






本文来源公众号“江大白”,仅用于学术分享,侵权删,干货满满。
原文链接:基于Pytorch框架,从零实现Transformer模型实战
以下文章来源于微信公众号:小喵学AI
作者:郭小喵
链接:https://mp.weixin.qq.com/s/XFniIyQcrxambld5KmXr6Q
本文仅用于学术分享,如有侵权,请联系后台作删文处理
导读
Transformer作为深度学习进入大模型时代的标志性模型,其强大的性能被广泛应用于各个领域。本文基于Pytorch框架从零开始搭建Transformer模型,不仅有详细的脚本说明,还涵盖了丰富了模型分析,希望对大家有帮助。
2017年Google在论文《Attention is All You Need》中提出了Transformer模型,并成功应用到NLP领域。该模型完全基于自注意力机制Attention mechanism实现,弥补了传统的RNN模型的不足。
本文笔者将详解使用Pytorch从零开始逐步实现Transformer模型。
0 回顾
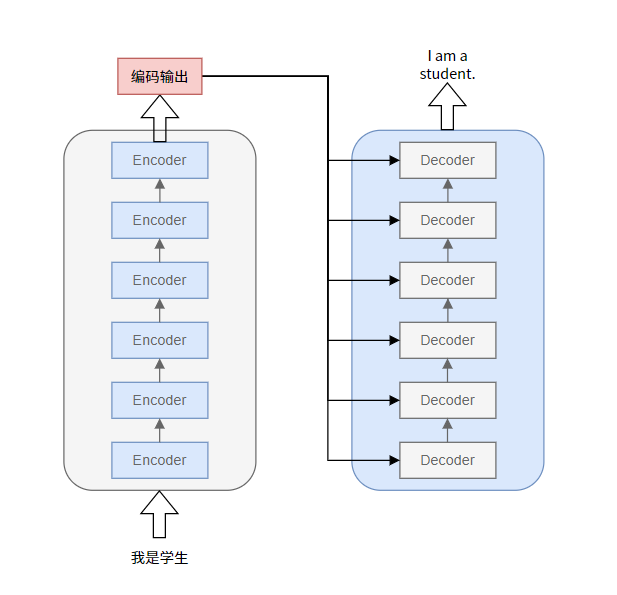
首先我们先回顾一下Transformer原理。宏观层面,Transformer可以看成是一个黑箱操作的序列到序列(seq2seq)模型。例如,在机器翻译中,输入一种语言,经Transformer输出翻译后的另一种语言。

拆开这个黑箱,可以看到模型本质就是一个Encoders-Decoders结构。
-
每个Encoders中分别由6层Encoder组成。(所有Encoder结构完全相同,但是训练参数不同,每个参数是独立训练的,循环执行6次Encode,而不是只训练了一个Encoder然后复制5份)。
-
Decoders同理。
-
这里每个Encoders包含6层Encoder,只是论文中Nx=6,实际可以自定义。
Transformer整体架构如下图所示。
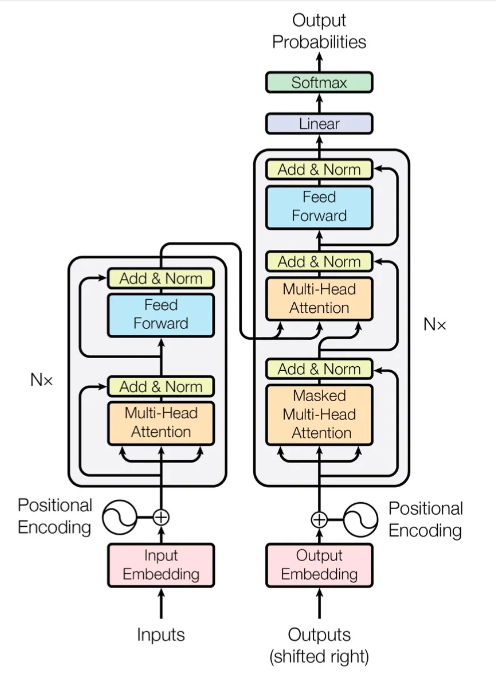
其中,
-
编码端:经过词向量层(Input Embedding)和位置编码层(Positional Encoding),得到最终输入,流经自注意力层(Multi-Head Attention)、残差和层归一化(Add&Norm)、前馈神经网络层(Feed Forward)、残差和层归一化(Add&Norm),得到编码端的输出(后续会和解码端进行交互)。
-
解码端:经过词向量层(Output Embedding)和位置编码层(Positional Encoding),得到最终输入,流经掩码自注意力层(Masked Multi-Head Attention,把当前词之后的词全部mask掉)、残差和层归一化(Add&Norm)、交互注意力层(Multi-Head Attention,把编码端的输出和解码端的信息进行交互,Q矩阵来自解码端,K、V矩阵来自编码端的输出)、残差和层归一化(Add&Norm)、前馈神经网络层(Feed Forward)、残差和层归一化(Add&Norm),得到解码端的输出。
注:编码端和解码端的输入不一定等长。
1 Encoder
下面还是以机器翻译("我是学生"->"I am a student")为例说明。
对于上图中,整个模型的输入即为"我是学生",目标是将其翻译为"I am a student",但是计算机是无法识别"我是学生"的,需要将其转化为二进制形式,再送入模型。
将中文转换为计算机可以识别的向量通常有两种方法:
-
One Hot编码:形成高维向量,对于中文来说,汉字的数量就是向量的维度,然后是哪个字就将对应位置变为1,其它位置变为0,以此来表示一句话。
-
Embedding词嵌入:通过网络进行训练或者通过一些训练好的模型将其转化成连续性的向量。
一般来说第二种方法使用较多,因为第一种有几个缺点,第一个就是每个字都是相互独立的,缺少语义联系信息,第二就是汉字数量太多,会导致生成的维度过大,占用系统内存。
1.1 输入Input
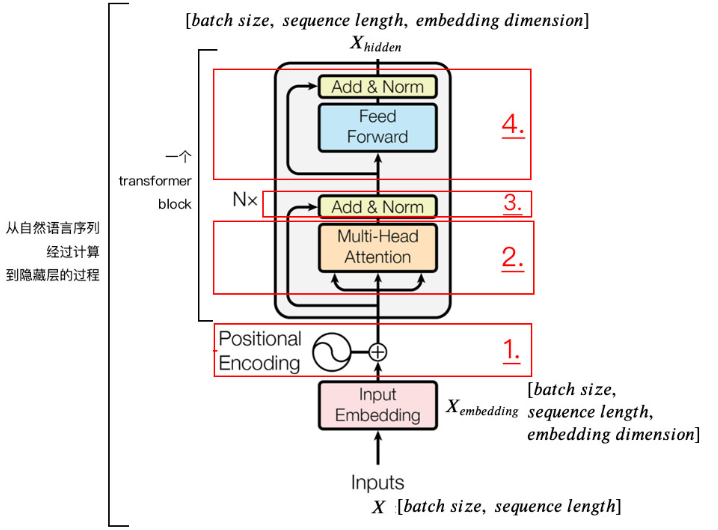
输入Inputs维度是[batch size,sequence length],经Word2Vec,转换为计算机可以识别的Input Embedding,论文中每个词对应一个512维度的向量,维度是[batch_size,sequence_length,embedding_dimmension]。batch size指的是句子数,sequence length指的是输入的句子中最长的句子的字数,embedding_dimmension是词向量长度。
