






本文来源公众号“GiantPandaCV”,仅用于学术分享,侵权删,干货满满。
原文链接:一文理解RetNet
0 前言
paper:https://arxiv.org/pdf/2307.08621.pdf
code:https://github.com/microsoft/un
微软研究院最近提出了一个新的 LLM 自回归基础架构 Retentive Networks (RetNet)[1,4],该架构相对于 Transformer 架构的优势是同时具备:训练可并行、推理成本低和良好的性能,打破了“不可能三角”。
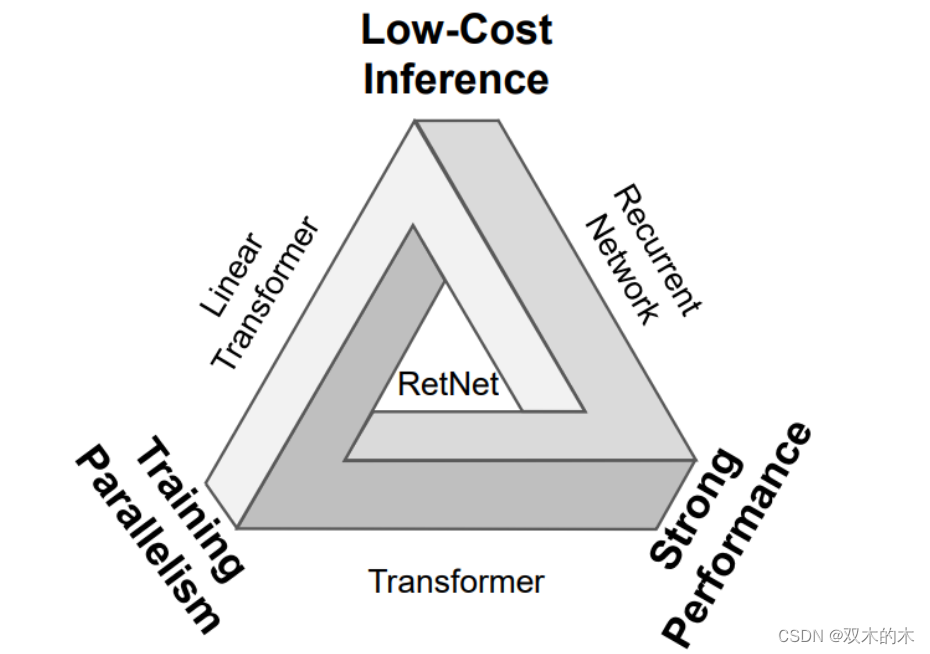
论文中给出一个很形象的示意图,RetNet 在正中间表示同时具备三个优点,而其他的架构 Linear Transformer、Recurrent Network 和 Transformer 都只能同时具备其中两个优点。
实验数据也显示,在语言建模任务上:
- RetNet 可以达到与 Transformer 相当的困惑度(perplexity)
- 推理速度达8.4倍
- 内存占用减少70%
- 具有良好的扩展性
并且当模型大小大于一定规模时,RetNet 的表现会优于 Transformer。
