






本文来源公众号“GiantPandaCV”,仅用于学术分享,侵权删,干货满满。
原文链接:FasterTransformer Decoding 源码分析(五)-AddBiasResidualLayerNorm介绍
GiantPandaCV | FasterTransformer Decoding 源码分析(一)-整体框架介绍-优快云博客
GiantPandaCV | FasterTransformer Decoding 源码分析(二)-Decoder框架介绍-优快云博客
GiantPandaCV | FasterTransformer Decoding 源码分析(三)-LayerNorm介绍-优快云博客
GiantPandaCV | FasterTransformer Decoding 源码分析(四)-SelfAttention实现介绍-优快云博客
作者丨进击的Killua
来源丨https://zhuanlan.zhihu.com/p/670656687
编辑丨GiantPandaCV
本文是FasterTransformer Decoding 源码分析的第五篇,主要介绍FasterTransformer中融合OP AddBiasResidualLayerNorm是如何实现及优化的。融合OP包含了LayerNorm、AddBias和AddResidual三个算子,其中LayerNorm的实现和分析已经在进击的Killua:FasterTransformer Decoding 源码分析(三)-LayerNorm介绍这篇文章中详解过,剩下两个操作非常简单,本质上就是两个矩阵求和,所以这篇文章内容会很短,主要是介绍融合的这个思想。
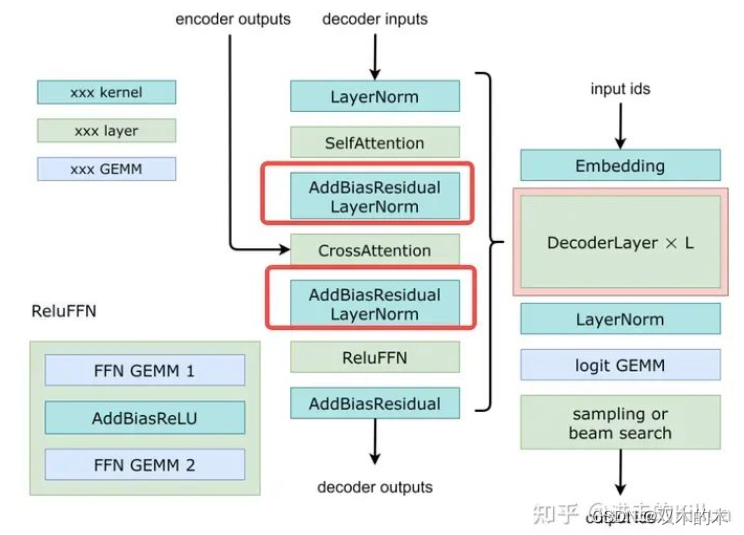
1 背景知识
三个OP分别是LayerNorm、AddResidual和AddBias,下面分别简单介绍下他们的出处。
1.1 LayerNorm
LayerNorm(层归一化)是一种用于深度神经网络中的归一化技术。它可以对网络中的每个神经元的输出进行归一化,使得网络中每一层的输出都具有相似的分布,公式为如下所示。
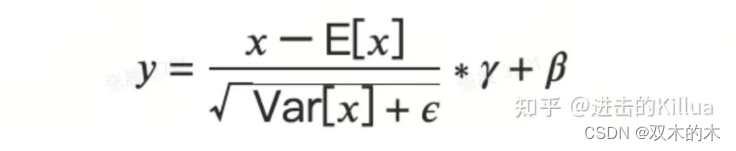
LayerNorm 计算公式
1.2 AddResidual
残差设计源自于resnet,是将模块处理前的输入和模块处理后的输出进行相加再作为输出进入后续流程中。引入残差块可以解决深度神经网络训练过程中的梯度消失和梯度爆炸问题,让模型可以更深,收敛更快,可以通过文章7.6. 残差网络(ResNet) - 动手学深度学习 2.0.0 documentation学习。
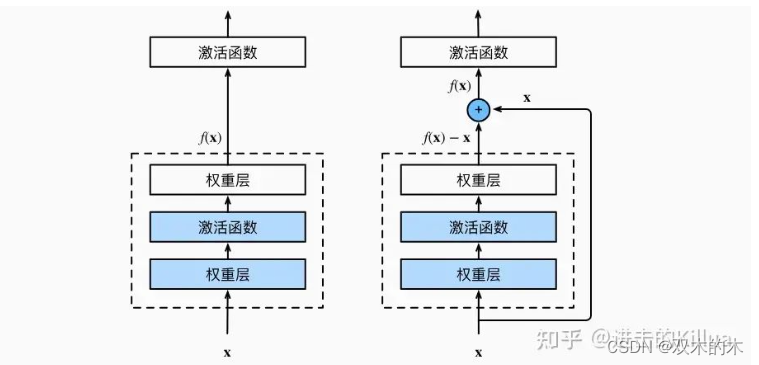
添加残差
1.3 AddBias
添加偏置项来自于线性变换,线性变换的前半部是矩阵乘法,通常会通过cuBLAS中的gemm函数完成,而后半部分和偏置项求和往往会单独调用kernel运算,这里和前两个OP进行了融合,减少了kernel调用。
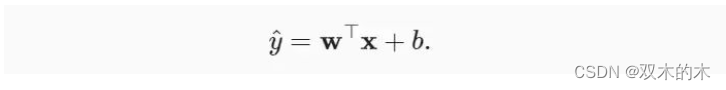
线性变换
2 源码分析
2.1 入口函数
函数签名如下,这里把三个OP需要的输入和参数都包含进去了。
template<typename T>
void invokeGeneralAddBiasResidualPreLayerNorm(T* output, // 添加bias和residual输出
T* norm_output, // 整体正则化输出
const T* input, // 输入
const T* residual1, // 残差1
const T* residual2, // 残差2
const T* gamma,
const T* beta,
const T* bias, // 偏置
const float layernorm_eps,
int m, // block数量
int n, // 处理的每一行数据元素个数
const float* scale_inter,
const float* scale_out,
float* scale,
float* dynamic_scale,
const int int8_mode,
cudaStream_t stream,
int opt_version = 2);2.2 调用kernel