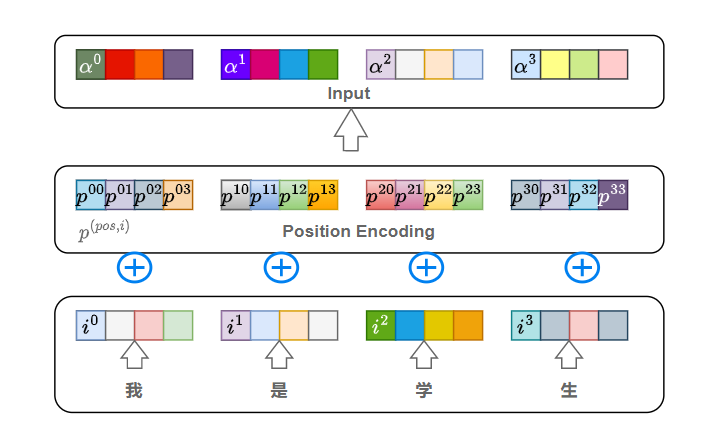
如上图所示,以机器翻译("我是学生"->"I am a student")为例,首先对输入的文字进行Word Embedding处理,每个字(词)用一个连续型向量表示(这里定义的是4维向量),称为词向量。这样一个句子,也就是嵌入后的输入向量input Embedding就可以用一个矩阵表示(4*4维,序列长度为4,每个字用4维向量表示)。input Embedding加上位置信息得到编码器的输入矩阵。
「为什么需要在input Embedding加上位置信息?」 与RNN相比,RNN是一个字一个字输入,自然可以保留每个字的顺序关系信息,而Transformer使用的是自注意力机制来提取信息,一个句子中的每个字/词是并行计算,虽然处理每个字的时候考虑到了所有字对其的影响,但是并没有考虑到各个字相互之间的位置信息,也就是上下文。所以需要引入位置信息。
Transformer中使用Positional Encoding表示每个字/词的位置信息。定义如下:
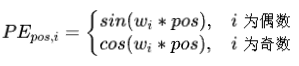

这样就即可实现让自注意力机制考虑词的顺序,同时又可以输入所有的词。
1.2 输入Input代码实现
1.2.1「Word Embedding」
Word Embedding在Pytorch中通常用nn.Embedding实现。
class Embeddings(nn.Module):
"""
类的初始化
:param d_model: 词向量维度,512
:param vocab: 当前语言的词表大小
"""
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
# 调用nn.Embedding预定义层,获得实例化词嵌入对象self.lut
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model #表示词向量维度
def forward(self, x):
"""
Embedding层的前向传播
参数x:输入给模型的单词文本通过此表映射后的one-hot向量
x传给self.lut,得到形状为(batch_size, sequence_length, d_model)的张量,与self.d_model相乘,
以保持不同维度间的方差一致性,及在训练过程中稳定梯度
"""
return self.lut(x) * math.sqrt(self.d_model)1.2.2「Positional Encoding」
class PositionalEncoding(nn.Module):
"""实现Positional Encoding功能"""
def __init__(self, d_model, dropout=0.1, max_len=5000):
"""
位置编码器的初始化函数
:param d_model: 词向量的维度,与输入序列的特征维度相同,512
:param dropout: 置零比率
:param max_len: 句子最大长度,5000
"""
super(PositionalEncoding, self).__init__()
# 初始化一个nn.Dropout层,设置给定的dropout比例
self.dropout = nn.Dropout(p=dropout)
# 初始化一个位置编码矩阵
# (5000,512)矩阵,保持每个位置的位置编码,一共5000个位置,每个位置用一个512维度向量来表示其位置编码
pe = torch.zeros(max_len, d_model)
# 偶数和奇数在公式上有一个共同部分,使用log函数把次方拿下来,方便计算
# position表示的是字词在句子中的索引,如max_len是128,那么索引就是从0,1,2,...,127
# 论文中d_model是512,2i符号中i从0取到255,那么2i对应取值就是0,2,4...510
# (5000) -> (5000,1)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 计算用于控制正余弦的系数,确保不同频率成分在d_model维空间内均匀分布
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 根据位置和div_term计算正弦和余弦值,分别赋值给pe的偶数列和奇数列
