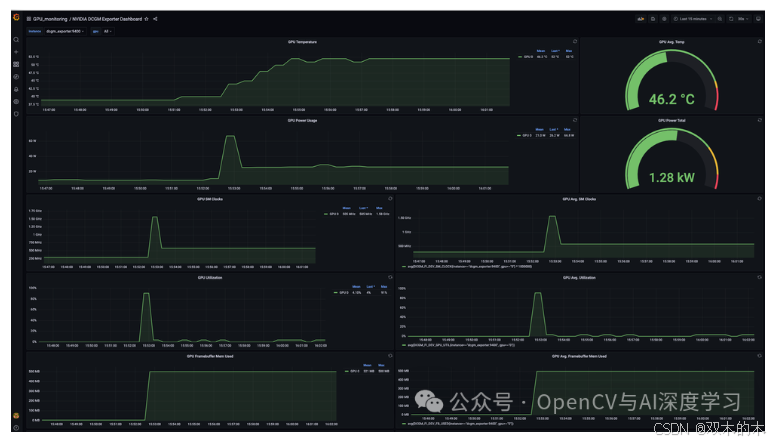
通过遵循这些步骤并利用指标监控的强大功能,您可以确保您的 Docker 容器有效利用 NVIDIA GPU。根据从 GPU 指标中收集到的见解对您的应用程序进行微调将提高性能并节省成本。请记住,优化资源利用率是最大限度提高对强大 GPU 硬件的投资回报的关键。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 4872
4872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