这里gridSize等于一批处理的数据个数,即一个block处理输入的一行数据,符合并行处理的思路。blockSize是一份数据的维度和1024的较小值,可以理解,大多数CUDA设备一个block支持的最大线程数就是1024,所以这里要min处理下。这里还有个trick就是维度如果不是32的倍数就也设置为1024,主要是为了最大化利用warp(32个线程)特性来处理数据。动态量化的部分我们先跳过,接下来就是调用函数进入到kernel实现部分。
dim3 grid(m);
dim3 block(min(n, 1024));
/* For general cases, n is equal to hidden_units, e.g., 512/1024.
Since we have warp shuffle inside the code, block.x % 32 should be 0.
*/
block.x = (block.x + 31) / 32 * 32;
size_t maxbytes = n * sizeof(T);
if (residual_num == 1) {
if (maxbytes >= (48 << 10)) {
check_cuda_error(cudaFuncSetAttribute(
generalAddBiasResidualLayerNorm<T, 1>, cudaFuncAttributeMaxDynamicSharedMemorySize, maxbytes));
}
generalAddBiasResidualLayerNorm<T, 1><<<grid, block, maxbytes, stream>>>(input,
residual1,
residual2,
gamma,
beta,
bias,
output,
norm_output,
layernorm_eps,
m,
n,
scale_inter,
scale_out,
scale,
dynamic_scale,
int8_mode);
}2.3 kernel实现
这里为了代码结构更加清晰先将量化相关的代码先去掉了,整个流程还是比较容易理解,先进行了残差项、输入项和偏置项的求和合并,结果存到共享内存,再通过两次block级别的归约实现了LayerNorm,从而实现了算子融合,详细流程如注释所展示。
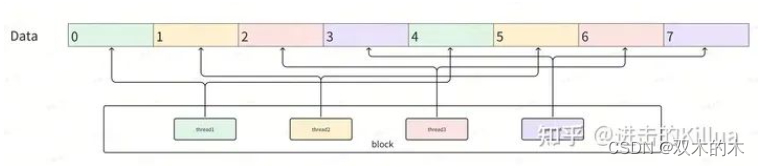
block模型上,一个block处理一行数据(n维度),block中有m个线程,1个线程可能处理1到多个数据中的元素,如下图所示,这里n=8,m=4,所以一个线程需要处理2个数据,反映到代码中就是单个线程对2个元素进行本地三项求和、归约求和和差值平方。
template<typename T, int RESIDUAL_NUM>
__global__ void generalAddBiasResidualLayerNorm(const T* __restrict input,
const T* __restrict residual1,
const T* __restrict residual2,
const T* __restrict gamma,
const T* __restrict beta,
const T* __restrict bias,
T* output,
T* norm_output,
const float layernorm_eps,
int m,
int n,
const float* scale_inter,
const float* scale_out,
const float* scale,
float* dynamic_scale,
const int int8_mode)
{
int tid = threadIdx.x;
// NOTE: float shmem may exceed the shared memory limit
// 使用共享内存存储中间变量
extern __shared__ __align__(sizeof(float)) char _shmem[];
T* shmem = reinterpret_cast<T*>(_shmem);
// 定义共享内存变量:均值和方差
__shared__ float s_mean;
__shared__ float s_variance;
float mean = 0.0f;