pe[:, 0::2] = torch.sin(position * div_term) # 从0开始到最后面,补长为2,其实代表的就是偶数位置
pe[:, 1::2] = torch.cos(position * div_term) # 从1开始到最后面,补长为2,其实代表的就是奇数位置
# 上面代码获取之后得到的pe:[max_len * d_model]
# 下面这个代码之后得到的pe形状是:[1 * max_len * d_model]
# 多增加1维,是为了适应batch_size
# (5000, 512) -> (1, 5000, 512)
pe = pe.unsqueeze(0)
# 将计算好的位置编码矩阵注册为模块缓冲区(buffer),这意味着它将成为模块的一部分并随模型保存与加载,但不会被视为模型参数参与反向传播
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [seq_len, batch_size, d_model] 经过词向量的输入
"""
x = x + self.pe[:, :x.size(1)].clone().detach() # 经过词向量的输入与位置编码相加
# Dropout层会按照设定的比例随机“丢弃”(置零)一部分位置编码与词向量相加后的元素,
# 以此引入正则化效果,防止模型过拟合
return self.dropout(x)1.3 自注意力机制(Self Attention Mechanism)
注意力机制,顾名思义,就是我们对某件事或某个人或物的关注重点。举个生活中的例子,当我们阅读一篇文章时,并非每个词都会被同等重视,我们会更关注那些关键的、与上下文紧密相关的词语,而非每个停顿或者辅助词。
对于机器来说其实就是赋予多少权重(比如0-1之间的小数),越重要的地方或者越相关的地方赋予的权重越高。
注意力机制的实现思想是先计算第1个字与句中每个字的注意力分数(包括第1个字),再用求得的注意力分数与对应字的信息相乘,并相加,得到的结果就是第1个字与句子中所有字的加权和,第2个字、第3个字...以此类推。
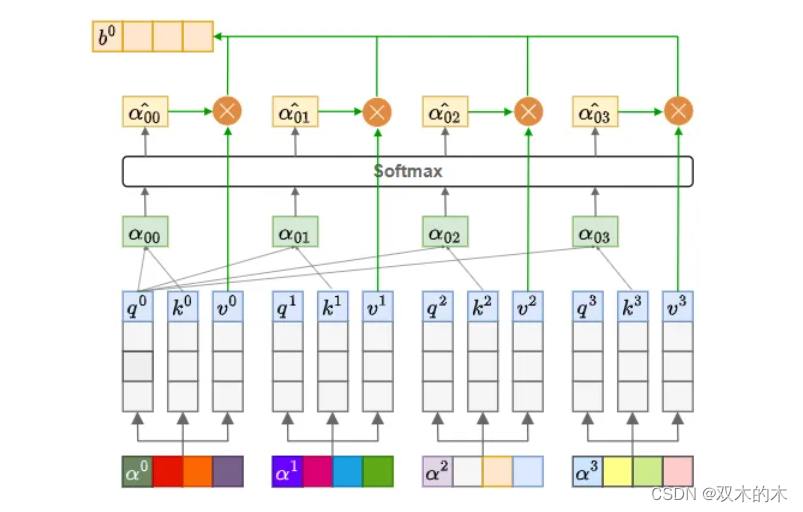

以此类推。
如上所述,即为注意力机制的思想。
实际中计算机为了加速计算,通常采用矩阵计算思想。
「矩阵计算思想」
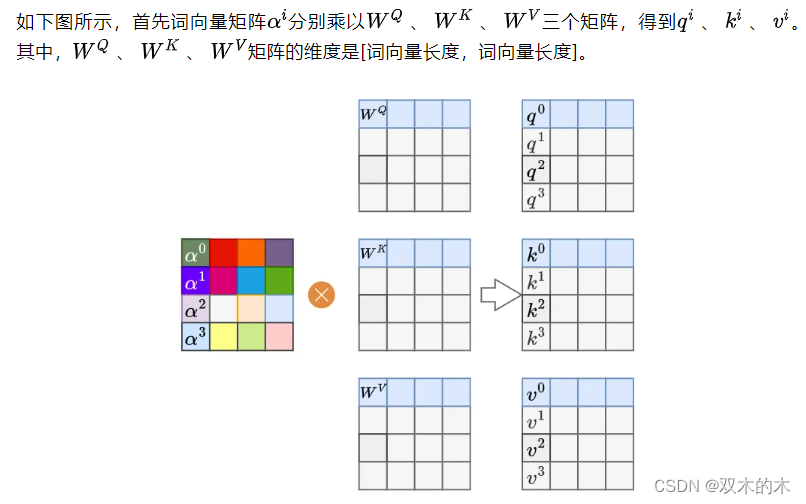
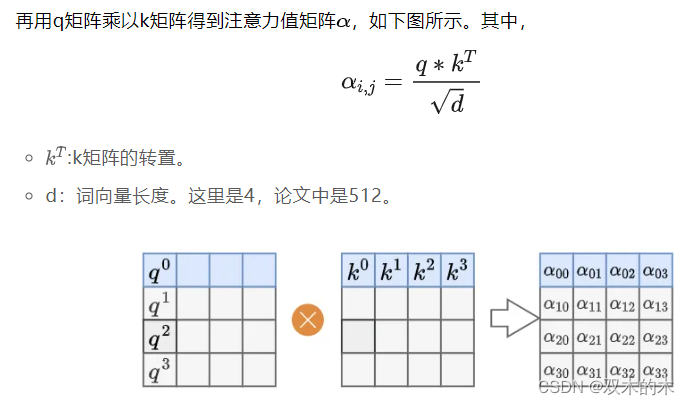


1.4 自注意力机制代码实现
class ScaledDotProductAttention(nn.Module):
""" Scaled Dot-Product Attention """
def __init__(self, scale_factor, dropout=0.0):
super().__init__()
self.scale_factor = scale_factor
#dropout用于防止过拟合,在前向传播的过程中,让某个神经元的激活值以一定的概率停止工作
self.dropout = nn.Dropout(dropout)
def forward(self, q, k, v, mask=None):
# batch_size: 批量大小
# len_q,len_k,len_v: 序列长度 在这里他们都相等
# n_head: 多头注意力,论文中默认为8
# d_k,d_v: k v 的dim(维度) 默认都是64
# 此时q的shape为(batch_size, n_head, len_q, d_k) (batch_size, 8, len_q, 64)
# 此时k的shape为(batch_size, n_head, len_k, d_k) (batch_size, 8, len_k, 64)
# 此时v的shape为(batch_size, n_head, len_k, d_v) (batch_size, 8, len_k, 64)
# q先除以self.scale_factor,再乘以k的转置(交换最后两个维度(这样才可以进行矩阵相乘))。
# attn的shape为(batch_size, n_head, len_q, len_k)
attn = torch.matmul(q / self.scale_factor, k.transpose(2, 3))