接下来看一下论文给出的 RetNet 和 Transformer 的对比实验结果:
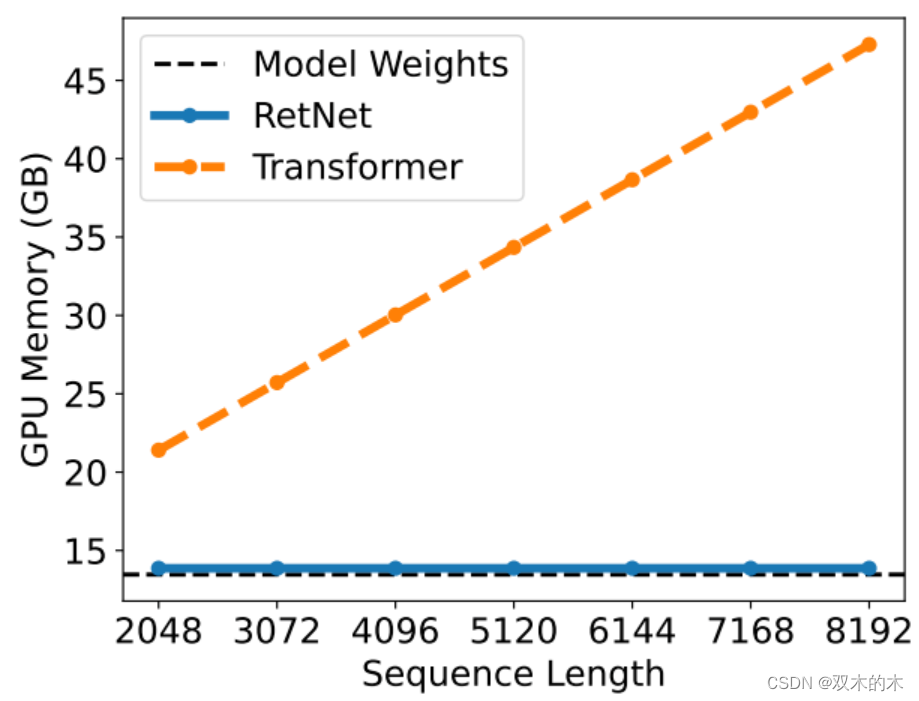
当输入序列长度增加的时候,RetNet 的 GPU 显存占用一直是稳定的和权值差不多,而 Transformer 则是和输入长度成正比。
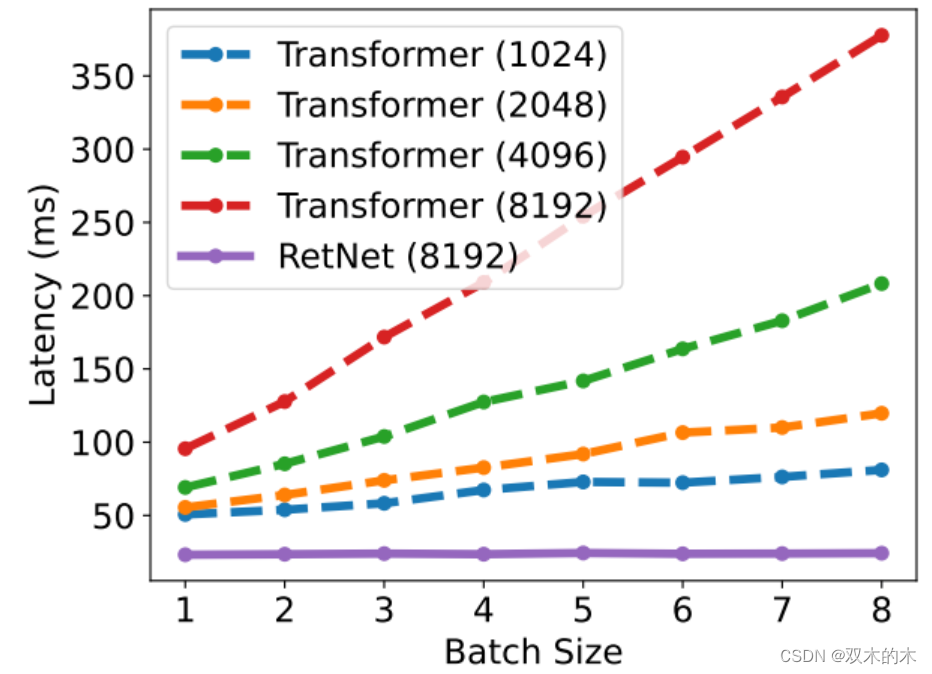
首先看红色线和紫色线,都是输入长度在 8192 下,RetNet 和 Transformer 推理延时的对比。
可以看到当 batch size 增加的时候, RetNet 的推理延时也还是很稳定,而 Transformer 的推理延时则是和 batch size 成正比。
而 Transformer 即使是输入长度缩小到 1024 ,推理延时也还是比 RetNet 要高。
1 RetNet 架构解读
RetNet 架构和 Transformer 类似,也是堆叠 L 层同样的模块,每个模块内部包含两个子模块:一个 multi-scale retention(MSR)和一个 feed-forward network (FFN)。
下面详细解读一下这个 retention 子模块。