float variance = 0.0f;
float local_sum = 0.0f;
// blockDim跨度的遍历,block中线程数小于数据维度数时一个线程可能处理多个element
for (int i = tid; i < n; i += blockDim.x) {
float local_out = 0.0f;
// 提取残差项
if (RESIDUAL_NUM == 1) {
local_out = (float)(ldg(&residual1[blockIdx.x * n + i]));
}
else if (RESIDUAL_NUM == 2) {
local_out = (float)(ldg(&residual1[blockIdx.x * n + i])) + float(ldg(&residual2[blockIdx.x * n + i]));
}
// 残差项和输入项合并
local_out += (float)(input[blockIdx.x * n + i]);
// 添加bias项
if (bias != nullptr) {
local_out += (float)(ldg(&bias[i]));
}
// 共享内存记录该项求和结果
shmem[i] = (T)local_out;
// 同时记录到输出内存地址中
output[blockIdx.x * n + i] = (T)local_out;
// 累计到本地线程求和变量中
local_sum += local_out;
}
// 在block范围内对线程粒度的local_sum进行归约求和
mean = blockReduceSum(local_sum);
// 通过block中的0号线程进行均值
if (threadIdx.x == 0) {
s_mean = mean / n;
}
// 确保共享内存变量s_mean在block范围同步
__syncthreads();
// blockDim跨度的遍历计算方差
float local_var_sum = 0.0f;
for (int i = tid; i < n; i += blockDim.x) {
float diff = (float)(output[blockIdx.x * n + i]) - s_mean;
local_var_sum += diff * diff;
}
// 在block范围内对线程粒度的local_var_sum进行归约求和
variance = blockReduceSum(local_var_sum);
// 通过block中的0号线程求标准差
if (threadIdx.x == 0) {
s_variance = rsqrtf(variance / n + layernorm_eps);
}
__syncthreads();
Scalar_T abs_max = 1e-6f;
// blockDim跨度的遍历计算normalize并输出到全局内存中
for (int i = tid; i < n; i += blockDim.x) {
float beta_val = (beta == nullptr) ? 0.0f : (float)(ldg(&beta[i]));
const float val = ((((float)shmem[i] - s_mean) * s_variance) * (float)(ldg(&gamma[i])) + beta_val);
norm_output[blockIdx.x * n + i] = (T)val;
}
}3 总结
本文对融合算子AddBiasResidualLayerNorm进行了详细的介绍,融合的计算操作在kernel实现中显得非常自然,没有什么trick的设计,这类融合主要是需要先对计算流程做分析,观察哪些算子可以融合。事实上很多在逻辑上是上下游且是elementwise的算子都可以融合,甚至融合后合并到下游算子中减少kernel调用次数,本文就是一个比较好的例子。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1841
1841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