if mask is not None:
"""
用-1e9代替0 -1e9是一个很大的负数 经过softmax之后接近0
# 其一:去除掉各种padding在训练过程中的影响
# 其二,将输入进行遮盖,避免decoder看到后面要预测的东西。(只用在decoder中)
"""
scores = scores.masked_fill(mask == 0, -1e9)
# 先在attn的最后一个维度做softmax 再dropout 得到注意力分数
attn = self.dropout(torch.softmax(attn, dim=-1))
# 最后attn与v矩阵相乘
# output的shape为(batch_size, 8, len_q, 64)
output = torch.matmul(attn, v)
# 返回 output和注意力分数
return output, attn1.5 多头注意力机制(Multi-Head Attention )
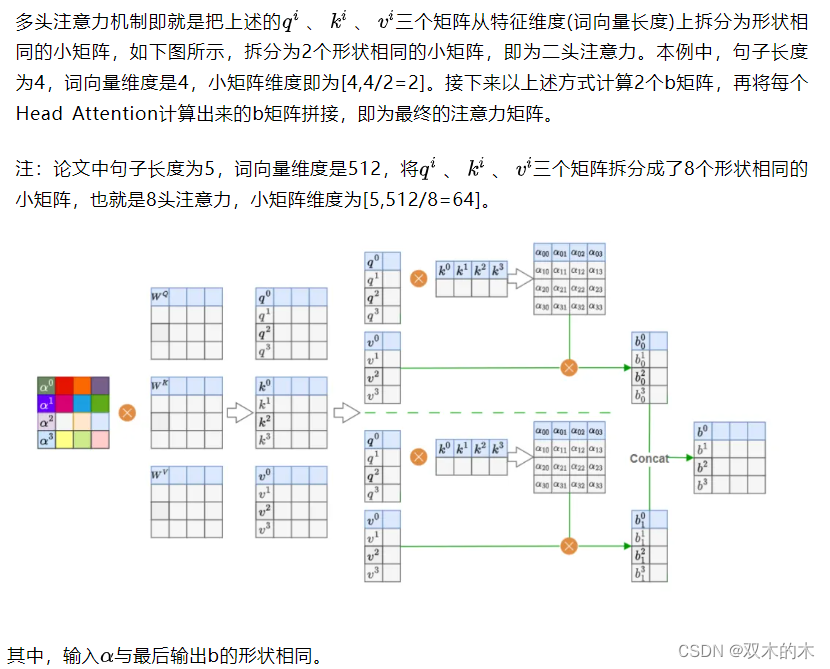
1.6 多头注意力机制代码实现
class MultiHeadAttention(nn.Module):
""" Multi-Head Attention module """
def __init__(self, n_head, d_model, d_k, d_v, dropout=0.1):
# 论文中这里的n_head, d_model, d_k, d_v分别默认为8, 512, 64, 64
'''
# q k v先经过不同的线性层,再用ScaledDotProductAttention,最后再经过一个线性层
'''
super().__init__()
self.n_head = n_head
self.d_k = d_k
self.d_v = d_v
self.w_qs = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_ks = nn.Linear(d_model, n_head * d_k, bias=False)
self.w_vs = nn.Linear(d_model, n_head * d_v, bias=False)
self.fc = nn.Linear(n_head * d_v, d_model, bias=False)
self.attention = ScaledDotProductAttention(scale_factor=d_k ** 0.5)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(d_model, eps=1e-6) # 默认对最后一个维度初始化
def forward(self, q, k, v, mask=None):
# q, k, v初次输入为含位置信息的嵌入矩阵X,由于要堆叠N次,后面的输入则是上个多头的输出
# q, k, v:batch_size * seq_num * d_model
d_k, d_v, n_head = self.d_k, self.d_v, self.n_head
# len_q, len_k, len_v 为输入的序列长度
# batch_size为batch_size
batch_size, len_q, len_k, len_v = q.size(0), q.size(1), k.size(1), v.size(1)
# 用作残差连接
residual = q
# Pass through the pre-attention projection: b x lq x (n*dv)
# Separate different heads: b x lq x n x dv
# q k v 分别经过一个线性层再改变维度
# 由(batch_size, len_q, n_head*d_k) => (batch_size, len_q, n_head, d_k)
# (batch_size, len_q, 8*64) => (batch_size, len_q, 8, 64)
q = self.layer_norm(q)
k = self.layer_norm(k)
v = self.layer_norm(v)
# 与q,k,v相关矩阵相乘,得到相应的q,k,v向量,d_model=n_head * d_k
q = self.w_qs(q).view(batch_size, len_q, n_head, d_k)