2 Retention 机制
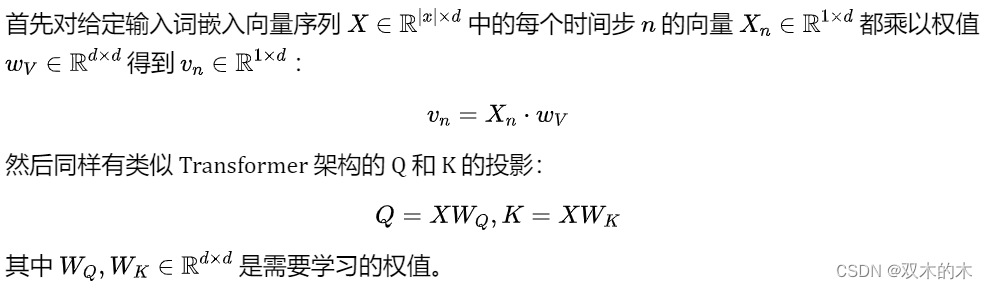



关于复数向量相乘可以参考文章:
一文看懂 LLaMA 中的旋转式位置编码(Rotary Position Embedding)



2.1 Retention 的训练并行表示

2.2 Retention 的推理循环表示

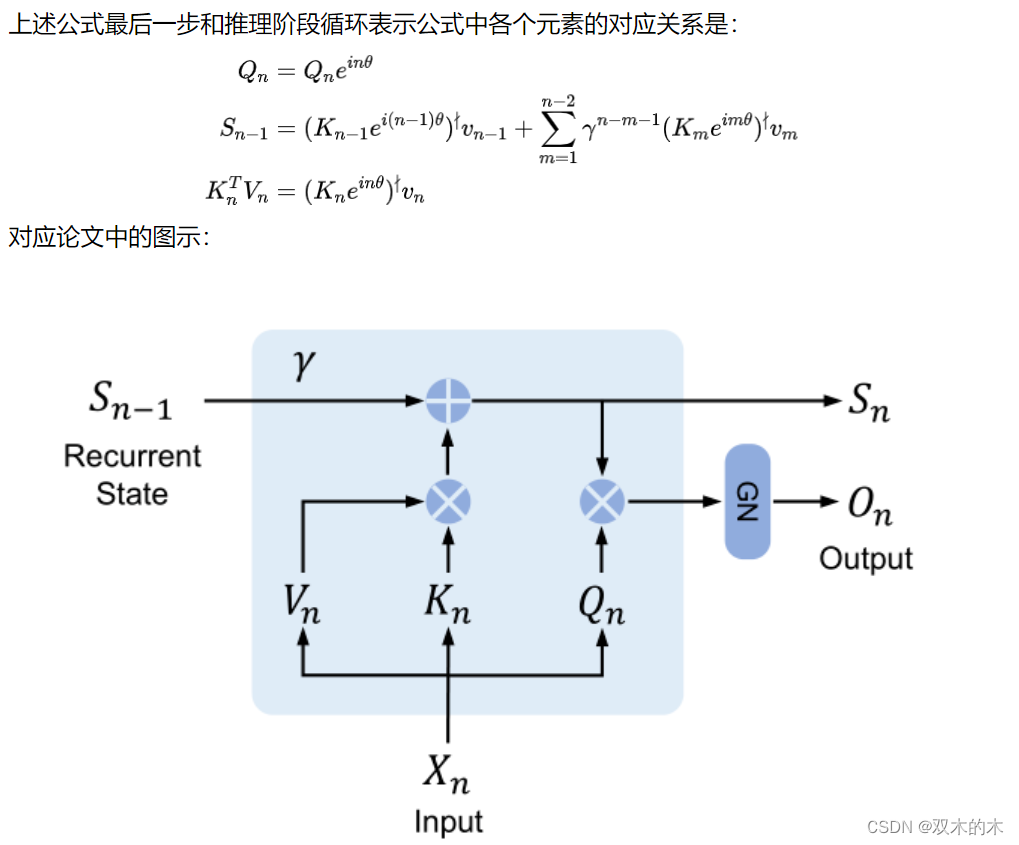

3 Gated Multi-Scale Retention

4 参考资料
-
[1] https://arxiv.org/pdf/2307.08621.pdf
-
[2] https://en.wikipedia.org/wiki/Euler's_formula
-
[3] https://en.wikipedia.org/wiki/List_of_trigonometric_identities
-
[4] https://github.com/microsoft/torchscale/blob/main/torchscale/architecture/retnet.py
THE END!
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