k = self.w_ks(k).view(batch_size, len_k, n_head, d_k)
v = self.w_vs(v).view(batch_size, len_v, n_head, d_v)
# Transpose for attention dot product: b x n x lq x dv
# 交换维度做attention
# 由(batch_size, len_q, n_head, d_k) => (batch_size, n_head, len_q, d_k)
# (batch_size, len_q, 8, 64) => (batch_size, 8, len_q, 64)
q, k, v = q.transpose(1, 2), k.transpose(1, 2), v.transpose(1, 2)
if mask is not None:
# 为head增加一个维度
mask = mask.unsqueeze(1) # For head axis broadcasting.
# 输出的q为Softmax(QK/d + (1-S)σ)V, attn 为QK/D
q, attn = self.attention(q, k, v, mask=mask)
# Transpose to move the head dimension back: b x lq x n x dv
# Combine the last two dimensions to concatenate all the heads together: b x lq x (n*dv)
# (batch_size, 8, len_k, 64) => (batch_size, len_k, 8, 64) => (batch_size, len_k, 512)
q = q.transpose(1, 2).contiguous().view(batch_size, len_q, -1)
# 经过fc和dropout
q = self.dropout(self.fc(q))
# 残差连接 论文中的Add & Norm中的Add
q += residual
# 论文中的Add & Norm中的Norm
q = self.layer_norm(q)
# q的shape为(batch_size, len_q, 512)
# attn的shape为(batch_size, n_head, len_q, len_k)
return q, attn1.7 Add & Layer normalization
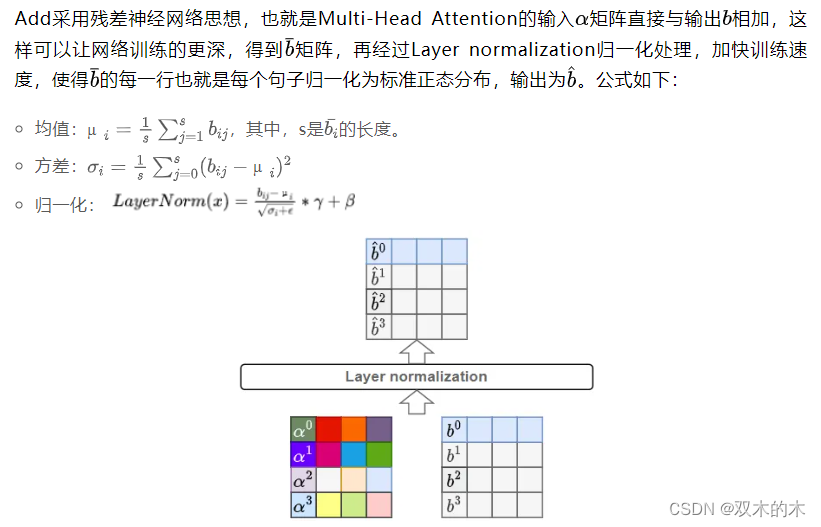
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super().__init__()
# 初始化尺度参数gamma
self.gamma = nn.Parameter(torch.ones(d_model))
# 初始化偏差参数beta
self.beta = nn.Parameter(torch.zeros(d_model))
# 设置一个小常数,防止除0
self.eps = eps
def forward(self, x):
# 计算均值
mean = x.mean(-1, keepdim=True)
# 计算方差,unbiased=False时,方差的计算使用n而不是n-1做分母
var = x.var(-1, unbiased=False, keepdim=True)
# 归一化计算
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.gamma * out + self.beta
return out1.8 Feed Forward前馈神经网络
将Add & Layer normalization输出,经过两个全连接层(第一层的激活函数为 Relu,第二层不使用激活函数),再经过Add & Layer normalization得到最后输出矩阵O。
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False))
def forward(self, inputs): # inputs: [batch_size, seq_len, d_model]
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).cuda()(output + residual) # [batch_size, seq_len, d_model]1.9 Mask掉停用词
Mask句子中没有实际意义的占位符,例如'我 是 学 生 P' ,P对应句子没有实际意义,所以需要被Mask,Encoder_input 和Decoder_input占位符都需要被Mask。
# seq_q: [batch_size, seq_len] ,seq_k: [batch_size, seq_len]
def get_attn_pad_mask(seq_q, seq_k):
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # batch_size x 1 x len_k(=len_q), one is masking
# 扩展成多维度
return pad_attn_mask.expand(batch_size, len_q, len_k) # batch_size x len_q x len_k
1.10 EncoderLayer代码实现
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention() # 多头注意力机制
self.pos_ffn = PoswiseFeedForwardNet() # 前馈神经网络
def forward(self, enc_inputs, enc_self_attn_mask): # enc_inputs: [batch_size, src_len, d_model]
#输入3个enc_inputs分别与W_q、W_k、W_v相乘得到Q、K、V # enc_self_attn_mask: [batch_size, src_len, src_len]
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs, # enc_outputs: [batch_size, src_len, d_model],
enc_self_attn_mask) # attn: [batch_size, n_heads, src_len, src_len]
enc_outputs = self.pos_ffn(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn
1.11 Encoder代码实现
"""
编码器
"""
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) # 把字转换字向量
self.pos_emb = PositionalEncoding(d_model) # 加入位置信息
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs): # enc_inputs: [batch_size, src_len]
# 1. 中文字索引进行Embedding,转换成512维度的字向量
enc_outputs = self.src_emb(enc_inputs) # enc_outputs: [batch_size, src_len, d_model]
# 2. 在字向量上面加上位置信息
enc_outputs = self.pos_emb(enc_outputs) # enc_outputs: [batch_size, src_len, d_model]
# 3. Mask掉句子中的占位符号
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # enc_self_attn_mask: [batch_size, src_len, src_len]
enc_self_attns = []
# 4. 通过6层的encoder(上一层的输出作为下一层的输入)
for layer in self.layers:
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask) # enc_outputs : [batch_size, src_len, d_model],
# enc_self_attn : [batch_size, n_heads, src_len, src_len]
enc_self_attns.append(enc_self_attn)
return enc_outputs, enc_self_attns
2 Decoder
2.1 输入
Decoder的输入是最后一个Encoder block的输出。如下图所示,以中文翻译“我是学生”为例,首先将“我是学生”整个句子输入到Encoder中,得到最后一个Encoder block的输出后,将在Decoder中输入"S I am a student",s表示开始。注意这里,"S I am a student"不会一并输入,而是在T0时刻先输入"S",预测出第一个词"I";再在T1时刻,输入"S"和"I"预测下一个单词"am";同理在T2时刻,输入"S"、"I"和"am",预测出第三个单词"a",依次把整个句子输入到Decoder,预测出"I am a student E"。
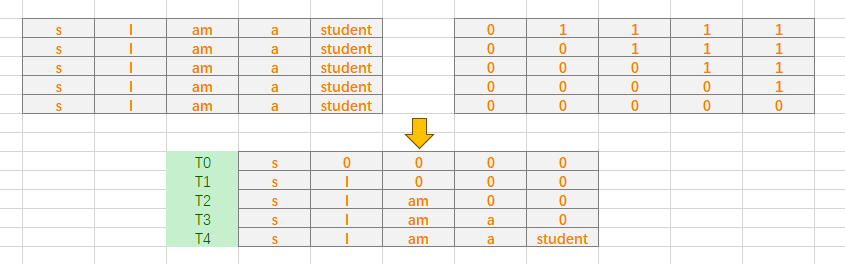
这里采用Mask上三角矩阵掩盖了Decoder的输入,T0、T1、T2、T3、T4即为每个时刻的输入。
def get_attn_subsequence_mask(seq): # seq: [batch_size, tgt_len]
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成上三角矩阵,[batch_size, tgt_len, tgt_len]
subsequence_mask = torch.from_numpy(subsequence_mask).byte() # [batch_size, tgt_len, tgt_len]
return subsequence_mask
2.2 Masked Multi-Head Attention
Masked Multi-Head Attention与Multi-Head Attention类似,只是采用了Mask上三角矩阵,掩盖Decoder的输入。如上所述。
2.3 Decoder的Multi-Head Attention
Decoder的Multi-Head Attention同样和Encoder的Multi-Head Attention结构一样,只是Decoder的Multi-Head Attention中,K、V矩阵来自Encoder的输出,而Q矩阵来自Masked Multi-Head Attention 的输出。
2.4 Decoder的输出预测
Decoder输出矩阵形状是[句子长度,词向量维度],经过nn.Linear全连接层,再通过softmax函数得到每个词的概率,然后选择概率最大的词作为预测结果。
2.5 DecoderLayer代码实现
Decoder两次调用MultiHeadAttention时,第一次调用传入的 Q,K,V 的值是相同的,都等于dec_inputs,第二次调用 Q 矩阵是来自Decoder的输入。K,V 两个矩阵是来自Encoder的输出,等于enc_outputs。
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask): # dec_inputs: [batch_size, tgt_len, d_model]
# enc_outputs: [batch_size, src_len, d_model]
# dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
# dec_enc_attn_mask: [batch_size, tgt_len, src_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs,
dec_inputs, dec_self_attn_mask) # dec_outputs: [batch_size, tgt_len, d_model]
# dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs,
enc_outputs, dec_enc_attn_mask) # dec_outputs: [batch_size, tgt_len, d_model]
# dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs = self.pos_ffn(dec_outputs) # dec_outputs: [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn
2.6 Decoder代码实现
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained(get_sinusoid_encoding_table(tgt_len+1, d_model),freeze=True)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
def forward(self, dec_inputs, enc_inputs, enc_outputs): # dec_inputs : [batch_size x target_len]
# 1. 英文字索引进行Embedding,转换成512维度的字向量,并在字向量上加上位置信息
dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(torch.LongTensor([[5,1,2,3,4]]))
# 2. Mask掉句子中的占位符号
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs)
dec_self_attn_subsequent_mask = get_attn_subsequent_mask(dec_inputs)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequent_mask), 0)
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs)
dec_self_attns, dec_enc_attns = [], []
# 3. 通过6层的decoder(上一层的输出作为下一层的输入)
for layer in self.layers:
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
return dec_outputs, dec_self_attns, dec_enc_attns
3 Transformer代码实现
Trasformer的整体结构,输入数据先通过Encoder,再通过Decoder,最后把输出进行多分类,分类数为英文字典长度,也就是判断每一个字的概率。
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
# 编码器
self.encoder = Encoder()
# 解码器
self.decoder = Decoder()
# 解码器最后的分类器,分类器的输入d_model是解码层每个token的输出维度大小,需要将其转为词表大小,再计算softmax;计算哪个词出现的概率最大
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False)
def forward(self, enc_inputs, dec_inputs):
# Transformer的两个输入,一个是编码器的输入(源序列),一个是解码器的输入(目标序列)
# 其中,enc_inputs的大小应该是 [batch_size, src_len] ; dec_inputs的大小应该是 [batch_size, dec_inputs]
"""
源数据输入到encoder之后得到 enc_outputs, enc_self_attns;
enc_outputs是需要传给decoder的矩阵,表示源数据的表示特征
enc_self_attns表示单词之间的相关性矩阵
"""
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
"""
decoder的输入数据包括三部分:
1. encoder得到的表示特征enc_outputs、
2. 解码器的输入dec_inputs(目标序列)、
3. 以及enc_inputs
"""
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
"""
将decoder的输出映射到词表大小,最后进行softmax输出即可
"""
dec_logits = self.projection(dec_outputs) # dec_logits : [batch_size x src_vocab_size x tgt_vocab_size]
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









